
На рынке доступно более трехсот систем управления базами данных (СУБД), и даже самые популярные исчисляются десятками. Как не сойти с ума при выборе правильной СУБД на старте разработки приложения, особенно если у вас нестандартный проект? Сузить поиск, чтобы подобрать правильное решение, можно в пять этапов, которые мы рассмотрим в этом материале, а в конце поделимся универсальным алгоритмом выбора.
Концептуальное проектирование

Начать следует с создания концептуальной модели данных, исходя из представлений пользователей о предметной области. Для этого описываем схемы хранения данных на высоком уровне абстракции. Важно выявить информационные потребности будущих пользователей и как они соотносятся между собой.
Здесь не нужно описывать все таблицы и их атрибуты, достаточно выделить и описать ключевые сущности. Как правило, для этого используют ER-диаграмму (Entity Relationship). Она позволяет визуализировать сущности и связи между ними.
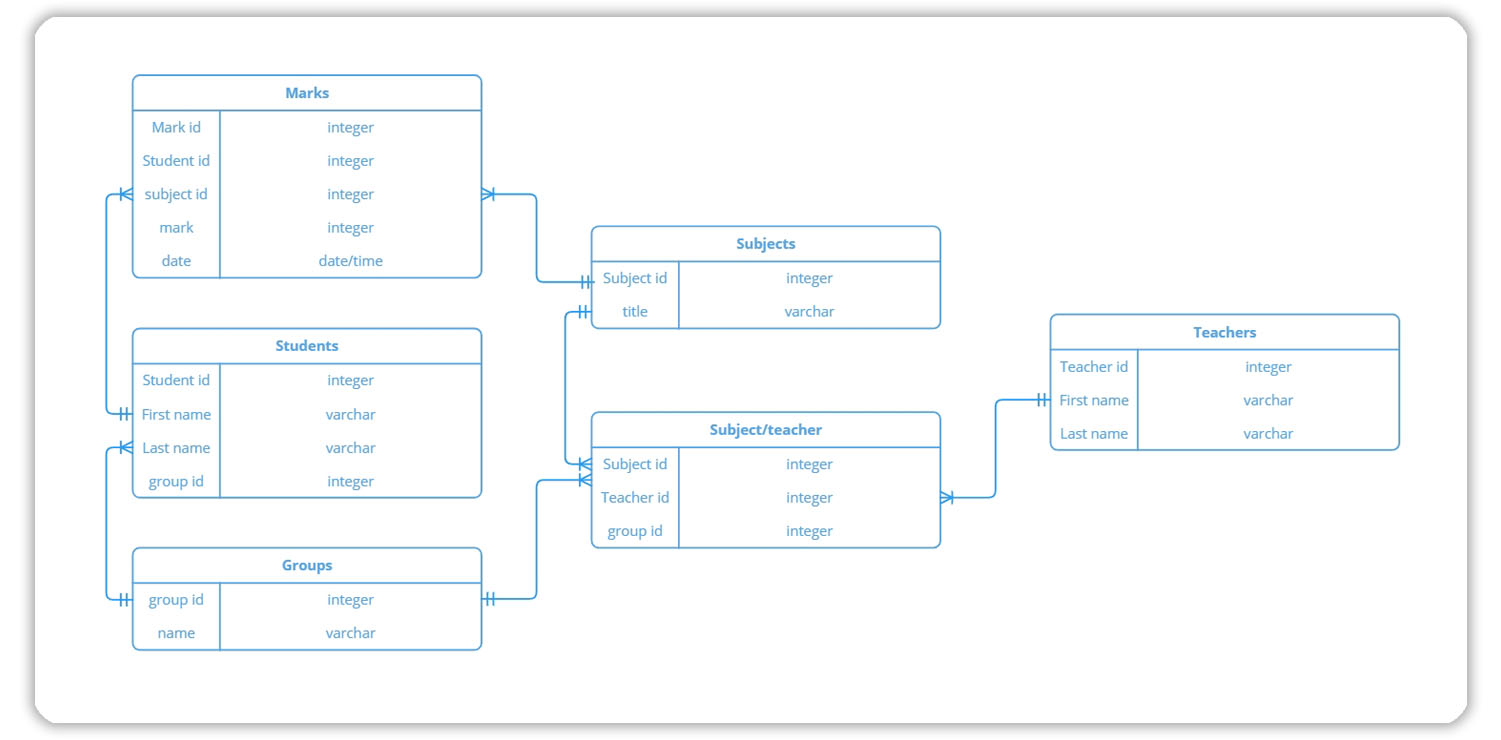
На следующем этапе наличие этих связей поможет нам при принятии решений. При анализе технических требований к БД связи между сущностями играют важную роль.
Технические характеристики
На втором этапе собираем требования к системе хранения данных.
Здесь важно рассмотреть, будут ли частыми запросы на поиск каких-то транзитивных связей между сущностями. Это поможет нам определить, какой тип СУБД подходит — реляционная или нет. В реляционных СУБД с помощью JOIN-методов легко выполнять запросы на транзитивные связи. В документных СУБД, как правило, нет поддержки получения таких связей.
Затем определяем, что приоритетнее — скорость обработки или объем хранимых данных. Выбираем между двумя типами запросов OLTP или OLAP. Online Transaction Processing — это тип обработки данных, который заключается в одновременном выполнении нескольких транзакций. Используется там, где важна скорость выполнения запросов — финансовые операции, отправка сообщений. Online Analytical Processing — система аналитической обработки данных, когда нужно формировать аналитические отчеты, агрегировать данные. Такие запросы выполняются не в режиме реального времени.
Идентификация СУБД по CAP-теореме
На третьем этапе мы должны ответить себе на вопрос, что важнее — легкость масштабирования, доступность, либо целостность данных? В этом нам поможет треугольник CAP, согласно которому распределенная система может одновременно обеспечивать только два из трех свойств. То есть CAP-теорема формализует компромисс между согласованностью и доступностью при наличии разделения. Для начала разберем все три параметра:
C (consistency) — согласованность. Каждое чтение даст вам самую последнюю запись. Это означает, что нет противоречий между данными. К какому бы мы не обратились узлу кластера у нас будут одни и те же данные. Все пользователи видят одни и те же данные одновременно, независимо от узла, к которому они подключены. Когда данные записываются на один узел, они затем реплицируются на другие узлы в системе.
A (availability) — доступность. Каждый узел всегда успешно выполняет запросы на чтение и запись. Ответ на запрос приходит мгновенно. Это означает, что система будет работать, даже если несколько узлов не работают. В отличие от согласованной системы, нет гарантии, что ответ будет самой последней операцией записи.
P (partition tolerance) — устойчивость к разделению. Насколько легко можно добавить новый инстанс к кластеру. Иными словами — масштабируемость системы. Если система терпима к разделам, система не откажет, независимо от того, отбрасываются ли сообщения или задерживаются между узлами внутри системы.
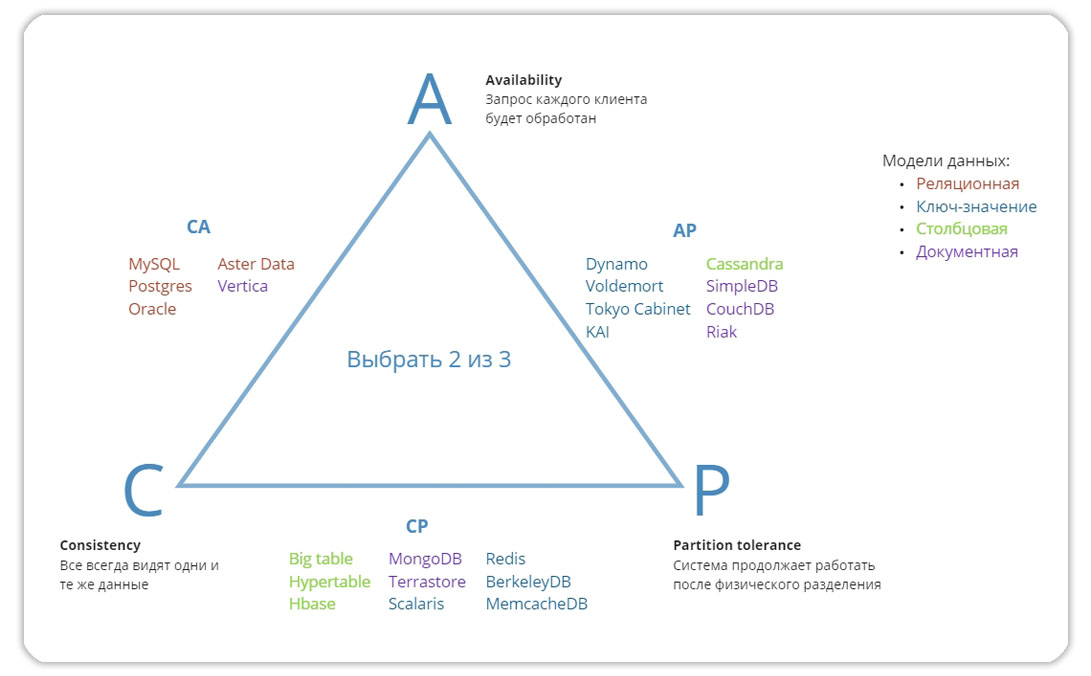
Помним, что СУБД может одновременно удовлетворять только два требования из трех. Рассмотрим эти сочетания:
- CA (консистентность и доступность). Это все реляционные базы данных. Есть поддержка транзакций. Быстрый отклик. Даже если в данный момент стоит блокировка, то СУБД дождется момента разблокировки и выполнит запрос. Есть проблема с разделением. Несмотря на то, что MySQL, Postgres, Oracle имеют механизмы масштабирования, процесс разделения затратный.
- AP (доступность и масштабируемость). Это некоторые документоориентированные и колоночные базы данных. Обеспечивают доступность данных и легкое добавление новых узлов. Что касается консистентности, то она здесь присутствует в виде Eventual consistency (Согласованность в конечном счёте). В конечном итоге изменения достигнут всех узлов. Но если в какой-то момент времени сделать одновременный запрос на несколько узлов, то результаты будут отличаться. Недавно добавленные изменения еще не достигли всех узлов.
- CP (консистентность и масштабируемость). Поддерживают консистентность, чтобы с каждого узла можно было получать одни и те же данные, и легкую масштабируемость. Но нужно понимать, что при этом не каждый запрос будет обработан сразу. CP-система не дает выполнить запрос на какой-то узел, который еще не согласован с остальными узлами.
Если говорить о какой-то аналитической системе, куда интенсивно вставляется много данных, то, возможно, нам подойдет система с Eventual consistency, так как запросы на формирование аналитических отчетов будут выполняться с некоторой задержкой. Если данные выбираются за предыдущий день, то моментальная согласованность не важна. На момент выполнения запроса данные будут в любом случае уже консистентны. Если поддерживать транзакции необязательно, то подойдут документоориентированные СУБД в рамках системы CP. Основной способ применения состоит в том, что мы обеспечиваем и согласованность и масштабируемость.
Совместимость с другими СУБД
Еще одной важной технической особенностью СУБД является возможность миграции данных и совместимость с другими СУБД. Если разрабатывать систему на реляционной БД, то мы без проблем можем мигрировать данные на легко-масштабируемые СУБД. Например, если сервис на MariaDB через какое-то время стал большим и требует обработки данных параллельно, то можно рассмотреть возможность миграции в Oracle. Но если проект разработан на MongoDB и не справляется с нагрузкой, то мигрировать на более масштабируемое решение скорее всего не получится, потому что потребуется очень много работы по преобразованию схемы данных.
Определив технические характеристики у нас появляется первичный шортлист. Осталось его просеять через сито нетехнических требований.
Нетехнические особенности СУБД
Нетехническая составляющая занимает немаловажное место при выборе и в конечном итоге может даже заставить пожертвовать какими-то техническими преимуществами. Выделим следующие ключевые особенности:
- Популярность. Чем популярнее СУБД, тем больше примеров разработанных проектов на этой системе. И больше специалистов по ее поддержке.
- Затраты на обслуживание. При выборе закрытого решения (Percona, Oracle) нужно учитывать стоимость лицензии, стоимость услуг по поддержке и время обработки тикетов на поддержку.
- Обеспечение информационной безопасности. Если в проекте предстоит работа с чувствительной информацией или персональными данными, финансовыми транзакциями, то следует подумать об обеспечении безопасности (сертификаты, шифрование, соответствие нормативным документам и т. д.).
- Администрирование и поддержка. Некоторые сложные проприетарные СУБД (например, Oracle) требуют квалифицированных специалистов для их администрирования и поддержки.
Исключив из списка системы, которые не удовлетворяют вышеперечисленные требования, получаем ту единственную, которую будем использовать в проекте.
Итак, попробуем собрать все ключевые моменты наших изысканий в виде схемы алгоритма принятия решения.
Алгоритм принятия решения
Блок-схема алгоритма:
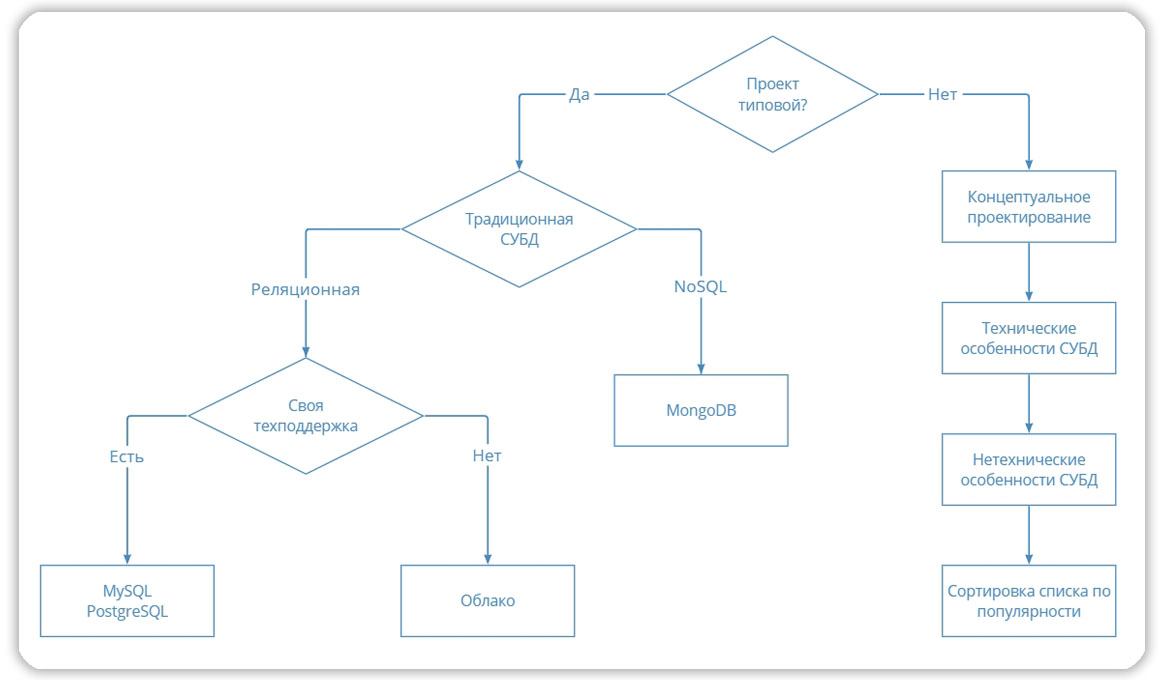
В первую очередь нужно понять, является ли проект типовым? Если это интернет-магазин, CRM-система, корпоративный портал, то очевидно, что проект решает типовые задачи и нет смысла реализовывать его на графовой СУБД. Но и не следует пренебрегать этапом анализа технических характеристик, иначе можно поставить SQLite на сложную CRM-систему.
Также решите, готовы ли вы поддерживать решение самостоятельно — если да, то лучше выбрать популярные MySQL или Postgres. Если поддерживать некому, то следует воспользоваться облачной системой с администрированием поставщика. В этом случае следует учесть юридическую возможность хранения данных в облаке.
А вот если проект специализированный, то необходимо собрать конкретные требования под задачу и пропустить требования через треугольник CAP-теоремы. После этого описать технические и нетехнические требования и отобрать подходящих кандидатов. Полученный список отсортировать по популярности. Если в итоговом списке есть СУБД, которое полностью отвечает требованиям, то берем ее в разработку. Если нет ни одной СУБД, отвечающей всем требованиям, то определить какими показателями можно пожертвовать.
Как говорится, хорошая подготовка — это половина победы. Лучше внимательно провести анализ требований и выявить узкие места еще на этапе проектирования, чем потом столкнуться с трудностями при разработке и поддержке.


