

12 выпусков позади, значит пора немного поменять название подборки и оформление, но внутри вас всё так же ждут исследования, демонстрации, открытые модели и датасеты. Встречайте новый выпуск подборки материалов о машинном обучении.
DALL·E
Доступность: страница проекта / доступ к закрытому API через лист ожидания
OpenAI представили свою новую языковую модель-трансформер DALL-E с 12 миллиардами параметров, натренированную на парах изображение-текст. Модель сделана на основе GPT-3 и используется для синтеза изображений по текстовым описаниям.
В июне прошлого года компания уже показывала, как обученная на последовательностях пикселей с точным описанием модель может дополнять пустоты на изображениях, которые подаются на вход. Результаты тогда уже были впечатляющими, но здесь Open AI превзошли все ожидания. Подобно тому, как GPT-3 синтезирует связные законченные предложения, DALL·E создает сложные изображения.

Модели удивительно хорошо удаются антропоморфные объекты (редис, выгуливающий собаку) и сочетание несочетаемых предметов (улитка в виде арфы), из-за чего для названия и выбрали слияние двух имен — испанского сюрреалиста Сальвадора Дали и пиксаровского робота ВАЛЛ-И.
Итак, какими результатами может похвастаться модель?
Модель способна визуализировать глубину пространства, таким образом можно управлять трехмерной сценой. Достаточно при описании желаемого изображения указать, с какого угла должен быть виден предмет и при каком освещении. В будущем это позволит создавать настоящие трехмерные представления.
Помимо этого, модель способна применять к сцене оптические эффекты, например как при съемке с фишай-объектива. Но с отражениями пока справляется плохо — куб в зеркале синтезировать убедительным образом не удалось. Таким образом, с разной степенью надежности DALL·E через естественный язык справляется с задачами, для которых в индустрии используются движки 3D-моделирования. Это позволяет использовать ее для отрисовки рендеров дизайна помещений.
Модель неплохо осведомлена о географии и знаковых достопримечательностях, а также об отличительных чертах отдельных эпох. Она может синтезировать фотографию старинного телефонного аппарата или моста «Золотые Ворота» в Сан-Франциско.
При всем этом модели не нужно сверхточное описание — часть пробелов она восполнит сама. Как отмечает Open AI, чем точнее описание, тем хуже результат.
Напомним, что GPT-3 — это zero-shot модель, её не нужно дополнительно настраивать и обучать для выполнения конкретных задач. Помимо описания можно дать подсказку, чтобы модель сгенерировала нужный ответ. DALL·E делает тоже самое с визуализацией и может выполнять разные задачи image-to-image преобразования, опираясь на подсказки. Например можно дать на вход изображение и попросить сделать его в виде скетча.
Что поразительно, создатели не ставили перед собой такую цель и никак не предусматривали это при обучении модели. Способность обнаружилась только в ходе тестирования.
Руководствуясь этим открытием, авторы изучили способность DALL·E решать логические задачи визуального IQ-теста и поставили задачу не выбирать правильный ответ из представленных вариантов, а полностью предсказывать недостающий элемент.
В целом, модели удалось правильно продолжить последовательность в части задач, где требовалось геометрическое осмысление.
Модель пока не выложили, и даже нет примерного описания ее архитектуры. На данном этапе можно запросить доступ к API или ознакомиться с неофициальной имплементацией на PyTorch (также ведется работа над неофициальной версией на TensorFlow).
CLIP (Contrastive Language–Image Pre-training)
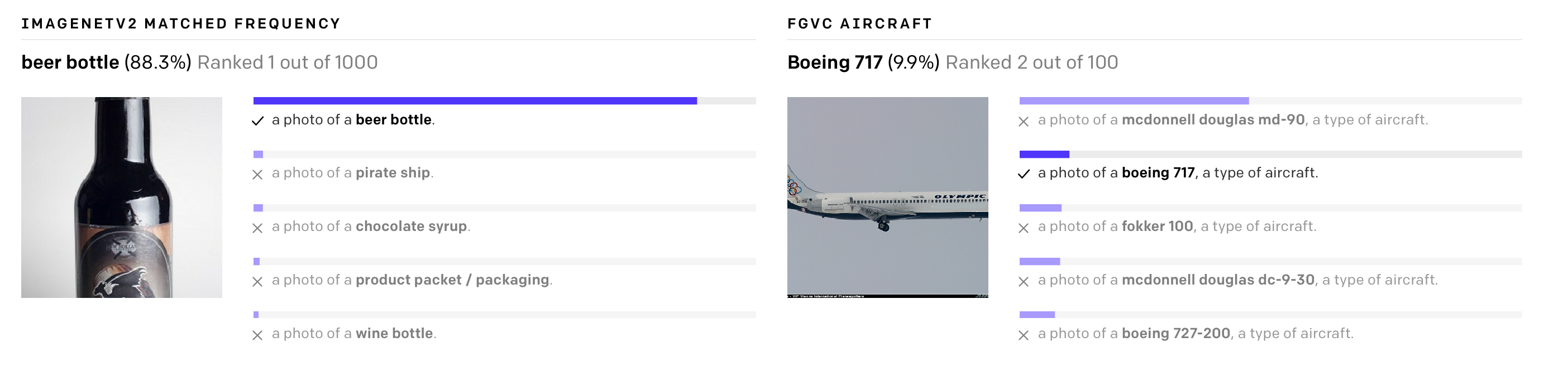
Доступность: страница проекта / исходный код
Глубокое обучение произвело революцию в компьютерном зрении, но у современных подходов все еще есть две существенные проблемы, которые ставят под сомнение использование DNN в этой области.
Во-первых, создание датасетов остается очень затратным, но при этом в результате позволяет распознавать очень ограниченный набор визуальных образов и подходит для узких задач. Например, при подготовке датасета ImageNet, чтобы составить описания к 14 миллионам изображений для 22 000 категорий объектов, потребовалось привлечь 25 000 человек. При этом модель ImageNet хороша для предсказания только тех категорий, которые представлены в датасете, и если потребуется выполнить любую другую задачу, специалистам придется создавать новые наборы данных и доучивать модель.
Во-вторых, модели, которые показывают хорошие результаты в бенчмарках, не оправдывают ожиданий в естественной среде. Развернутые в реальном мире модели справляются не так хорошо, как в лабораторных условиях. Иными словами, модель оптимизируется для прохождения конкретного теста как студент, который зубрит ответы на вопросы прошлых экзаменов.
Открытая нейросеть CLIP от OpenAI призвана решить эти проблемы. Модель обучается на большом количестве изображений и текстовых описаний, доступных в интернете, и переводит их в векторные представления, эмбеддинги. Эти представления сопоставляются так, что у надписи и подходящей к ней картинке числа будут близки.
CLIP можно сразу тестировать на разных бенчмарках, не обучая на их данных. Модель выполняет тесты по классификации без прямой оптимизации. Например, тест ObjectNet проверяет способность модели распознавать объекты при разных расположениях и при сменяющемся фоне, в то время как ImageNet Rendition и ImageNet Sketch проверяют способность модели распознавать более абстрактные изображения объектов (не просто банан, а нарезанный банан или скетч банана). CLIP показывает одинаково хорошие результаты на всех них.
CLIP может быть адаптирована для выполнения широкого спектра задач визуальной классификации без дополнительных обучающих примеров. Чтобы применить CLIP к новой задаче, нужно только дать кодировщику названия визуальных представлений, и он выдаст линейный классификатор этих представлений, по точности не уступающий обученным с учителем моделям.
На гитхабе уже появилась реализация для фотографий с Unsplash, которая показывает, насколько хорошо модель группирует изображения. Дизайнеры уже могут ее использовать для разработки мудбордов.
DeBERTa
Доступность: исходный код / страница проекта
Как и обычно, новости от OpenAI затмили прочие анонсы, хотя было еще одно событие, которое активно обсуждалось в сообществе. Представленная Microsoft модель DeBERTa превзошла базовые показатели человека в тесте SuperGLUE на сложное понимание естественного языка (NLU).
Бенчмарк на основе 10 параметров определяет, «понимает» ли алгоритм прочитанное, и составляет рейтинг. Средний показатель для людей не экспертов составляет 89.8 баллов, и задачи, которые нужно решать модели, сравнимы с экзаменом по английскому. DeBERTa показала 90.3, следом за ней идет T5+Meena от Google.
Таким образом, модели уже во второй раз удалось обогнать человека, но примечательно здесь то, что DeBERTa имеет 1,5 млрд тренировочных параметров, в 8 раз меньше T5.
Модель представляет новый, отличный от оригинального трансформера, разделённый механизм внимания, где каждый токен кодируется векторами контента и позиции, которые не суммируются в один вектор, c ними работают отдельные матрицы.
NeuralMagicEye
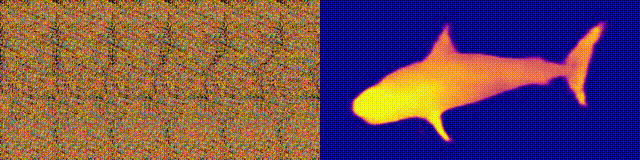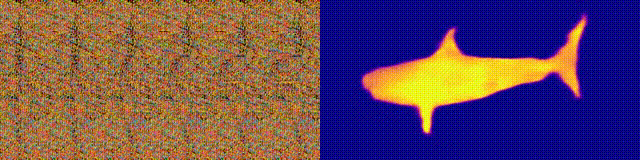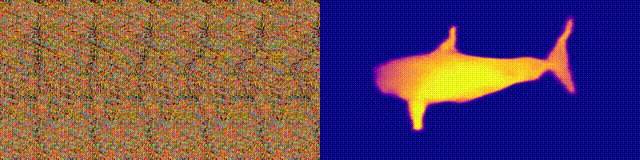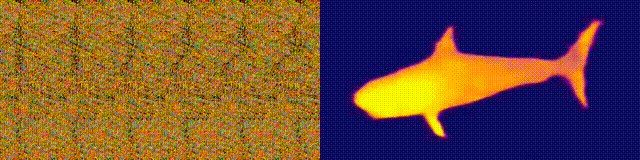
Доступность: страница проекта / колаб
Помните альбомы «Волшебный глаз» со стереограммами? Здесь нечто похожее, только для автостереограмм, у которых обе части стереопары находятся в одном изображении и закодированы в растровой структуре, благодаря чему она может создавать визуальные иллюзии трехмерности.
Автор исследования обучил CNN-модель восстанавливать глубину автостереограммы и понимать ее содержание. Чтобы добиться стерео-эффекта, модель нужно было обучить обнаруживать и оценивать несоответствие квазипериодических текстур. Модель обучалась на наборе данных из 3D-моделей, без учителя.
Метод позволяет точно восстановить глубину автостереограммы. Исследователи рассчитывают, что это поможет людям с нарушениями зрения, а также стереограммы можно будет использовать в качестве водяных знаков на изображениях.
StyleFlow

Доступность: исходный код
Как мы это уже не раз видели, с помощью безусловных GAN (типа StyleGAN) можно создавать высококачественные, фотореалистичные изображения. Однако управлять процессом генерации с использованием семантических атрибутов, сохраняя при этом качество вывода, получается редко. Из-за сложного и запутанного латентного пространства GAN, редактирование одного атрибута часто приводит к нежелательным изменениям по другим. Эта модель помогает решить эту проблему. Например, можно менять угол обзора, вариацию освещения, выражение, растительность на лице, пол и возраст.
Taming Transformers
Доступность: страница проекта / исходный код
Трансформеры способны показывать превосходные результаты в разных областях применения. Но с точки зрения вычислительных мощностей они очень требовательные, поэтому не подходят для работы с изображениями с высоким разрешением. Авторы исследования объединили трансформер с индуктивным смещением сверточной сети и смогли изображения с высоким разрешением.
POse EMbedding

Доступность: исходный код
Повседневные действия, будь то бег или чтение книги, можно рассматривать как последовательность поз, состоящую из положения и ориентации тела человека в пространстве. Распознавание поз открывает ряд возможностей в AR, управление жестами и т.д. Однако данные, полученные из двухмерного изображения, отличаются в зависимости от точки обзора камеры. Данный алгоритм от Google AI распознает сходство поз при разных ракурсах, сопоставляя ключевые точки двухмерного отображения позы с инвариантным к обзору эмбеддингом.
Learning to Learn
Доступность: исходный код
Чтобы научиться брать или ставить бутылку на стол, нам достаточно один раз увидеть как это делает другой человек. Машине чтобы научиться управлять такими объектами, требуется вручную запрограммированные награды за успешное выполнение составных элементов задачи. Прежде чем робот научится ставить бутылку на стол, его нужно вознаградить за то, что он научился перемещать бутылку вертикально. Только через ряд таких итераций он научится ставить бутылку. Facebook представил способ, который обучает машину за пару сеансов наблюдения за человеком.
Вот таким ярким был первый месяц этого года. Спасибо за внимание, и следите за будущими выпусками!


