

Продолжаем собирать для вас материалы из области ML. Как и всегда предпочтение отдаем проектам, которые содержат ссылки на непустые репозитории, или предоставляют высокоуровневые API.

Iris

Компания MediaPipe, специализирующаяся на открытых ML-решениях по распознованию объектов в пространстве — вроде FaceMesh и Handpose, на основе которых мы собирали демку — представила новый инструмент Iris.
Как можно догадаться по названию, эта модель машинного обучения распознает радужную оболочку, зрачок и контур глаза, используя простую RGB камеру в режиме реального времени. С погрешностью менее 10% она также определяет расстояние между субъектом и камерой без датчиков глубины.
К сожалению, пока алгоритм не умеет определять, в каком направлении смотрит человек, ровно как и не способен на идентификацию личности, но зато в сочетании с Pose Animator он позволяет создавать более «живых» анимированных персонажей, так что ждем тренд на мультяшные маски.
FMKit
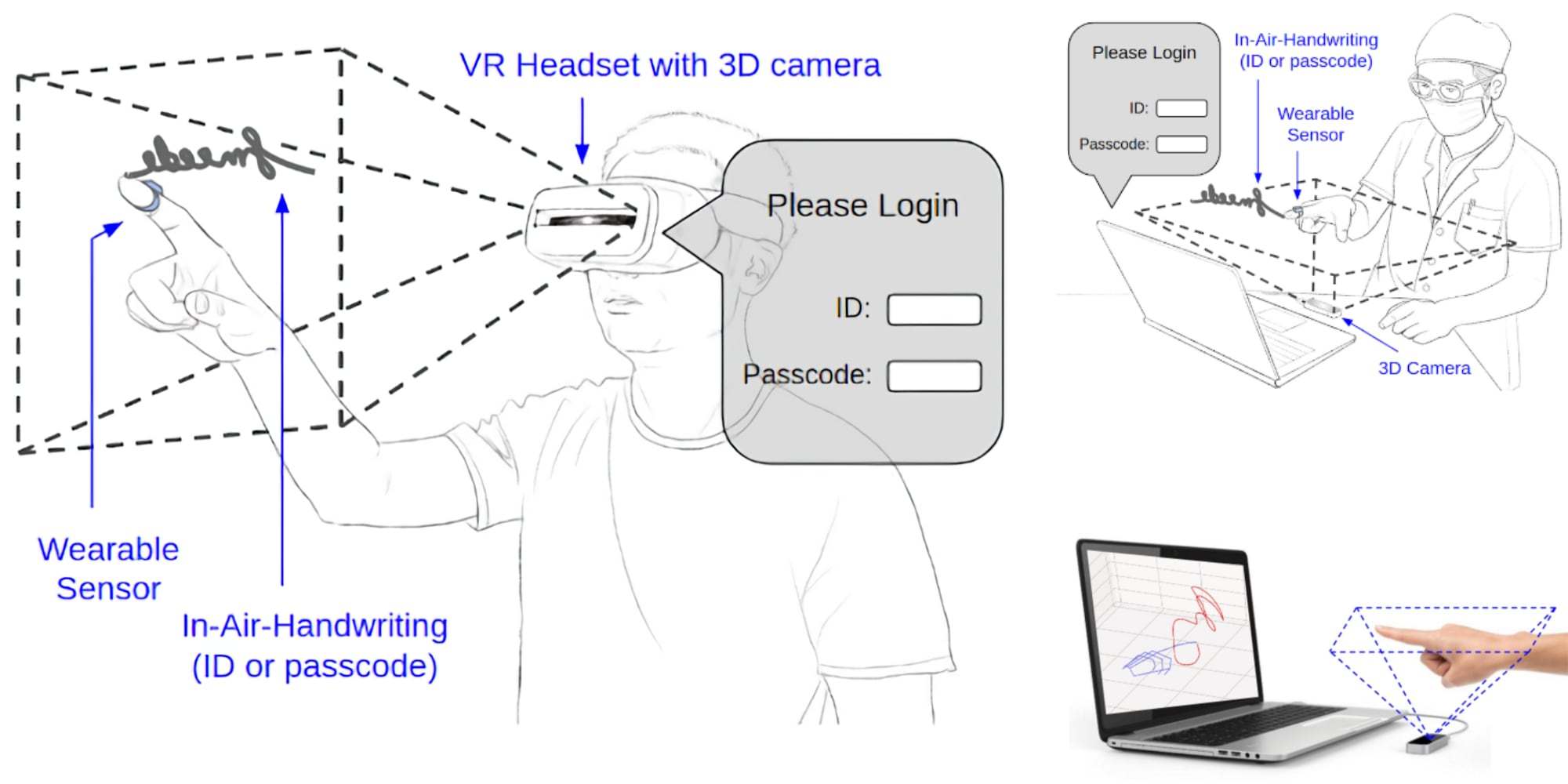
Не только Mediapipe пытаются решить проблему дорогостоящего переферийного оборудования с помощью алгоритмов машинного обучения — исследователи из университета штата Аризона разработали способ взаимодействия с VR или AR окружением без специальных контроллеров. Их алгоритм распознает написанные пальцем в воздухе слова. Обойтись совсем без устройств ввода не получилось, разработчики используют датчик захвата движения Leap Мotion. GitHub с исходным кодом и датасетами FMKit.

Style and Semantics
Исследователи из Швейцарской высшей технической школы Цюриха разработали открытую нейронную сеть, которая позволяет управлять сгенерированным изображением с помощью высокоуровневых атрибутов и текстовых описаний. На входе модели можно отдать маску объектов с их классами.
Нейронная сеть создаст изображение, похожее по структуре. Редактировать содержимое изображения можно с помощью текстовых запросов. Модель работает в два этапа. На первом создается фон изображения, на втором — генератор синтезирует передний план изображения с учетом созданного фона. Таким образом решается проблема артефактов, которые возникают на фоне при удалении или перемещении изображений с переднего плана.
Semantic Reactor
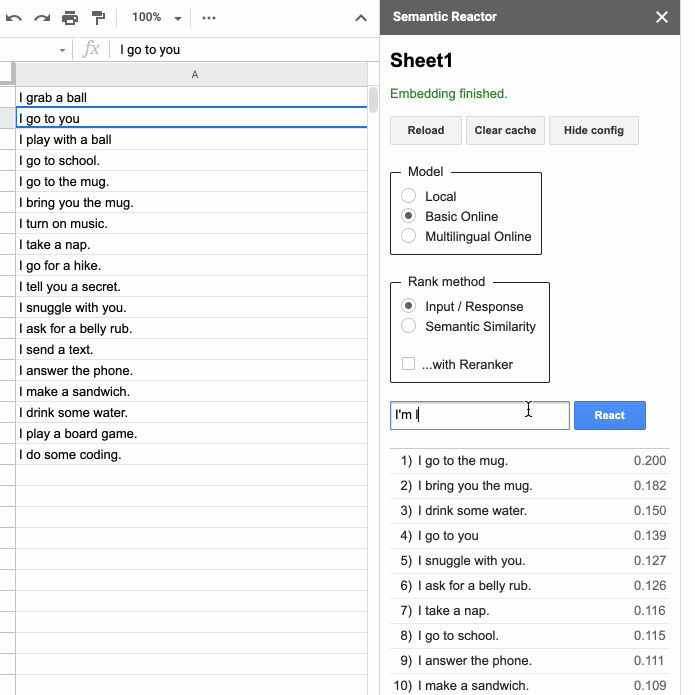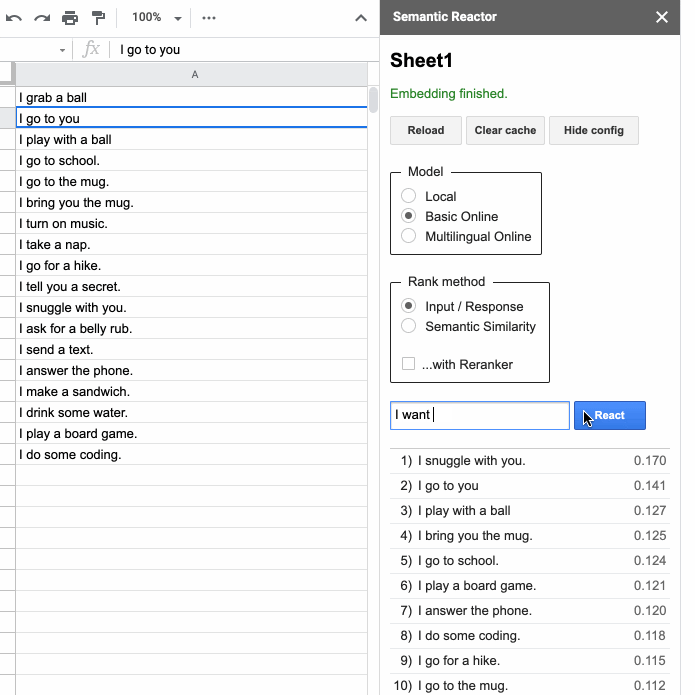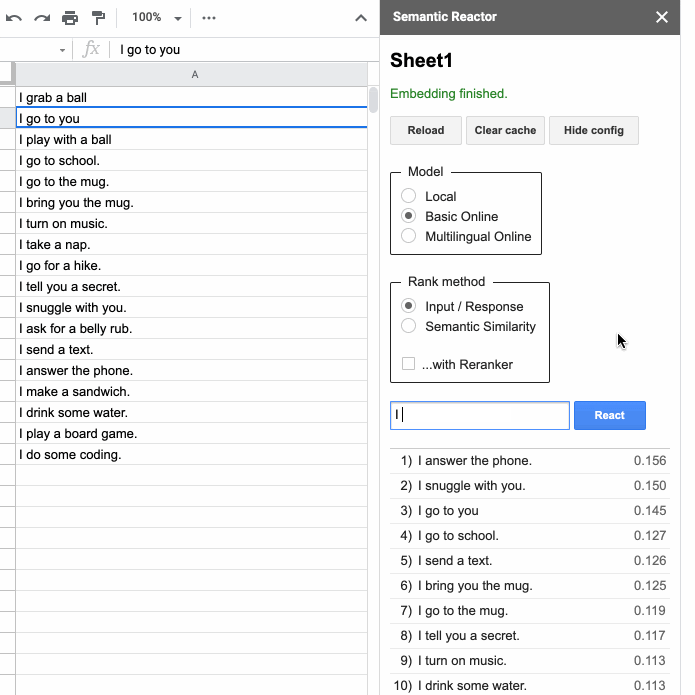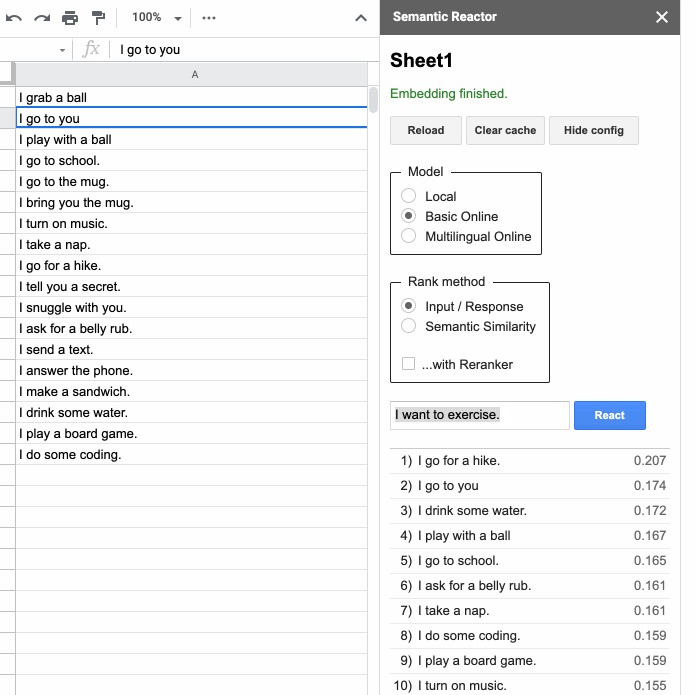
Если вы создаете приложение на основе языка — например, чатбот для обслуживания клиентов или игру-квест, то вас может заинтересовать этот инструмент. Semantic Reactor — это плагин для Google таблиц, который позволяет запускать модели понимания естественного языка на ваших собственных данных. На примере этой браузерной игры видно, на что способен инструмент. К счастью, он поддерживает и мультиязычную модель, обученную на 16 парах, среди которых есть русский.
Fawkes
Машинное обучение порождает множество этических споров, решить которые поможет… то же машинное обучение. Исследователи из чикагского университета разработали алгоритм, который вносит изменения на уровне пикселей, невидимые человеческому глазу в фотографии, чтобы они стали непригодными для других моделей. Этот процесс они называют маскировкой изображений. Назвали инструмент в честь Гая Фокса, который всем известен благодаря маске анонимуса.
Создатели утверждают, что замаскированные фото можно выкладывать в соцсетях, и если их будут использовать для обучения моделей распознавания лиц, то маскировка не позволит модели узнать вас на снимке из-за искажений. Как говорится, клин клином.

See & Spray
Кейс применения машинного обучения в сельскохозяйственной промышленности. Крупнейший в мире производитель сельскохозяйственной техники John Deere обратился к технологиям машинного обучения и компьютерного зрения, чтобы эффективнее бороться с сорняками.
Нейронная сеть определяет по снимкам сорняки, после чего мгновенно опрыскивает их гербицидами. Это позволяет экономить ресурсы, не повреждая урожай. Для обучения всех моделей использовался фреймворк PyTorch.
Первая трудность, с который столкнулись создатели — подготовка и маркирование датасетов, из-за внешнего сходства сорняков с другими культурами. Также непросто далось развертывание моделей на устройствах, так как робот должен быстро принимать решения и перемещаться по полю.
AI Economist
Разработка экономической политики и оценка ее эффективности не поспевает за переменами окружающего мира, как например это заметно на фоне всемирной пандемии. К тому же экономические модели требуют множества допущений, что ограничивает их способность полностью описывать современные экономические условия: например, они могут изолировано изучать налог на прибыль, но без учета налога на потребление.
Компания Salesforce предлагает использовать для решений этих проблем ML-алгоритмы и опубликовала фреймворк, который применяет обучение с подкреплением и экономическое моделирование для быстрой разработки и оценки новой экономической политики на основе данных.
ScaNN
Выполнить поиск даже в большой базе данных статей, используя запросы, которые требуют точного совпадения названия или автора несложно, так как такие параметры легко индексируются. В случае с более абстрактными запросами, полагаться на метрики сходства, вроде количества общих слов между двумя фразами, уже нельзя. Например, запрос «научная фантастика» больше относится к «будущему», чем к «науке», несмотря на то, что втором запросе есть одно слово, совпадающее с запросом.
Модели машинного обучения очень преуспели в понимании языка и могут преобразовывать входные данные в эмбеддинги, векторные представления слов, обученные объединять похожие входные данные в кластеры. Google представила опенсорсный инструмент для поиска похожести таких векторов.

Ре-рендеринг людей из одного изображения
Ре-рендеринг человека но основе одного изображения — сложная задача. Современные алгоритмы часто создают артефакты, вроде нереалистичного искажения частей тела и одежды.
В данном исследовании продемонстрирован новый алгоритм, который позволяет через ре-рендеринг текстуры переодевать людей в новую одежду. Он представляет позу и форму тела в виде параметрической сетки, которую можно реконструировать из одного изображения и легко изменять.
Вместо цветовых UV-карт, создатели предлагают использовать карты характеристик для кодирования внешнего вида. Пока качество слабое и исходников нет, но уже можно представить как эта технология скоро будет применяться в Ecommerce.
Бонус: в мае мы рассказывали про алгоритм, который определяет глубину кадров в видео, но тогда можно было оценить лишь видео демонстрацию, теперь стал доступен исходный код проекта.
На этом все, спасибо за внимание!


