
Как всем известно, индексы баз данных нужны для повышения производительности и снижения нагрузки. В этом материале разберем, как они влияют на выборку данных, как организована работа с данными в СУБД, для чего нужны первичные ключи и рассмотрим использование индексов на примерах.
Концептуально все реляционные системы управления базами данных (СУБД) работают одинаково — для скорости данные получают по первичному ключу. Это поле, которое однозначно идентифицирует каждую запись в таблице. Первичные ключи должны содержать уникальные значения, и в их столбце не может содержаться значений NULL. Теперь разберем, как организована выборка данных по первичному ключу.
Страничная организация
Современные СУБД используют постраничный способ работы с данными. То есть все строки внутри базы упакованы в страницы. У этой страницы есть определенный размер, например, от 4 до 64 Кб. При обработке запроса СУБД загружает в оперативную память полностью всю страницу, внутри которой данные хранятся определенным образом.
Что дает организация хранения записей по страницам:
1) Универсальная организация управления памятью. Для СУБД не обязательно знать размер записей и их типы.
2) Снижение нагрузки при вводе/выводе. Записи выбираются не по одной, а постранично, из-за чего нужно меньше операций ввода/вывода.
Страничная организация — это компромисс между считыванием всех записей в оперативную память и считыванием записей поштучно. Страница имеет заголовок постоянного размера, в котором хранятся метаданные, например, номер страницы или ссылки на другие связанные страницы. Следом располагаются данные.

Часто в качестве единицы хранения данных принимается хранимая запись. На странице размещается несколько хранимых записей и есть свободный участок для добавления новых. Если запись не помещается на одной странице, она разбивается на фрагменты, которые хранятся на разных страницах и ссылаются друг на друга.
В конце страницы расположены дескрипторы строк. Они задают смещения строк — например, если нужно получить запись 3, которая хранится на этой странице, СУБД в смещениях (Offset Row) находит запись 3, получает количество байт смещения (114), отсчитывает после заголовка 114 байт и получает нужную запись.
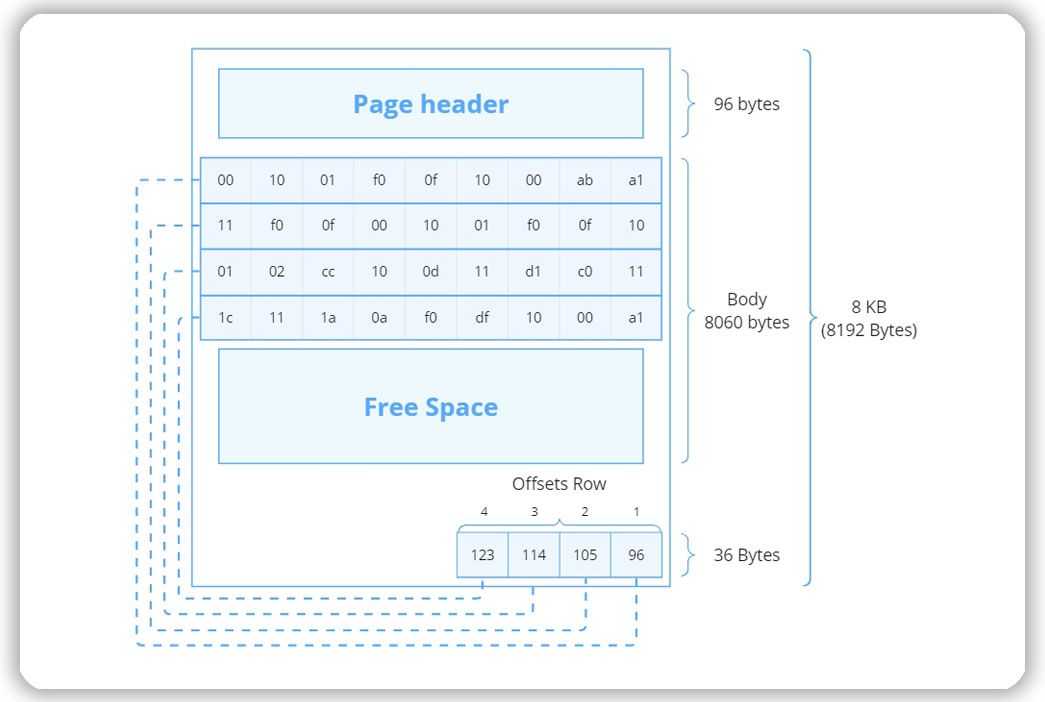
Страничная организация хранения записей в СУБД
По назначению страницы делятся на следующие типы:
- Записи (непосредственно записи данных);
- Индексы;
- Бинарные данные (BLOB, которые не помещаются на одну страницу);
- Экстенты (расширения), для хранения данных, которые не поместились на страницу;
- Метаданные (адреса свободных страниц, экстентов).
Первичные ключи
Позволяют быстро выбирать нужные записи без сканирования всех страниц таблицы. Но для этого нам нужно иметь структуру расположения страниц на диске. В этом поможет сортировка.
Для начала сортируем записи по первичному ключу на каждой странице и сохраняем список отсортированных значений. Тогда в процессе считывания сразу будет понятно, какие в ней записи. Осталось организовать способ хранения таким образом, чтобы не нужно было сканировать все страницы таблицы.
В большинстве СУБД для этого используется древовидная структура данных, которая позволяет переходить к определенному значению или диапазонам значений первичного ключа, не прибегая к сканированию всех страниц.
Например, если нужно найти запись с ID=15, СУБД переходит сначала к корню дерева, а затем переходит по ветвям дерева до конечного узла, называемого листом. В листе находится страница, содержащая запись с ID=15:
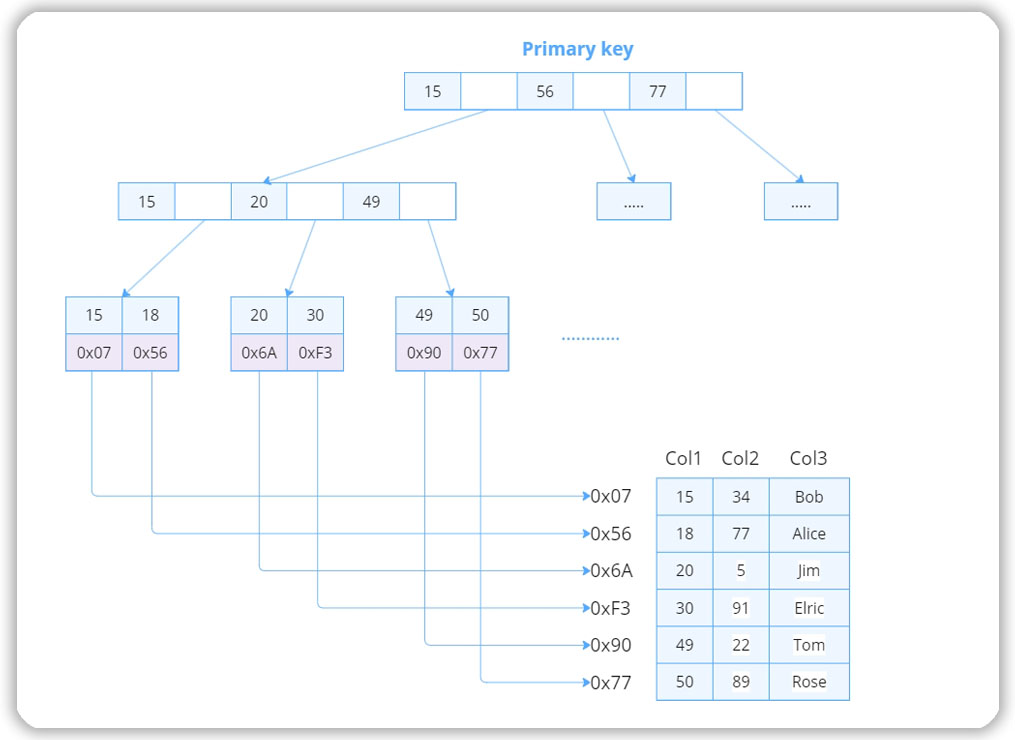
Поиск записей по первичному ключу через дерево страниц
Индексы
Иногда первичного ключа бывает недостаточно. Например, если нужно выбирать данные, агрегируя их по диапазону дат. Структура таблиц, отсортированная по первичному ключу, позволяет выбирать данные очень быстро. Но процесс можно улучшить, если мы создадим похожую структуру для агрегируемого поля. Это и есть индекс.
Индекс – это структура, которая определяет соответствие значения ключа записи (атрибута или группы атрибутов) и местоположения этой записи – КБД (доступ к ключу базы данных). Каждый индекс связан с определенной таблицей, но при этом является внешним по отношению к таблице и обычно хранится отдельно от неё.
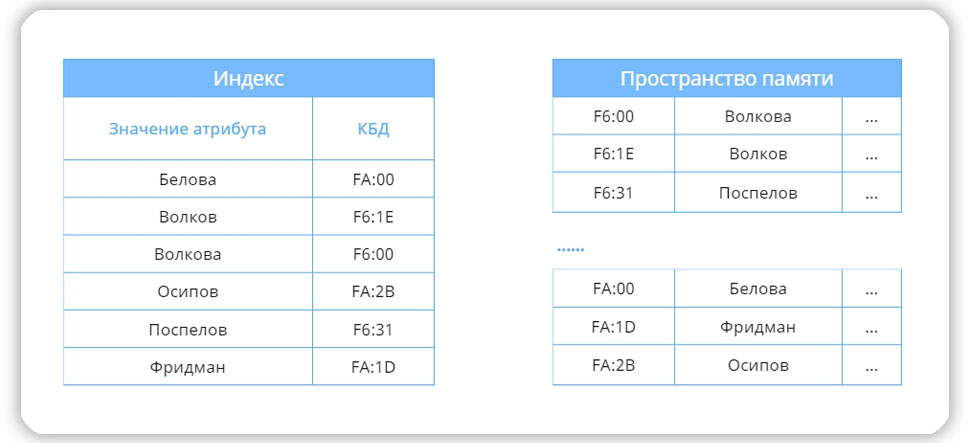
Индекс сопоставляет значение атрибута и адрес страницы с нужной записью
В качестве примера, на схеме изображен индекс по полю “Имя пользователя”. Видно, что имена отсортированы, и каждому имени соответствует ссылка на страницу памяти, где расположена запись. Это позволяет считывать данные по одному полю без сканирования всей таблицы.
В отличие от первичного ключа здесь есть задержка при считывании, потому что нужен переход по ссылке на страницу. Во всем остальном преимущества индексов сопоставимы с преимуществами, которые дают первичные ключи.
Структуры данных для хранения индексов
Деревья
Несложная структура, которая решает практически все задачи по выборке данных. Самый простой способ найти какое-то значение в списке — отсортировать этот список и затем бинарным поиском локализовать нужное значение, либо убедиться, что его нет.
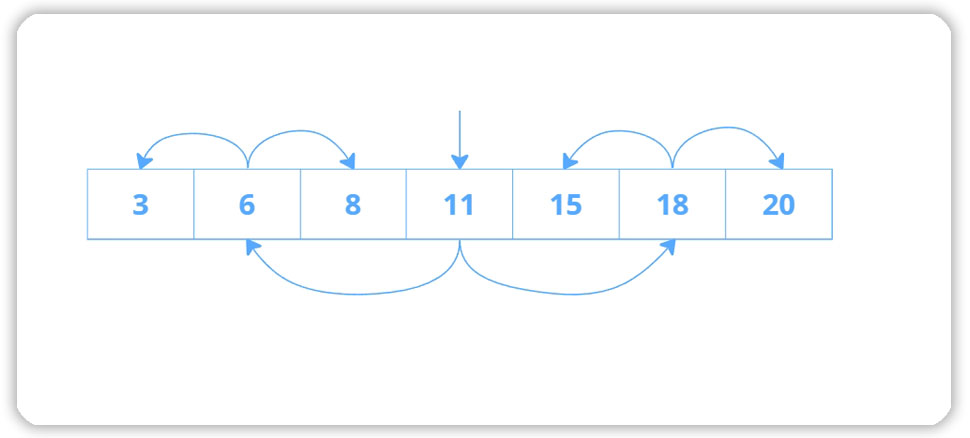
Бинарный поиск сокращает количество сравнений до O(log n)
Сложность этого алгоритма O(log n).
Для примера ориентировочное количество сравнений для элементов:
| Количество элементов в таблице | Количество сравнений |
|---|---|
| 10 | 3,3 |
| 100 | 6,6 |
| 1 000 | 9,9 |
| 10 000 | 13,2 |
| 100 000 | 16,6 |
| 1 000 000 | 19,9 |
В большинстве случаев в СУБД используются сбалансированные деревья (B-tree):
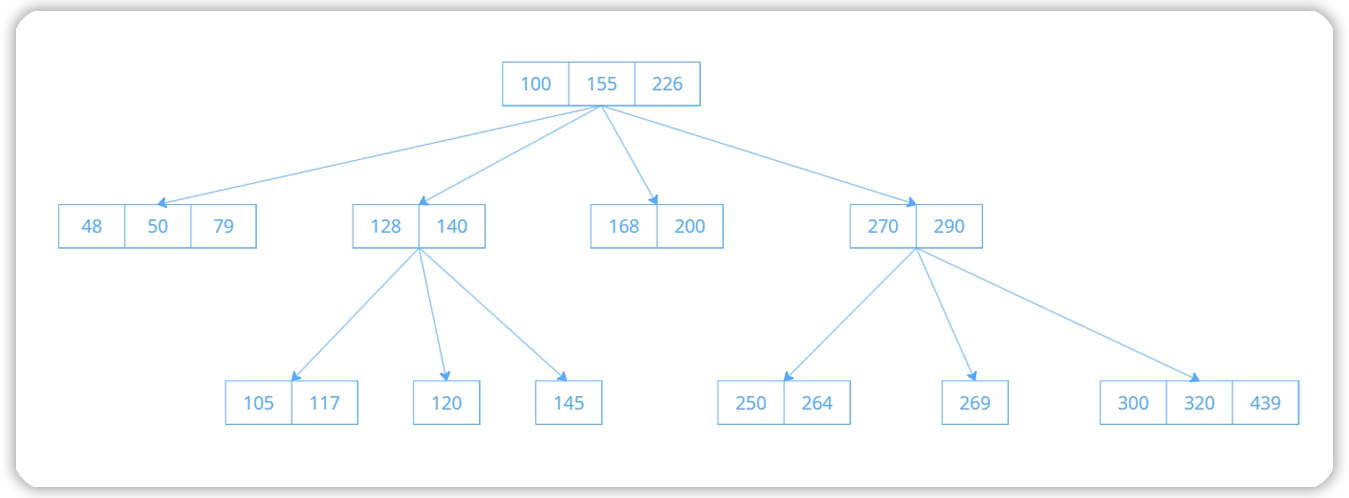
Структура B-tree, которую СУБД использует для индексирования данных
Сбалансированность обеспечивается тем, что в каждом узле дерева может быть фиксированное количество записей. В качестве записей выступает индекс, в котором находятся не данные, а ссылка на страницы с данными.
Дерево легко справляется с поиском по диапазону значений:
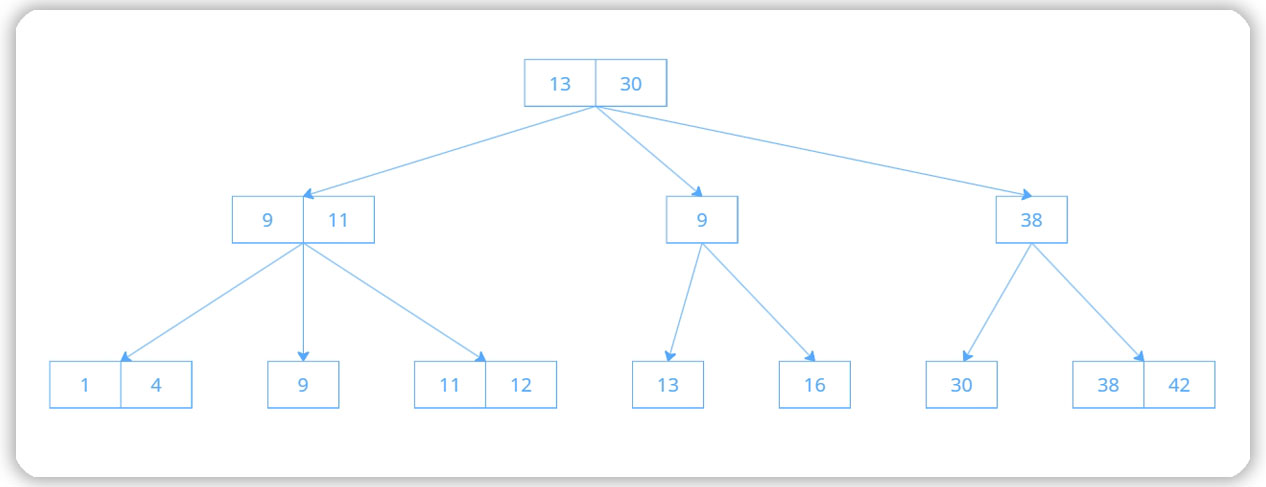
Пример поиска диапазона значений в индексе на основе B-tree
Например, нужно найти значения с 1 по 12. СУБД будет идти от значения корня 13 по ветке 9-11 к листьям 1-12. При этом остальные ветки дерева не затрагиваются. Переход по листьям диапазона 1-12 осуществляется через промежуточный переход к вышестоящему узлу 9-11, потому что именно там находятся ссылки на 1-12.
Помимо B-tree еще есть B+ tree. В такой структуре запросы на диапазон значений (range) отрабатывают еще быстрее:
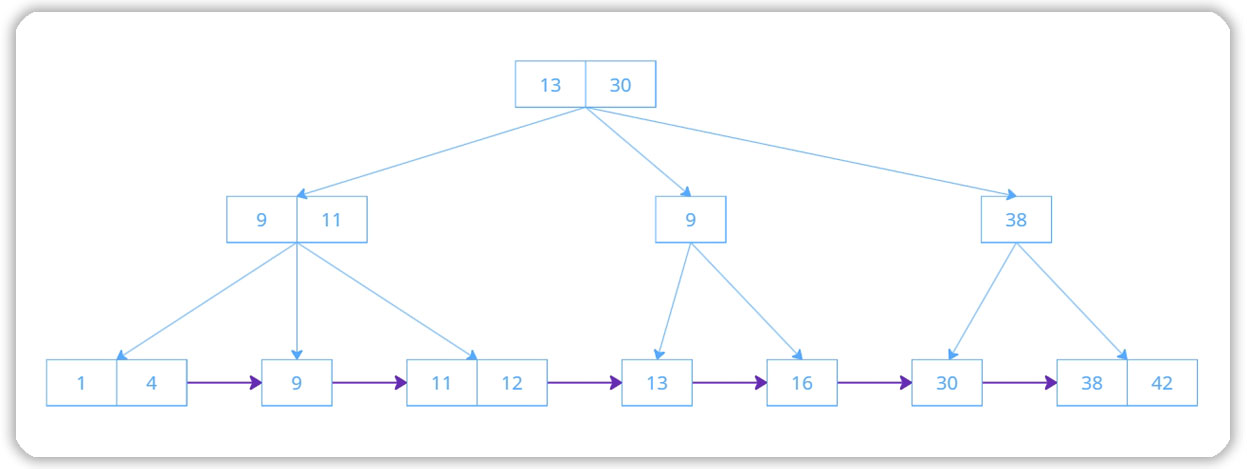
В B+ дереве листья связаны между собой, что ускоряет выборку по диапазону
СУБД будет идти от значения корня 13 по ветке 9-11 к левой границе диапазона 1-12 (лист 1). После считывания страницы со значениями 1 и 4 СУБД получает на странице 4 ссылку на следующую по порядку страницу со значением 9 и т.д. Это означает, что СУБД выбирает следующую страницу, не возвращаясь на родительский узел.
При работе с деревьями важно понимать что происходит когда добавляются новые записи в таблицу.
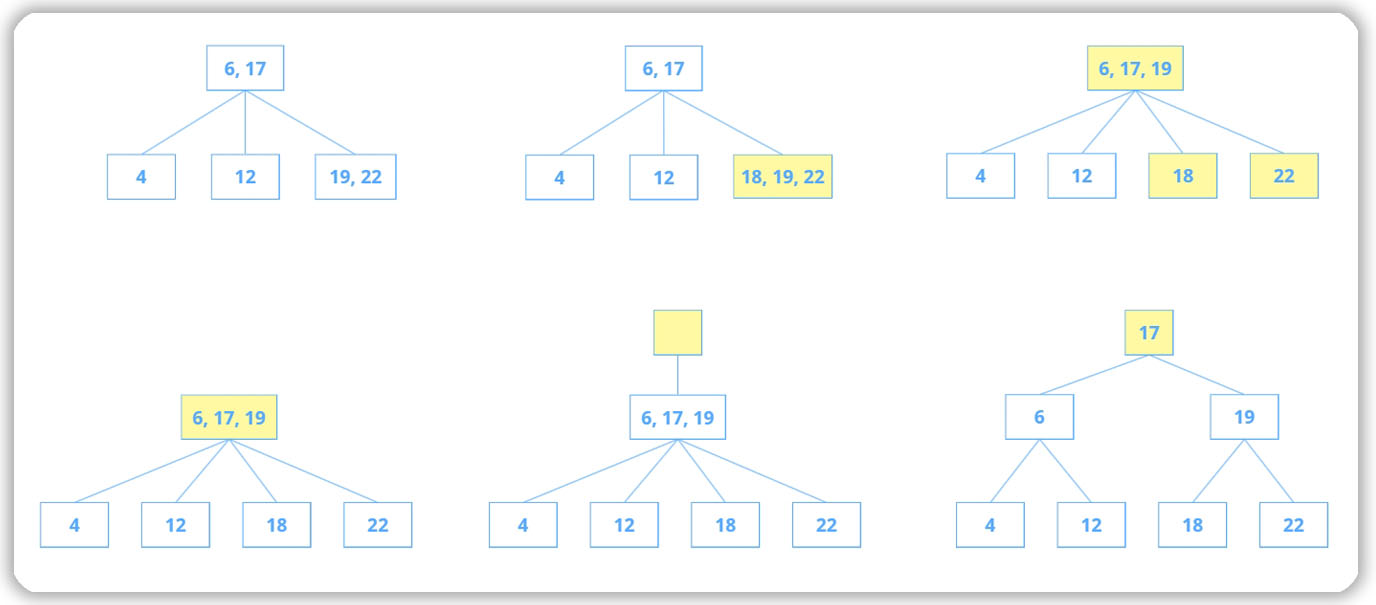
При вставке новых значений дерево индекса периодически перебалансируется
Если на странице может содержаться две записи, это значит, что в каждом узле дерева не может быть больше двух элементов. При добавлении элемента в неполный узел с деревом ничего не происходит. На соответствующую страницу просто добавляется новая запись в свободное место. Если в узел, в котором уже есть два элемента, добавляется новый элемент (узел переполнен), то дерево перестраивается. Происходит разделение узлов (создание нового родительского узла), перебалансирование записей на странице таким образом, чтобы дерево стало вновь сбалансированным. На схеме показано перебалансирование элементов сразу на двух уровнях.
Сбалансированное дерево позволяет добиться эффективного использования постраничной памяти и эффективного поиска элементов.
Но очевидно, что перебалансирование дерева занимает какое-то время, а значит, существенно влияет на производительность при вставке данных. Это главный недостаток использования индексов.
При создании индекса сбалансированные деревья используются СУБД по-умолчанию. Индекс B-tree оптимально подходит для операций поиск по диапазонам, =, >, >=, <, <=, BETWEEN.
Hash-таблицы
Это структура данных, реализующая интерфейс ассоциативного массива. Именно она позволяет хранить пары (ключ, значение) и выполнять три операции: добавления новой пары, удаления и операцию поиска пары по ключу. В индексе в качестве ключа хранится хеш значения атрибута, а значением является адрес страницы с требуемой записью.
Сложность алгоритма поиска значения в хеш-таблице O(1). Например, мы запросили данные по индексированному полю full_name. СУБД генерирует хеш по запросу, находит в хеш-таблице ключ, соответствующий сгенерированному хешу, по ключу получает адрес страницы и выбирает страницу с нужной записью. В схеме указан условный хеш в виде трехзначных чисел:
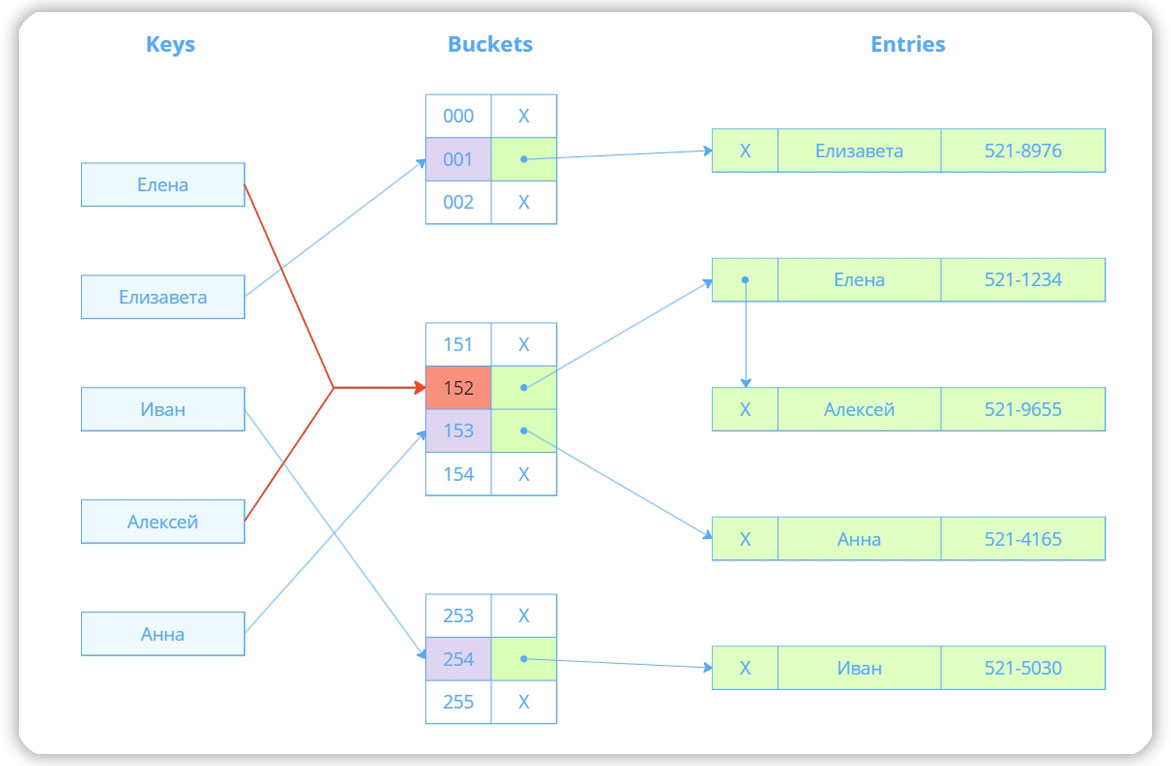
Hash-индекс сопоставляет хеш ключа и адрес страницы с записью
Еще один пример использования хеш-индексов - это фильтрация записей по какому-то значению. Например, у нас есть список пользователей. У каждого пользователя есть статус (с предустановленными значениями “Работает”, “На перерыве”, “На совещании” и т.д.). Для выборки пользователей по статусу мы можем не сканировать всю таблицу. А добавить индекс, вследствие чего мы сразу получим страницы, в которых хранятся требуемые записи.
При использовании индексов на основе хеш-таблиц нельзя выполнять range-запросы. Можно выполнять запросы только с условиями “=” и “!=”. Если нужно выбрать значения “>” или “<”, то хеш-индекс никак не поможет, поскольку СУБД сравнивает два хеша на равенство или неравенство.
GIST (Generalized Search Tree)
Это разновидность дерева R-tree, которая подходит для геолокационных данных. Эта структура данных разбивает многомерное пространство на множество иерархически вложенных и, возможно, пересекающихся, прямоугольников (для двумерного пространства).
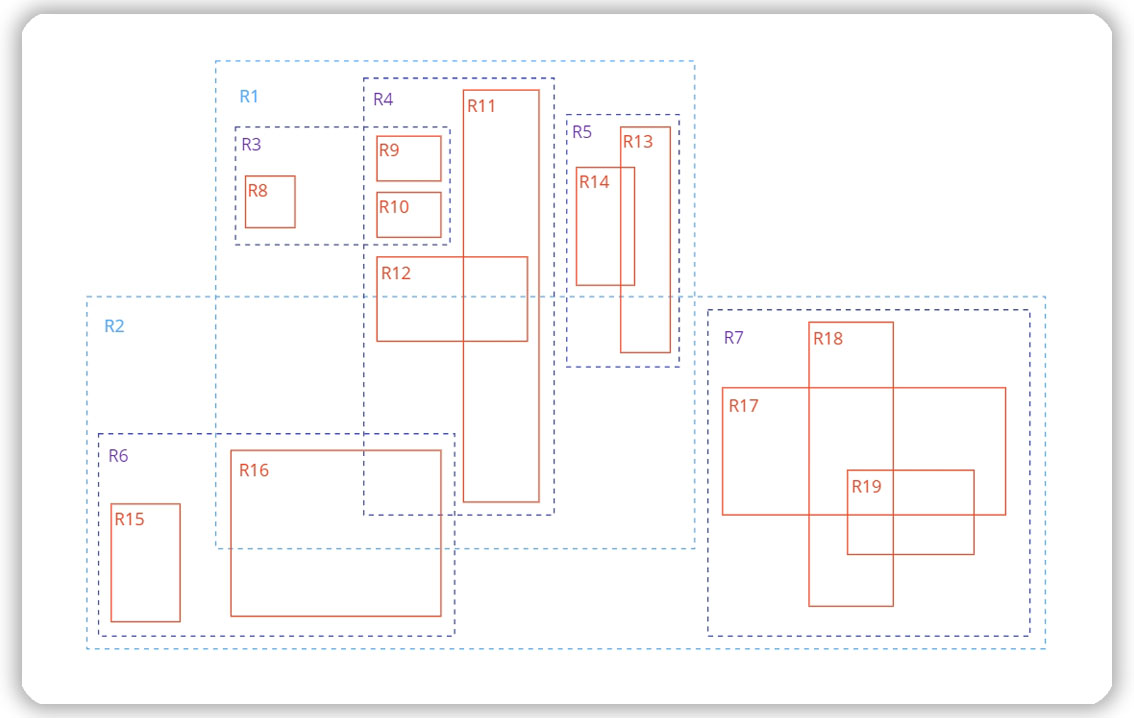
GiST-индекс группирует геообъекты в иерархию прямоугольников
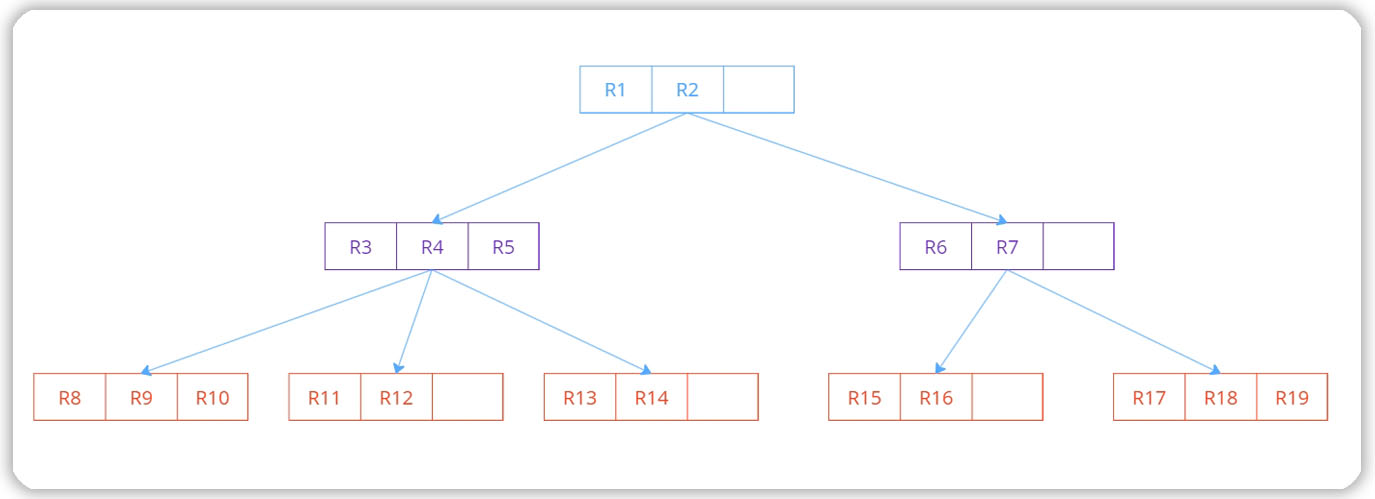
Дерево поискового индекса для быстрого поиска по геоданным
GiST обладает следующими свойствами:
- Каждый узел содержит записи между min и max индексом, если только он не является корнем.
- Для каждой записи индекса (p, ptr) в листовом узле p имеет значение true, если оно создается со значениями из указанного кортежа (т. е. p выполняется для кортежа).
- Для каждой записи (p, ptr) в не конечном узле p имеет значение true при создании экземпляра со значениями любого кортежа, доступного из ptr.
- Корень имеет не менее двух дочерних элементов, если только он не является листом.
- Все листья появляются на одном уровне.
Эта структура данных чаще всего используется для хранения геолокационных индексов.
Использование индексов
Создание:

Базовый синтаксис создания индекса в реляционной базе данных
Удаление:

Удаление ненужного индекса командой DROP INDEX
СУБД может воспользоваться индексом по определенному полю, если в запросе на значение этого поля накладывается условие, например:

Пример запроса, который может использовать индекс по условию фильтрации
Но даже при наличии такой возможности СУБД не всегда обращается к нему. Например, если запрос выбирает больше половины записей отношения, то извлечение данных через индекс потребует больше времени, чем последовательное чтение данных. Это следует из того, что данные через индекс выбираются не в той последовательности, в которой они хранятся в памяти. Для подобных запросов построение индекса нецелесообразно.
Обращение к составному индексу возможно только в том случае, если в условиях выбора участвуют столбцы, представляющие собой лидирующую часть составного индекса. Если индекс, например, включает поля (X, Y, Z), то обращение к нему будет происходить в тех случаях, когда в условии запроса участвуют поля XYZ, XY или X, причём именно в таком порядке.
При создании индекса большое значение имеет понятие селективности. Селективность определяется процентом строк, имеющих одинаковое значение индексируемого столбца: чем выше этот процент, тем меньше селективность.
Выбор столбцов для индекса определяется следующим образом:
• Сначала выбираются столбцы, которые часто встречаются в условиях поиска.
• Стоит индексировать столбцы, которые используются для соединения таблиц или являются внешними ключами. В последнем случае наличие индекса позволяет обновлять строки подчинённой таблицы без блокировки основной таблицы, когда происходит интенсивное конкурентное обновление связанных между собою таблиц.
• Нецелесообразно индексировать столбцы с низкой селективностью. Исключения для низкой селективности составляют случаи, при которых выборка чаще производится по редко встречающимся значениям.
• Не индексируются столбцы, которые часто обновляются, т.к. команды обновления ведут к потере времени на обновление индекса.
• Не индексируются столбцы, которые часто используются как аргументы выражений или функций: как правило, это не позволяет использовать индекс.
Но в следующих случаях лучше выбрать составной индекс, чем одиночный:
• Несколько столбцов с низкой селективностью в комбинации друг с другом могут дать гораздо более высокую селективность.
• В запросах часто используются только столбцы, участвующие в индексе, система может вообще не обращаться к таблице для поиска данных.
Перед принятием решения о создании индекса необходимо проанализировать, как СУБД будет выбирать данные. Для этого нужно воспользоваться командой EXPLAIN, которая выводит план запроса.
Рассмотрим на реальном примере:
В таблице билетов в кинотеатр 11 тыс. записей. Для анализа запроса, выводящего диапазон мин. и макс. цены билета на конкретный сеанс выполняется команда:

Анализ запроса через EXPLAIN перед оптимизацией индексами

Последовательное сканирование таблицы делает запрос дорогим и медленным
Seq Scan - последовательное, блок за блоком, чтение данных таблицы.
cost = 253.75 - некое условное значение, характеризующее затратность (стоимость) операции.
rows - приблизительное количество возвращаемых строк при выполнении операции Seq Scan
Для 10 млн. записей план запроса выглядит уже совсем по другому:
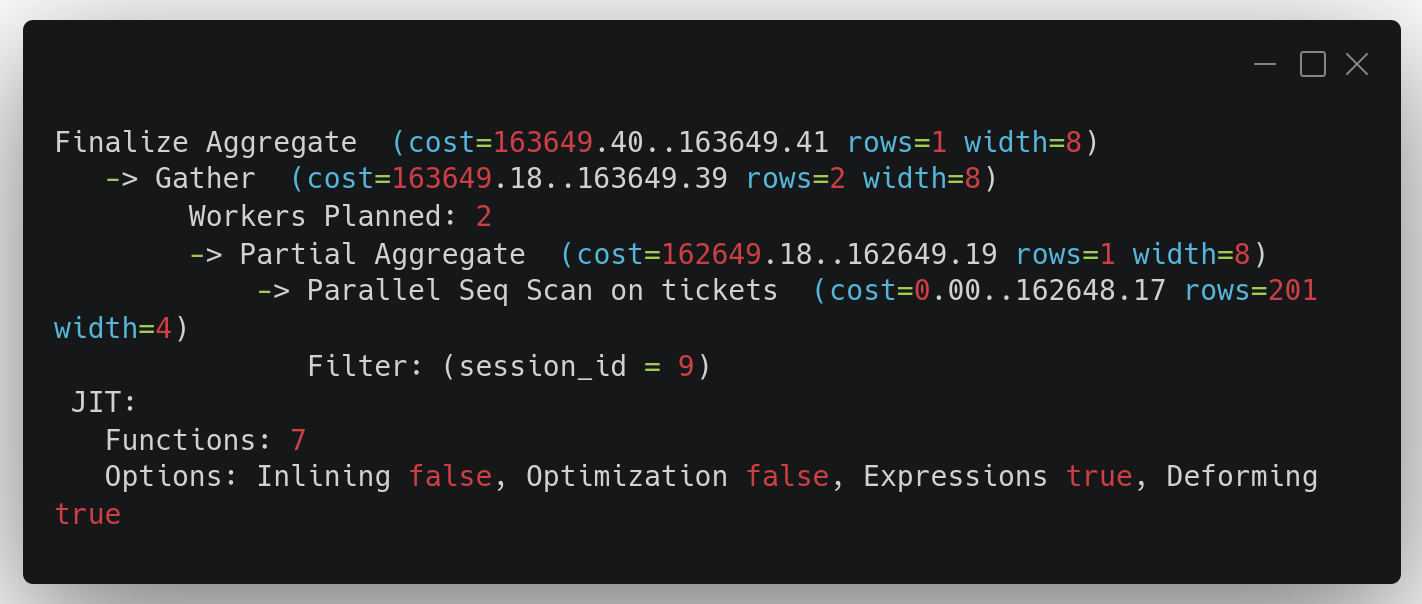
При росте объёма данных даже параллельный Seq Scan остаётся очень затратным
Здесь уже СУБД собирается распараллелить (Gather) процессы выборки (Seq Scan) и cost на процесс превышает 162 тыс. Это много, и в реальности запрос обрабатывается не быстро.
Создаем индекс CREATE INDEX session_id_idx ON tickets (session_id);
Получаем план запроса:

Создание индекса по полю session_id в таблице tickets
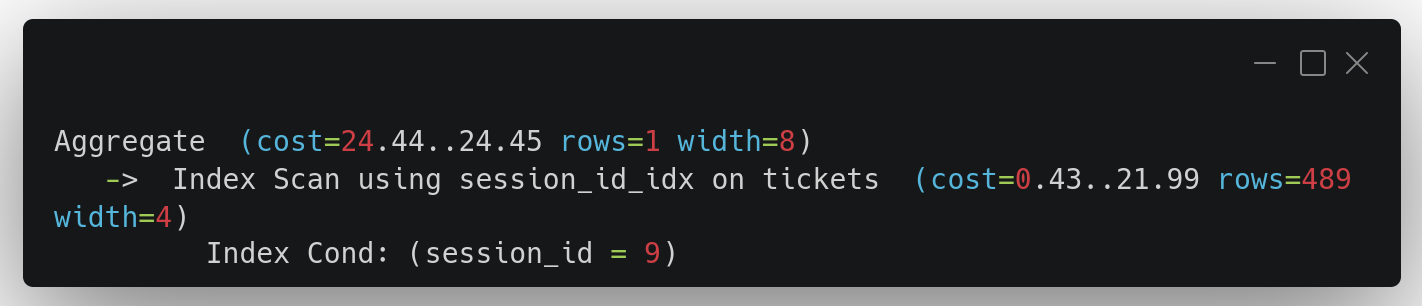
После создания индекса СУБД использует Index Scan и заметно ускоряет выборку
Index Scan using session_id_idx on tickets говорит что при выполнении запроса будет использован индекс.
cost=0.43..21.99 - отражает оптимизацию запроса на несколько порядков.
Выводы
Использование индексов — это один из важнейших путей для повышения производительности БД. Но несмотря на значительное ускорение процесса выборки данных использование индексов замедляет процесс обновления данных. Это следствие того, что при добавлении новой записи СУБД также будет добавлять запись в индексный файл. Поэтому грамотный компромисс между индексированием всех атрибутов таблицы и полным отсутствием индексов — залог производительности.

