


Фронтендерам тоже приходится много работать с данными. Это широкая, но слабо освещенная тема. Клиентские приложения получают, обрабатывают и отправляют большое количество данных пока взаимодействуют с backend. Вопросы вроде «Как правильно отправлять запросы?» охватывают весь процесс frontend разработки. И чем раньше ответить на них, тем больше нервов можно сохранить.
Сегодня пройдем путь от отправки запроса до хранения данных. Через практические примеры выведем несколько ключевых моментов. Они помогут грамотно организовать работу с данными.
Отправка запросов
Чтобы сделать запрос на бэкенд, нужно создать функцию, которая принимает данные и посылает их на сервер. При лучшем раскладе, она должна принимать только body и query-параметры.
Все остальные данные, такие как метод, url, хедеры, функция уже должна знать. Также должна уметь запускать обработки ошибки или модификации запросов.
Для удобства эту функциональность желательно объединить. Например, в нашей компании есть класс RequestManager. Помогает легко создавать запросы со стороны фронтенда. Настройка параметров, декодирование ответа, вызов промежуточных перехватчиков и прочий функционал, который отвечает за обработку запроса остается "под капотом".
В статическом поле baseUrl хранится url бека и получается из env файла. Его нужно хранить в env, чтобы была возможность переключать адреса в зависимости от площадки.
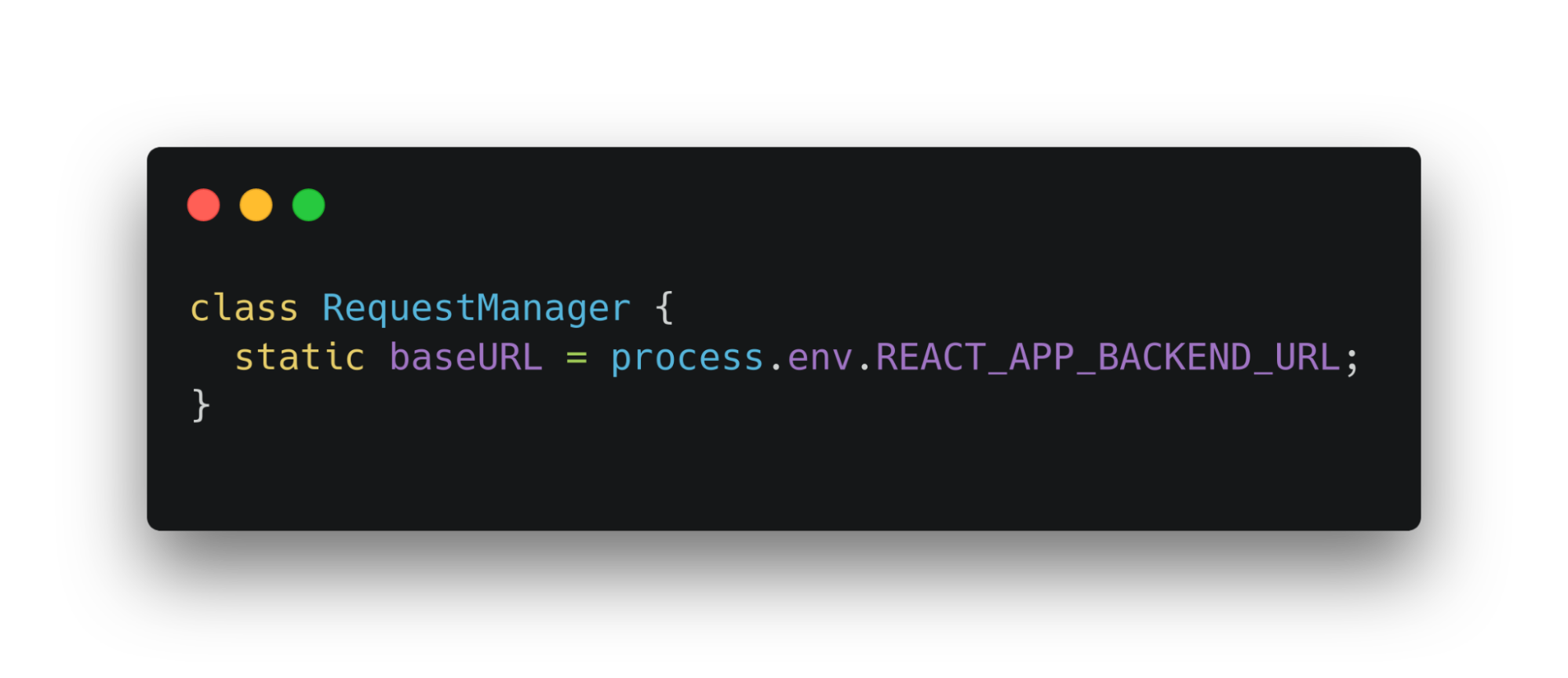
Класс использует baseUrl для создания функций, которые совершают запросы на бэк. Сама функция принимает в себя набор динамических данных, таких как body запроса или query-параметры.
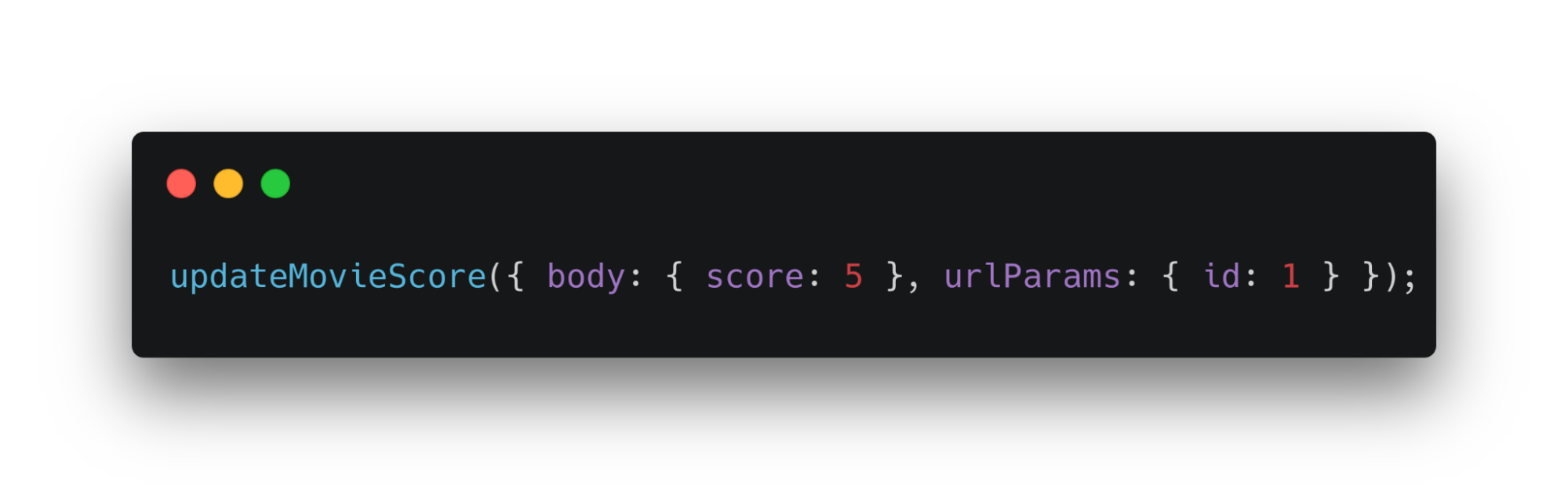
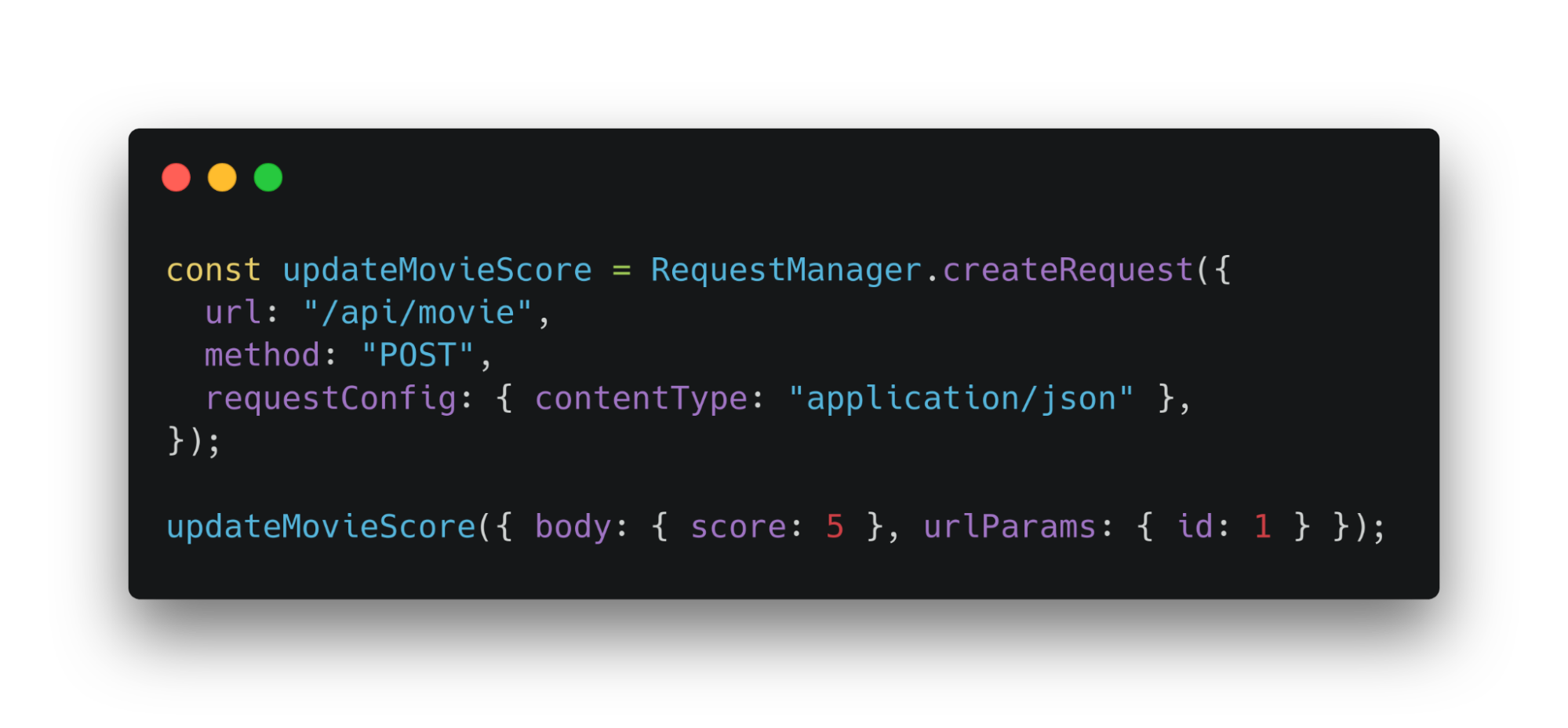
Запрос в примере выше обновит оценку фильма по указанному id. Такая функция создается через метод RequestManager — createRequest. Этот метод принимает набор статичных данных.
Для использования updateMoviesScore не нужно знать ни url, ни метод, ни хедеры. Они передаются в createRequest при создании функции. А createRequest через каррирование предоставляет их updateMoviesScore.
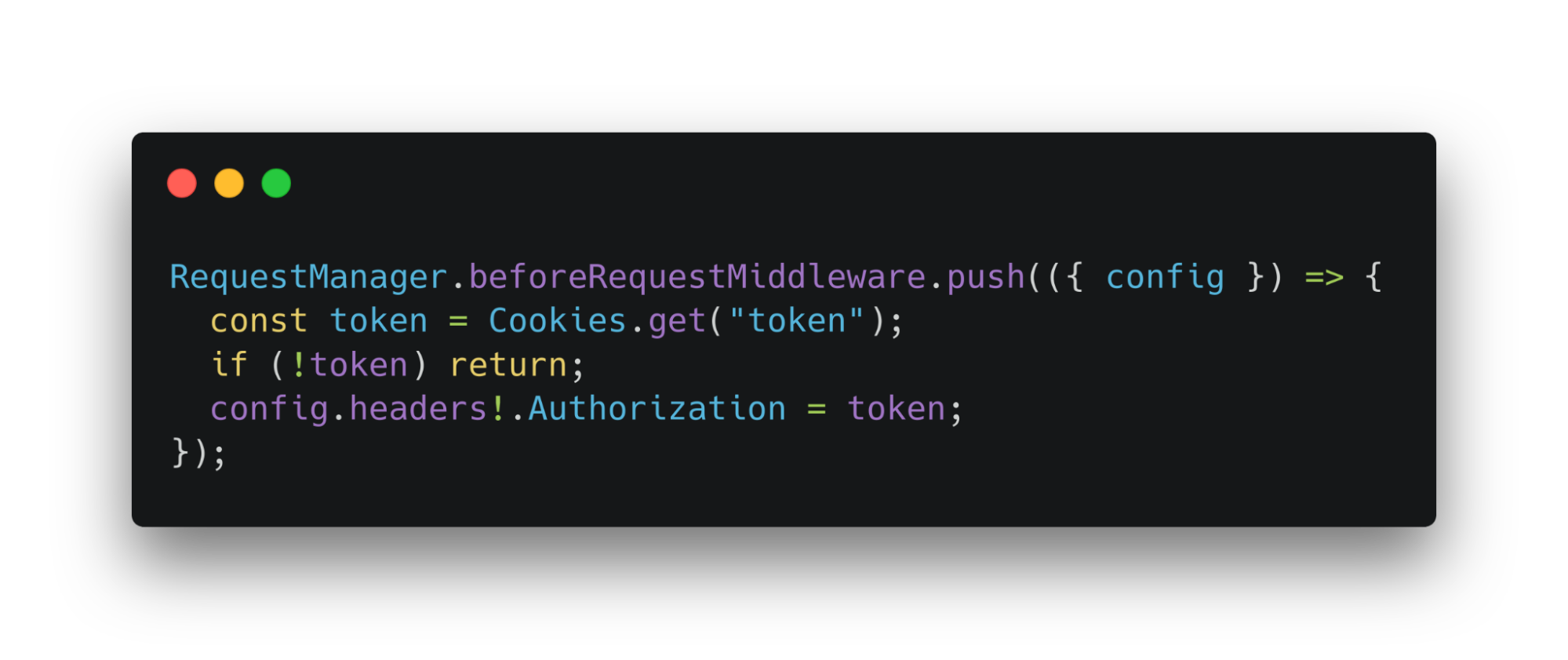
Теперь поговорим о мидллварах. Это функции, и их RequestManager запускает до или после каких-то событий во время запроса. Речь пойдет о миддлварах до запроса и до ошибки.
Добавляем миддлвару в один из массивов, которые хранятся в статичных полях. Например, так можно подключить миддлвару авторизации:
Прописываем функцию, которая достает токен из cookie и, если такой есть, помещает его в хедеры конфига. Эта миддлвара будет работать перед любым запросом на сервер.
Если токен существует и валиден, то миддлвара обеспечит его применение. Расширим функционал запросов. При этом не станем модифицировать RequestManager. Это одна из самых сильных его сторон.
Посмотрим теперь на пример с ошибкой. С помощью миддлвары можем проверять статус. Если он равен 401, перекидываем пользователя на страницу авторизации.
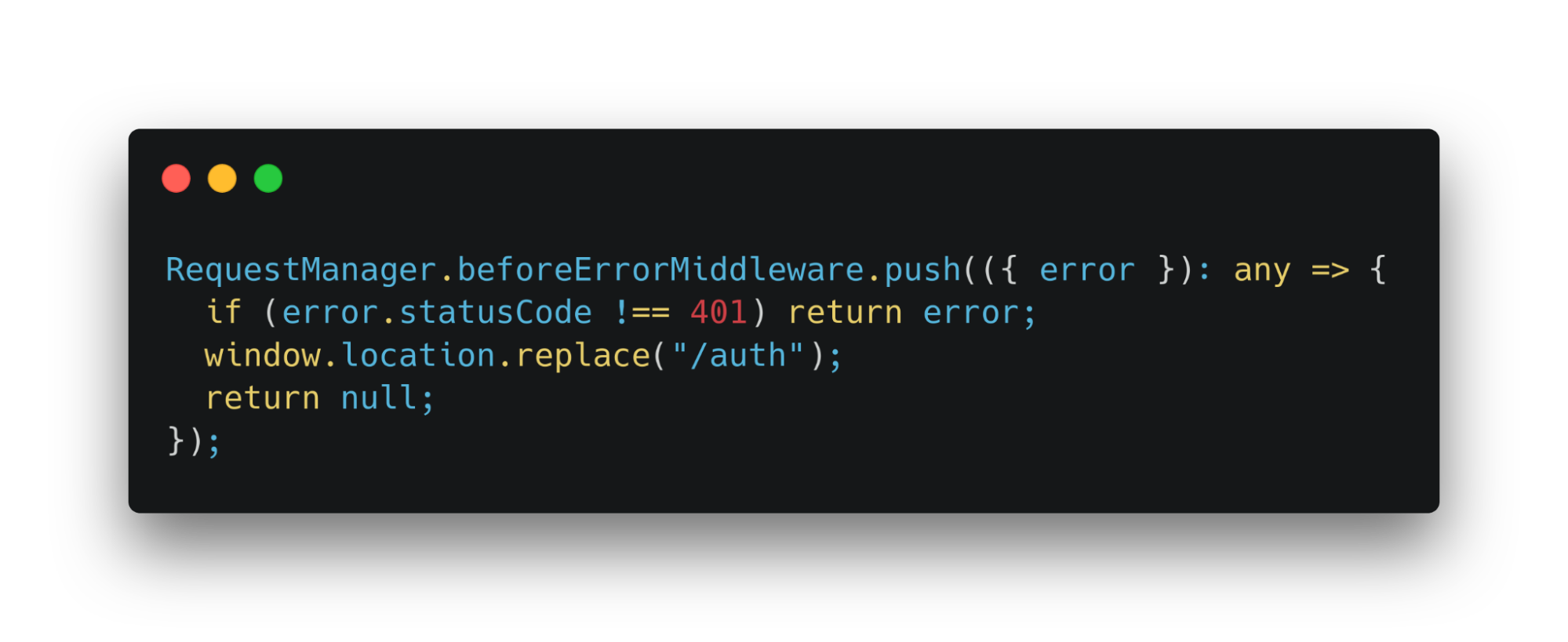
Итак, у нас есть решение, которое позволяет создавать функции для отправки запросов.
Сами функции нуждаются только в динамических данных запроса. Все дополнительные действия и обработка ошибок — задача миддлвар.
На этом этапе все почти готово к работе. Но что же делать с данными, которые получили?
Парсинг ответов
От сервера приходит json-объект. Его можно передать остальному приложению напрямую, без обработки. Однако тогда возникает несколько проблем. Посмотрите на пример ниже. Это массив, пришедший с бекенда.
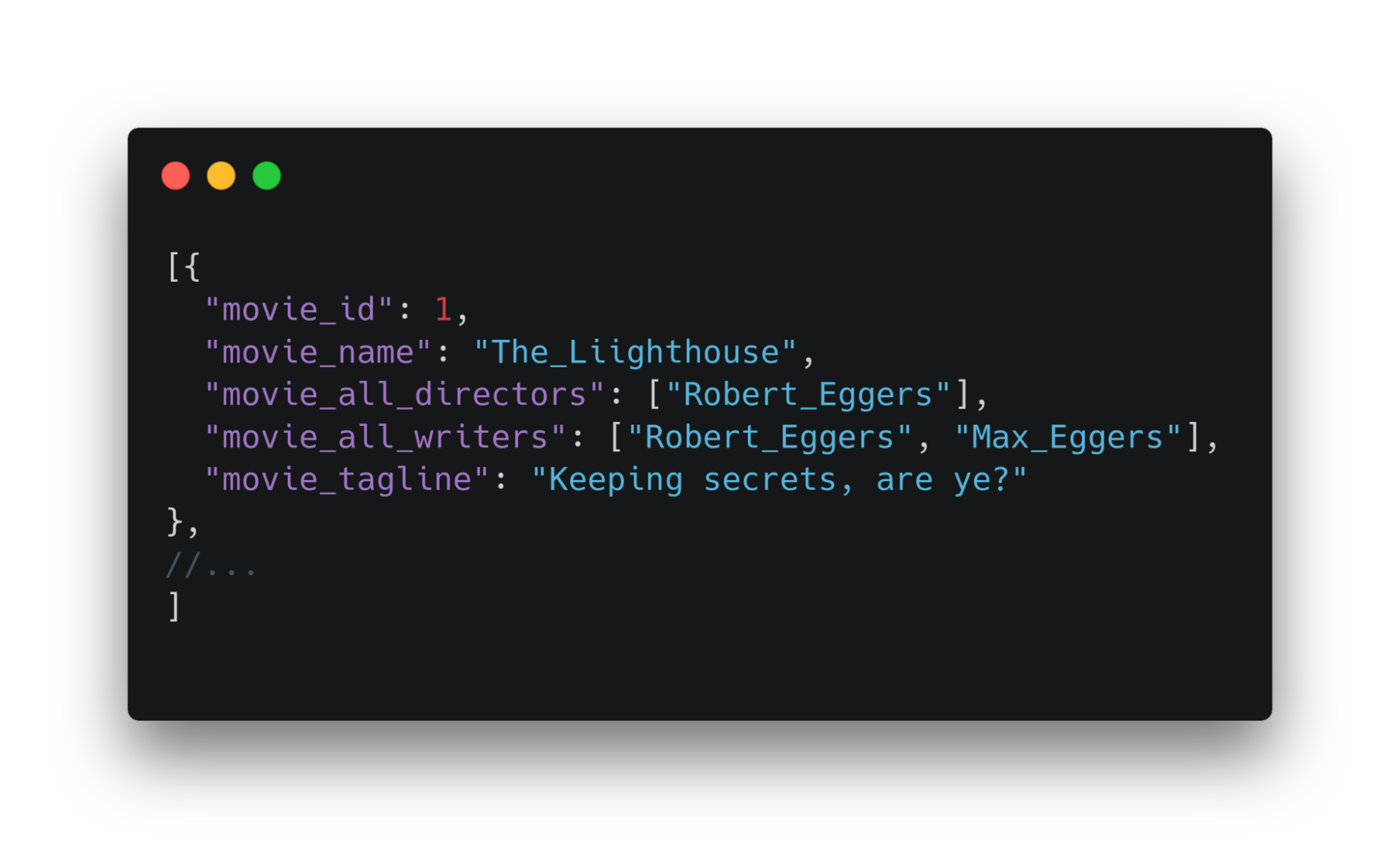
Возникают следующие проблемы:

Во-первых, фронтенд привязывается к определенной структуре данных, которые приходят с бэкенда. Приходится сохранять название полей. Например, будем вынуждены использовать поле movie.movie_id. Название полей сущности повторяет название полей объекта, приходит с бэкенда.
Во-вторых, приходящие типы данных могут не совпадать с тем, что нам нужно в бизнес-логике. Можно привести к нужному формату уже «на месте». С этим помогают форматирующие функции. Однако делать это каждый раз — значит повышать вероятность багов и уменьшать DRY кода.
В-третьих, эта структура данных, которая пришла к нам с одного из эндпоинтов. Но что если другой эндпоинт возвращает те же сущности в другом формате? Нам придется создавать интерфейсы для каждого отдельного запроса, даже если в самом приложении это одна и та же сущность.
В-четвертых, названия или структура данных могут поменяться. Даже если с бекенда они совпадают с теми, что в приложении. При изменении структуры, придется менять места, где используются поменявшиеся поля.
Например, поле режиссеров изменилось на поле movie_directors. Придется поменять все использования поля в приложении, что увеличивает вероятность багов, время разработки и стоимость изменений.
В-пятых, нельзя быть уверенным в том, какой тип данных пришел. Если получим объект вместо строки, приложение поломается с рантайм-ошибкой.
Эти проблемы приводят к следующему выводу: нужно отвязать используемые данные, от тех, что получаем. Для этого можно использовать паттерн DTO.
DTO или Data Transfer Object — это структура, которая передает информацию через архитектурные границы приложения. У него не должно быть никакой логики. Проще говоря, DTO — это глупый объект, в котором данные хранятся во время трансфера.
Нас интересует передача данных между бэкендом и фронтенд приложением. Соответственно, уже используем Data Transfer Object — body запросов и ответов. Но его также необходимо отделить от бизнес-логики приложения. Это не происходит автоматически.
Поэтому DTO надо преобразовывать в структуры данных, с которыми будем работать. Первый шаг такого преобразования — описать интерфейсы.
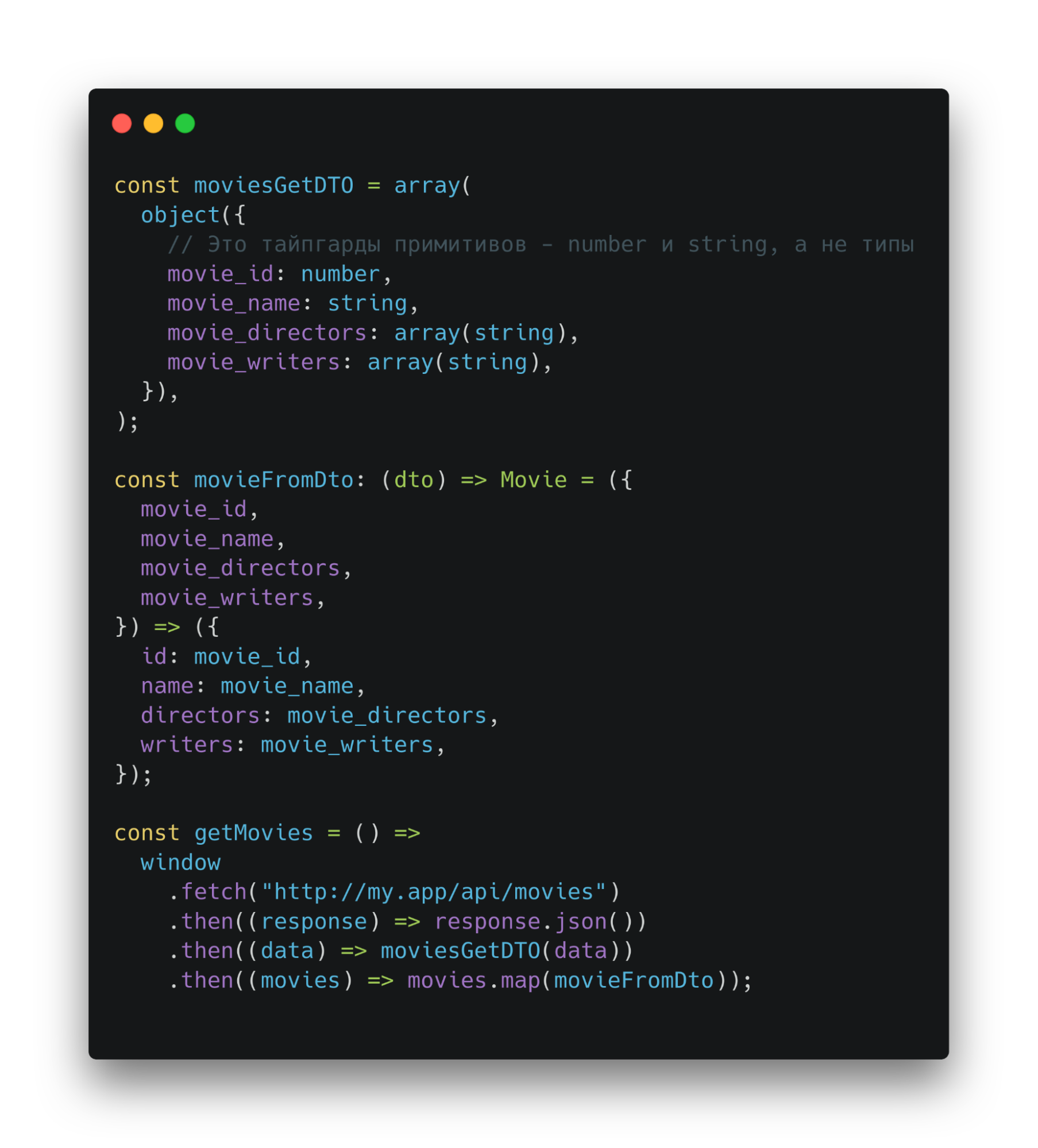
Data Transfer Object интерфейс описывает пришедшие или отправляемые данные и называется соответственно конвенциям — [InterfaceName][RequestMethod]DTO. Второй интерфейс — описание того, что будем использовать в приложении. Строгих правил наименования нет.
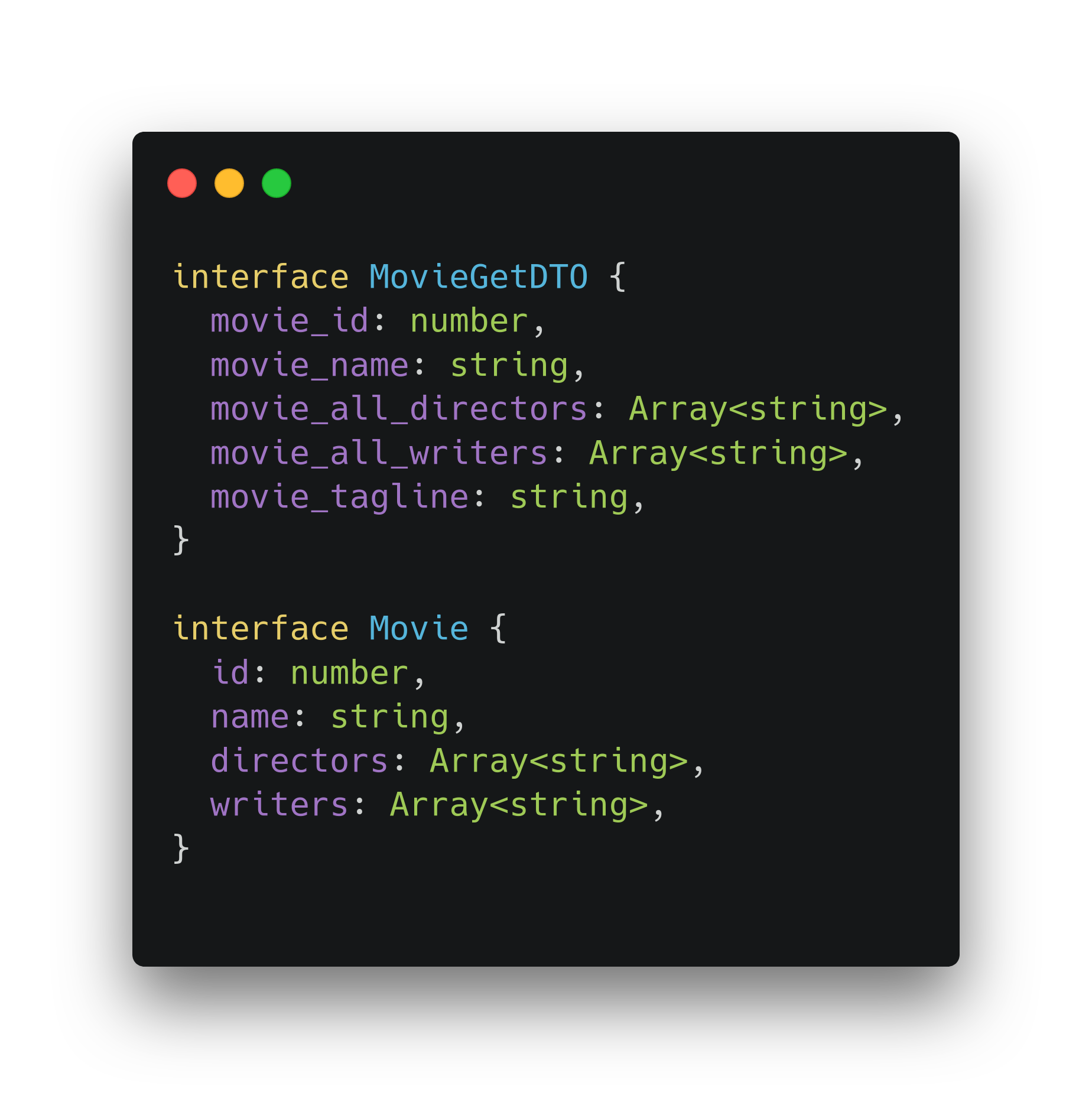

После того, как получили ответ, можем установить его тип как Data Transfer Object. Затем массив можно преобразовать через функцию-трансформатор. Теперь бизнес-логика знает только о массиве объектов, которые соответствуют интерфейсу Movie.
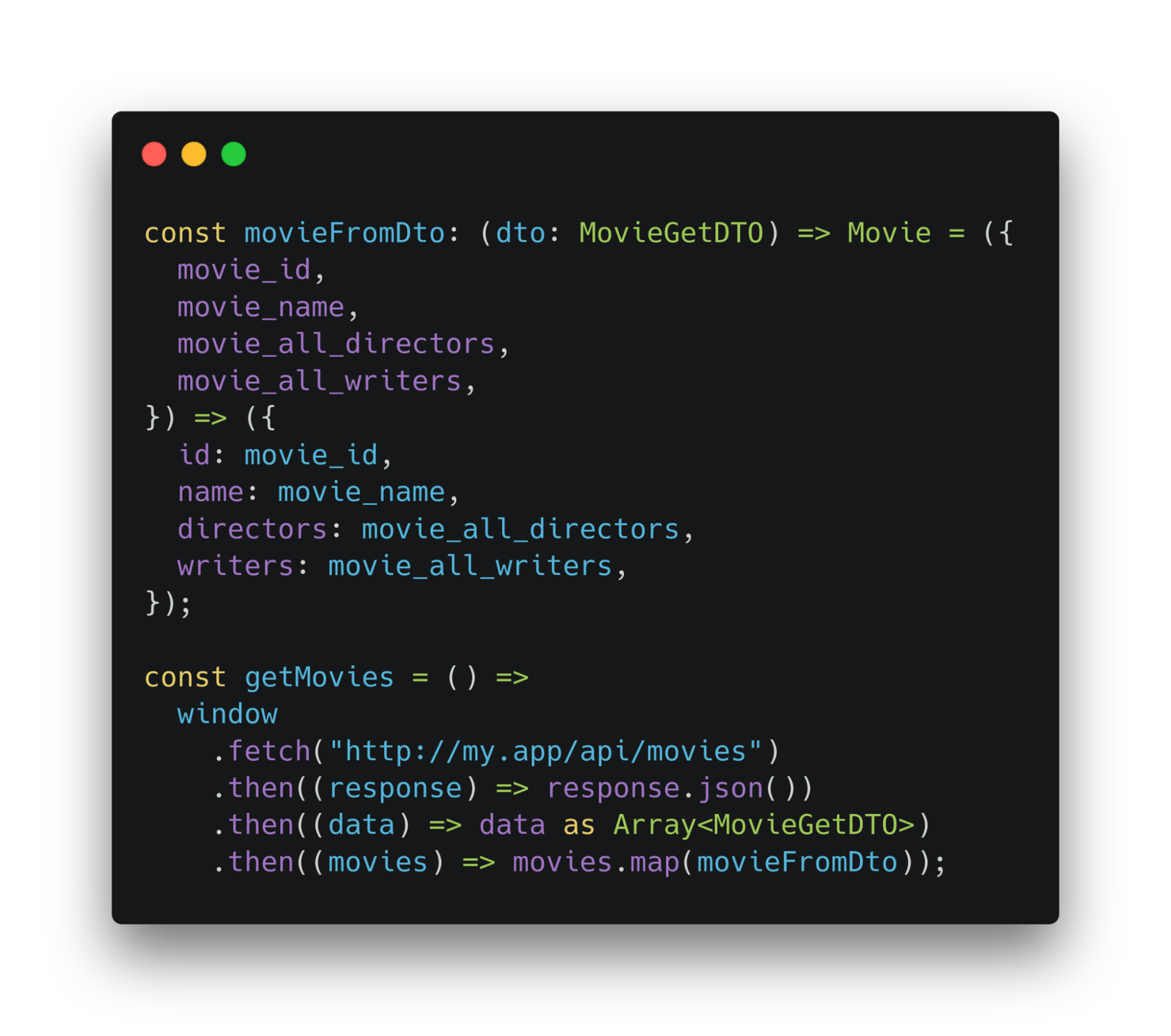
Если произойдут изменения на бэке, то для того, чтобы внести коррективы на фронте, нужно изменить интерфейс Data Transfer Object и функцию-трансформатор.
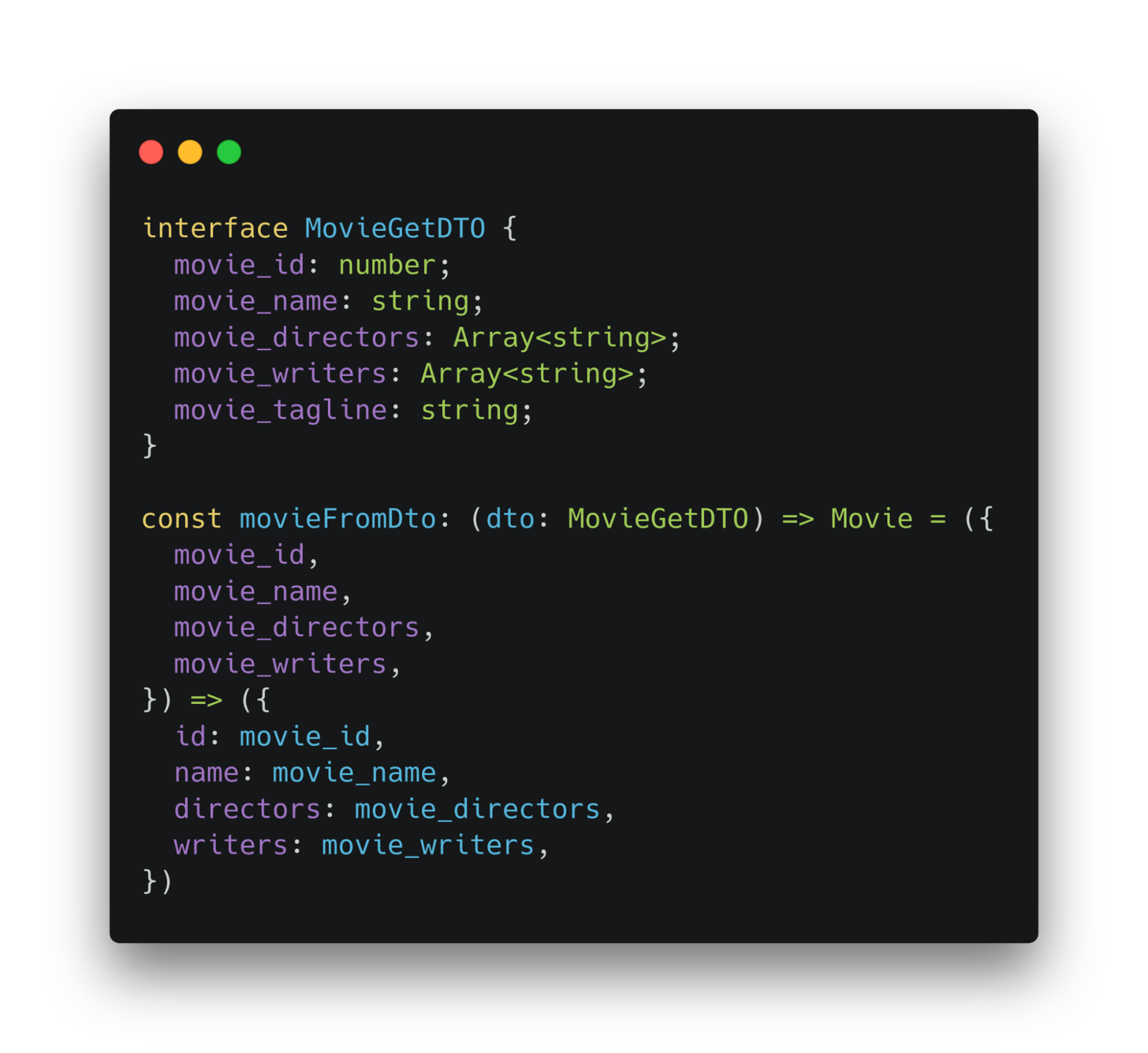
Повысим устойчивость приложения к изменениям бэкенда. Даже если на бекенде произойдет изменение, всегда сможем быстро откорректировать фронт. Вся логика работы с респонсом хранится в одном месте.
Но что произойдет с приложением без корректировок, если бэк снова поменяется? Сделаем модификации, переименуем movie_directors, запустим код и получим рантайм-ошибку.


Typescript компилируется в javascript и не имеет своей логики, которая будет типизировать сущности в рантайме. Если используем только мощности typescript, а в приложение попадают новые данные, то все что можно сделать — преобразовать тип.
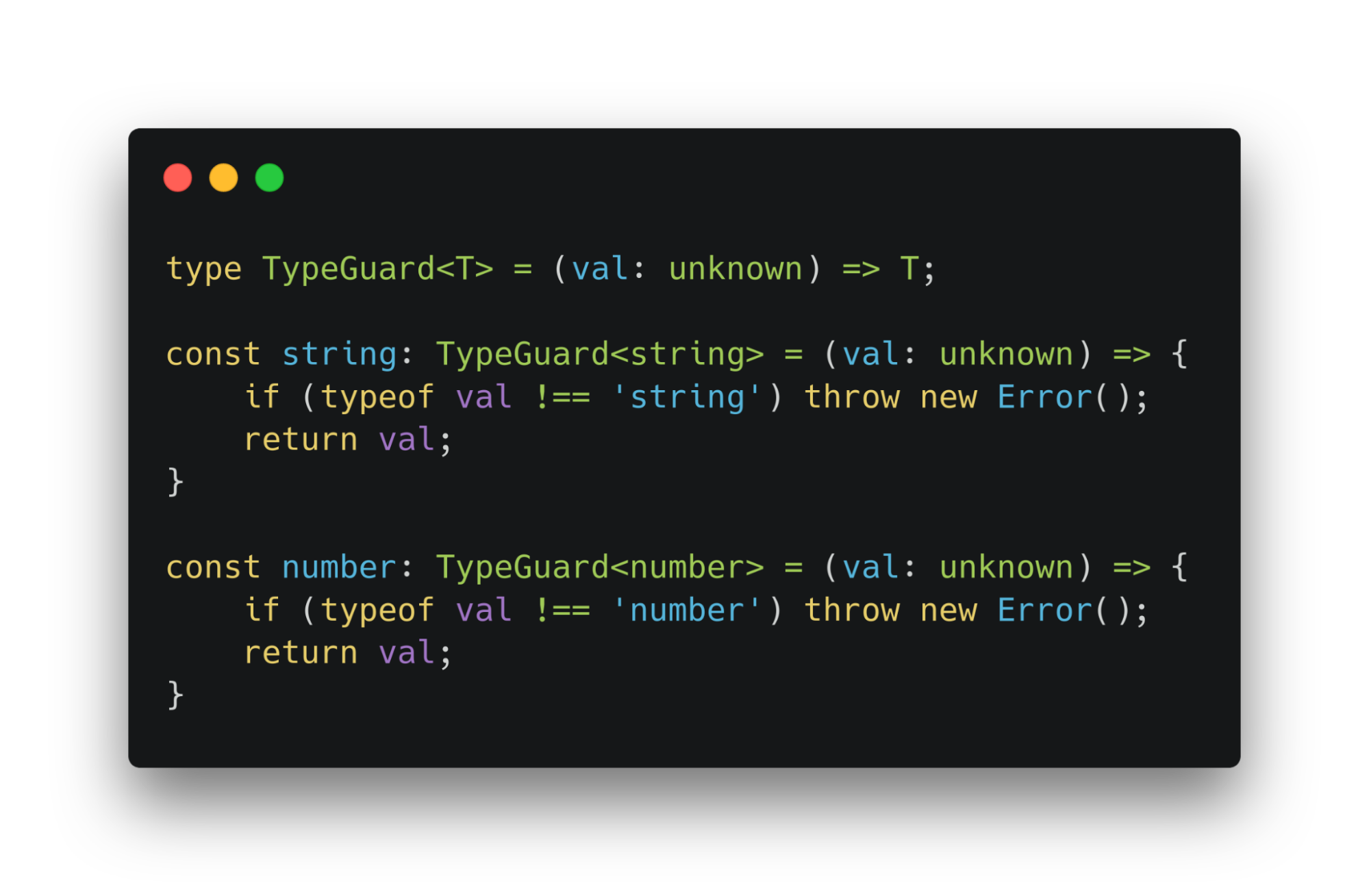
Решение есть и на такие вызовы. Data Transfer Object можно сдекодировать в рантайме с помощью тайпгардов.
Тайпгарды — простые функции. Имеют сигнатуры, говорящие тайпскрипту типы параметров.
Тайпгарды примитивов проверяют тип полученных данных и, либо возвращают их, либо выдают ошибку.
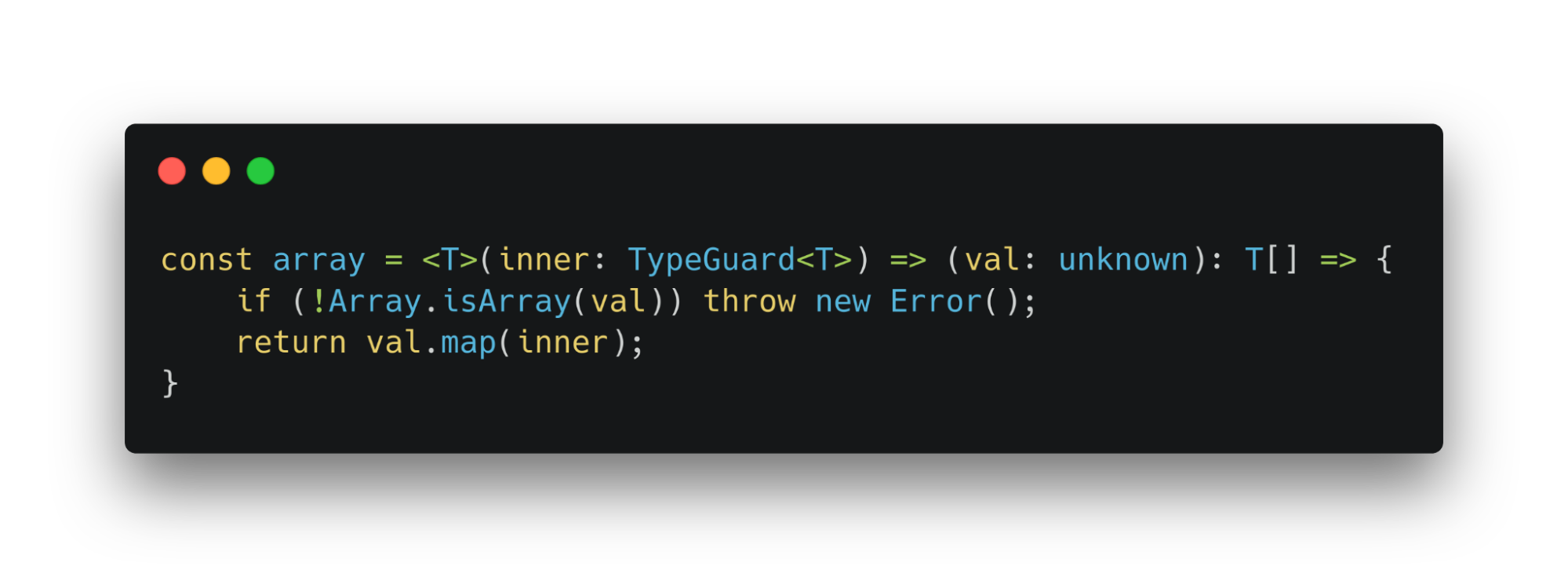
Но для объектов и массивов все сложнее. Тайпгард массива использует параметр inner. С помощью него назначаются типы всем элементам в цикле.
Тайпгард объекта создает новый объект. Каждое свойство заполняется результатами его применения.
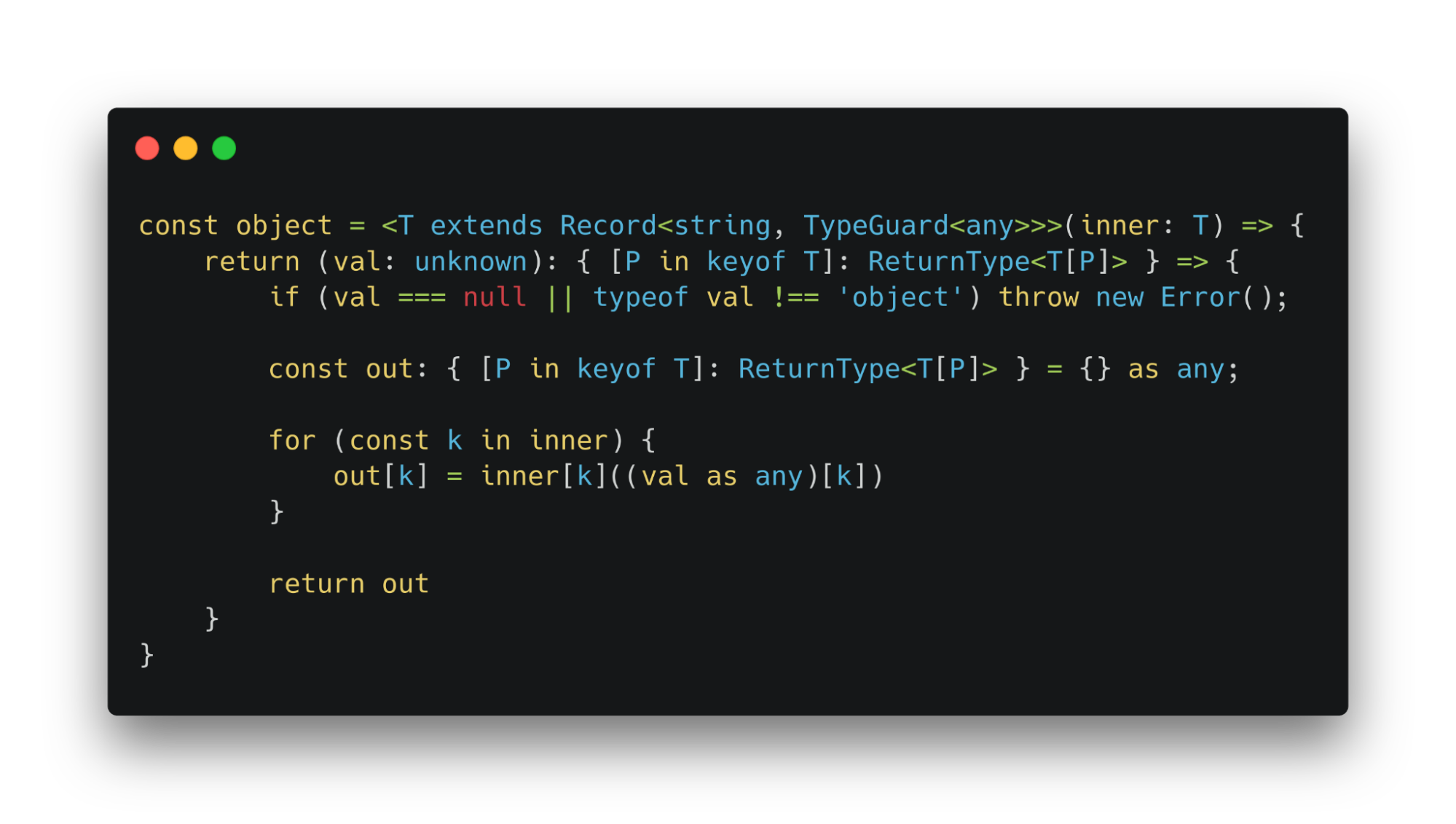
Такой метод позволяет определять тип приходящих данных в рантайме. Тайпгарды являются функциями, поэтому можно проверять специфические свойства передаваемых значений.
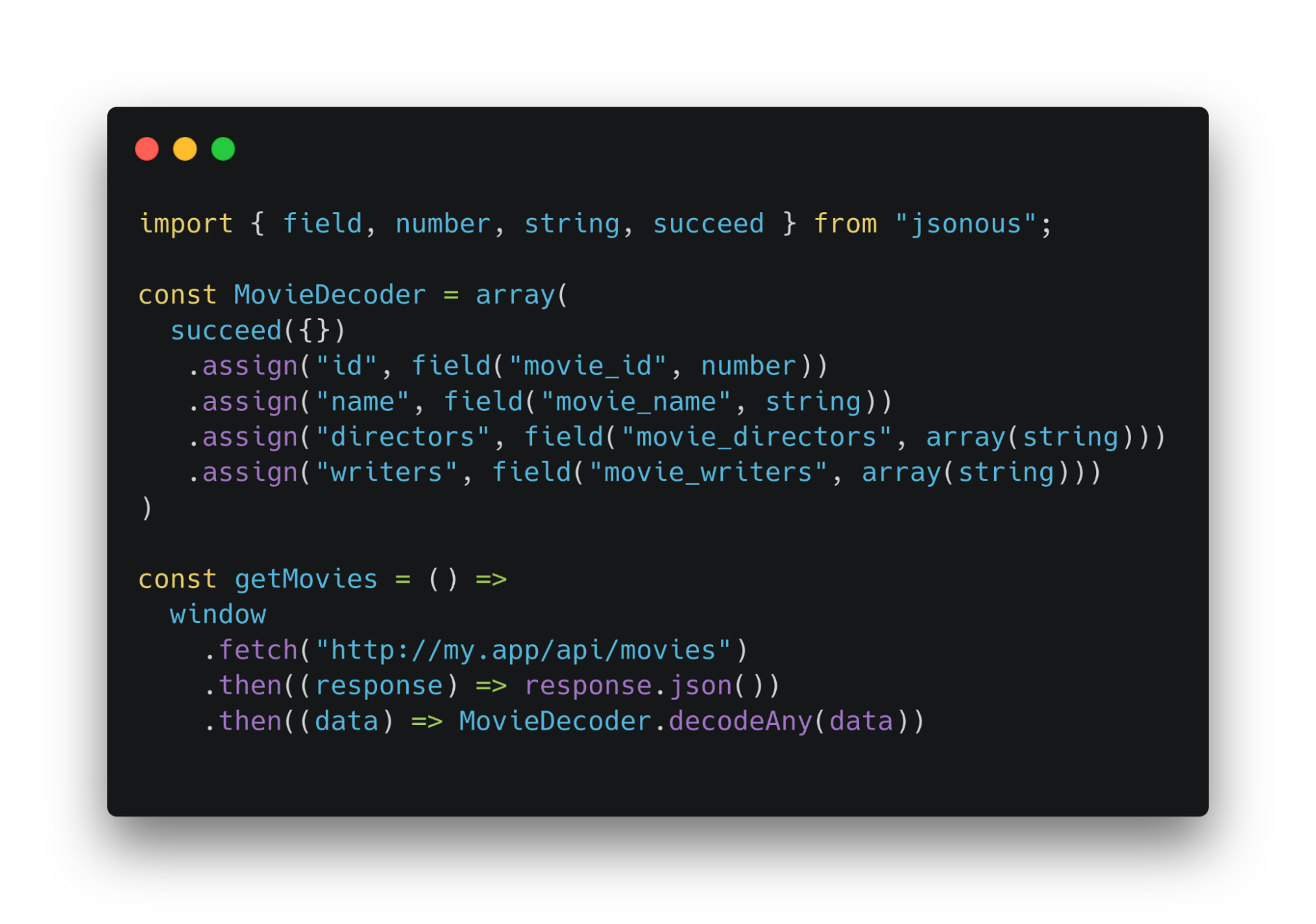
Можно воспользоваться готовым решением. Например, библиотеками io-ts или jsonous. Они предлагают набор уже готовых функций. Позволяют конструировать объекты-декодеры, у которых есть методы. Выступают тайпгардами. Реализация другая, но фундаментально, это та жа система рантайм-проверок.
Организация слоев приложения
Как объединить менеджер запросов с декодерами и трансформаторами?
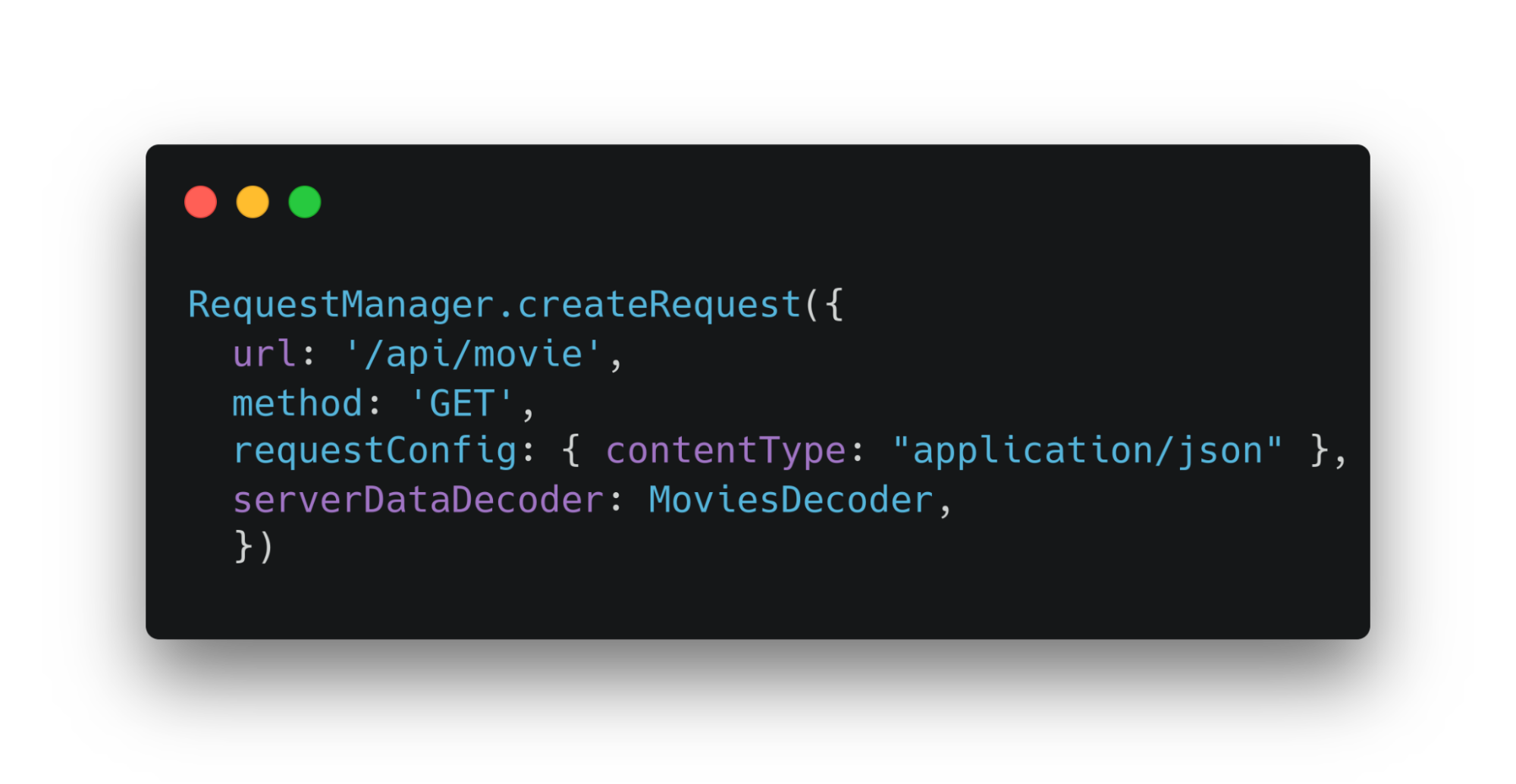
Цель — иметь возможность создавать функции запросов и потом использовать их. При этом получать из вызовов уже преобразованные данные. Для этого необходимо передать декодеры и трансформаторы в метод RequesManager.createRequest.
Используем декодеры, которые написаны на jsonous. Такой декодер будет проверять типизацию DTO в рантайме. Сдекодированные данные будут приходить к нужному интерфейсу.
Достаточно передать декодер в метод createRequest, чтобы объединить его и requestManager. Декодер обработает ответ от сервера. Функция запроса на бэк вернет уже сдекодированные данные. С ними уже можно будет работать. Если возникнет ошибка декодера, то будет передана в миддлвары ошибок.
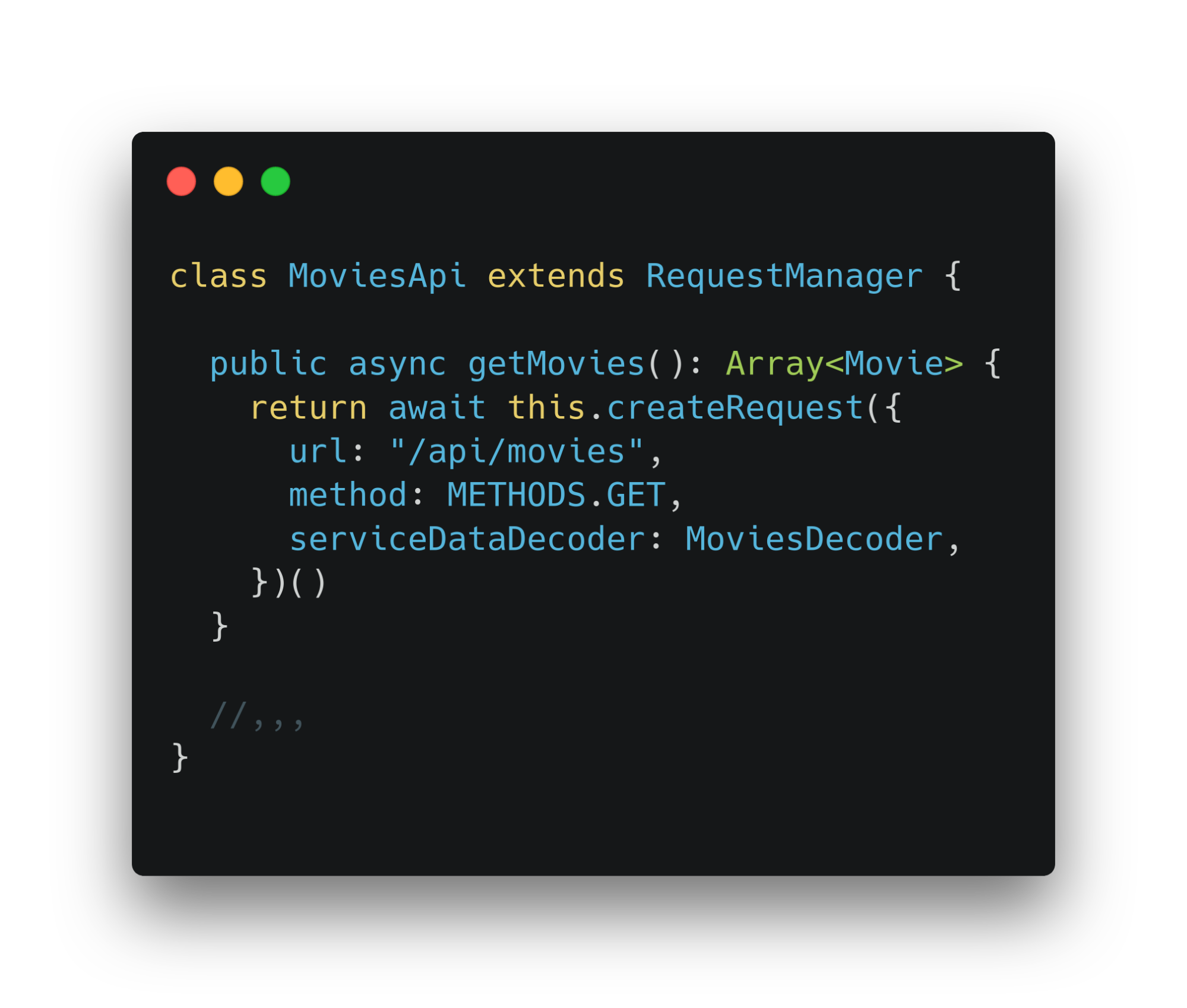
Создадим новый класс, который наследуется от requestManager. В его методах создадим и вызовем функции запросов к бэкенду. Новый класс является адаптером — сущностью, которая соединяет приложение с внешним окружением.

Чтобы понять, как адаптеры встраиваются в приложение, сначала нужно выяснить, из чего приложение состоит. Будем опираться на DDD — Domain Driven Development. Он выделяет 3 слоя — доменный, приложения и инфраструктуры.
Слой домена хранит бизнес-логику и -сущности. Является сердцем всего приложения. Тут происходят работы над данными со стороны фронта.
В нашем примере создадим «глупый» объект MovieEntiity. Бизнес-данные лежат именно здесь.
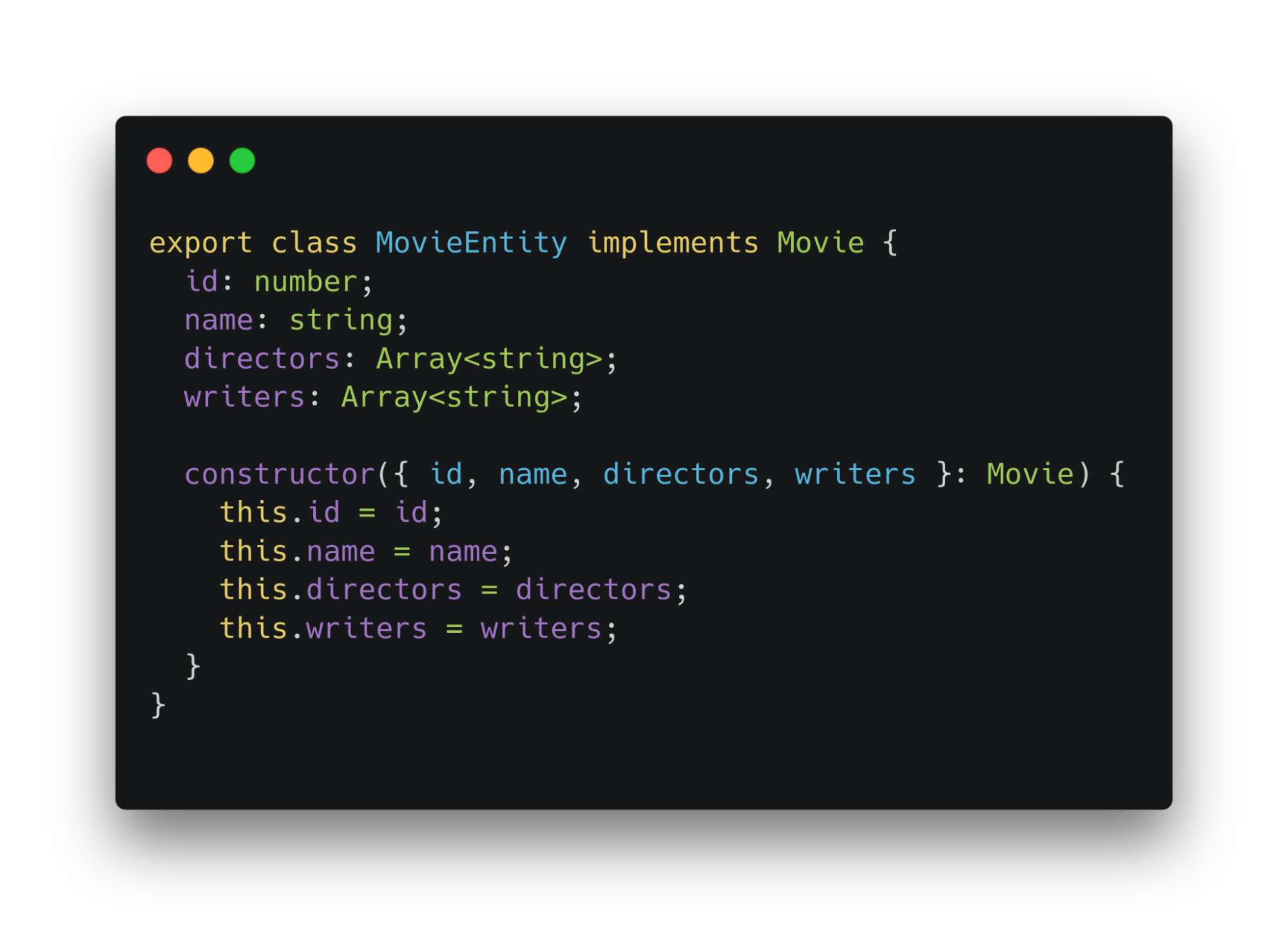
Второй слой — приложения. Здесь находятся классы-сервисы. Хранят инстансы адаптеров и доменных сущностей. Предоставляют методы, а также поля. К ним может обратиться ui. Например, здесь сервис предоставляет геттер. Будет использовать ui для получения фильмов.
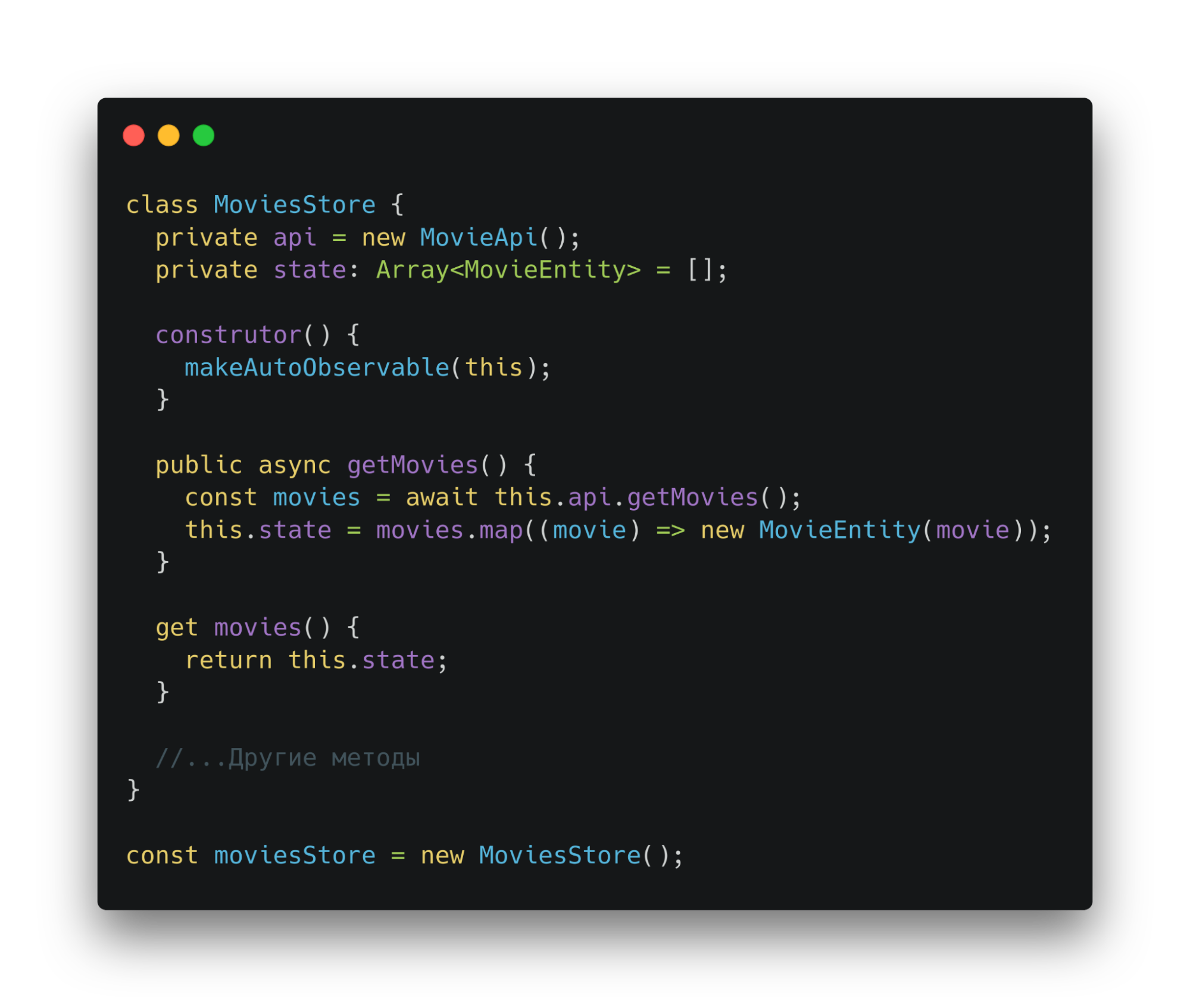

В роли сервиса выступают классы service и store. Хранят инстансы классов доменного и инфраструктурного слоев. UI обращается к сервису и запускает в работу метод. Сервис обращается к необходимым адаптерам и доменным сущностям.
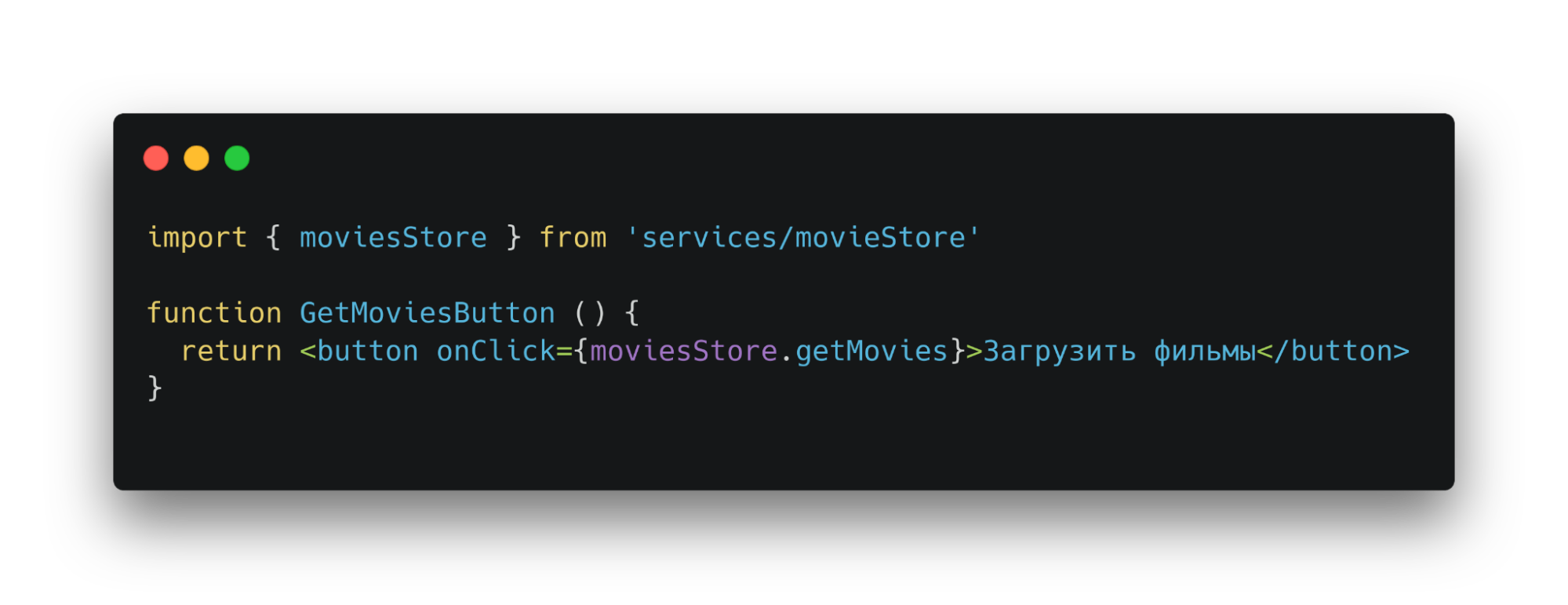
Третий слой — инфраструктуры. Тут лежат различные адаптеры. Отвечают за получение данных из бэкенда или иных внешних источников. Связывают бэкенд с сервисным слоем, который связывает адаптеры и доменный слой. В нашем случае, это api-класс. С ним работает сервис. Данные из него используются для создания доменных сущностей.
Ui является адаптером. Интерпретирует данные, которые вводит пользователь. А также передает сервисам приложения в нужных форматах.
Адаптеры делятся на driving и driven. Driven-адаптеры управляются сервисами, например, api-адаптер. Driving-адаптеры управляют сервисами, например, ui-адаптер.
Таким образом, ui-адаптер запускает методы сервиса, который использует api-адаптеры, чтобы взаимодействовать с бэкендом. Api-адаптеры посылают запрос на бэкенд, декодируют, трансформируют ответ и возвращают на сервис. Тот из этих данных создает доменные сущности.
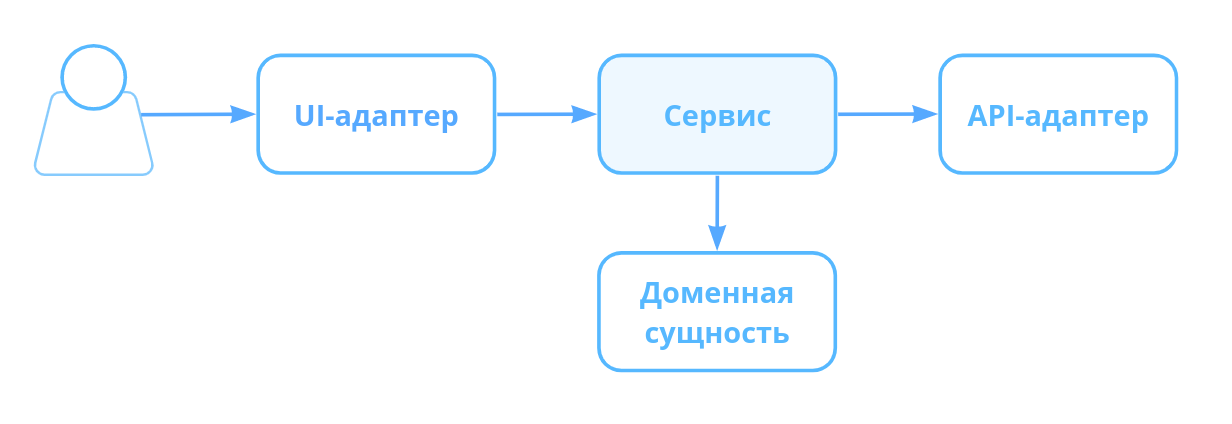
В этой системе, api-адаптер для вызова запросов располагается в слое инфраструктуры. Интерфейсы преобразованных данных лежат на доменном слое, ведь там с ними происходит работа в приложениях.
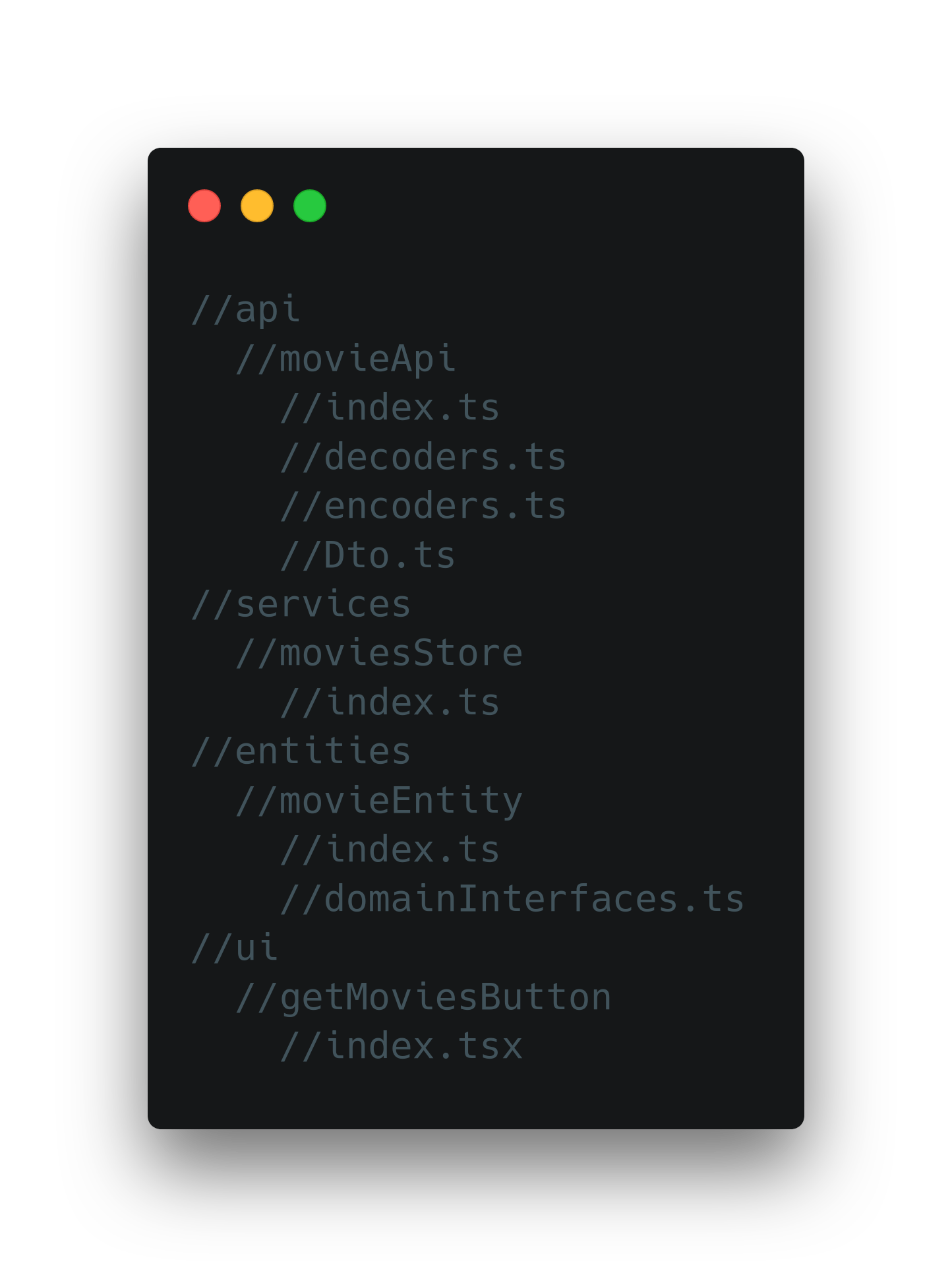
Хранение данных
Пример демонстрирует получение данных отображения. Нужны для показа статичной информации. Давайте посмотрим, как они хранятся и используются в приложении.
В примере выше экспортировали инстанс класса-стора. Создавали его рядом с объявлением. Однако, вынесем создание инстанса в контекст компонента, который его использует. Глобальные состояния заменяются контекстом. Степень зацепления между ui и сервисами уменьшается. Используемые сущности удалятся с анмаунтом компонента.
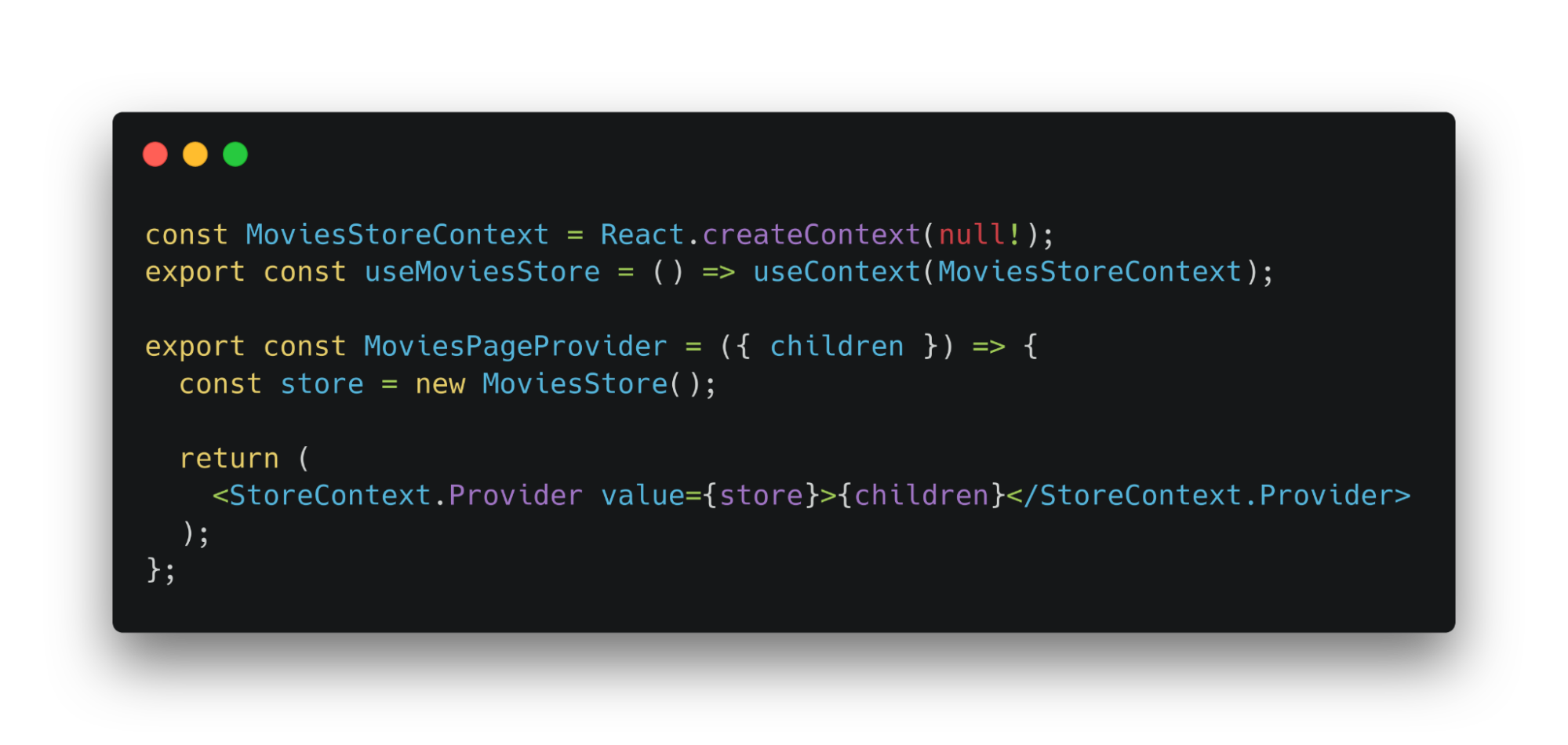
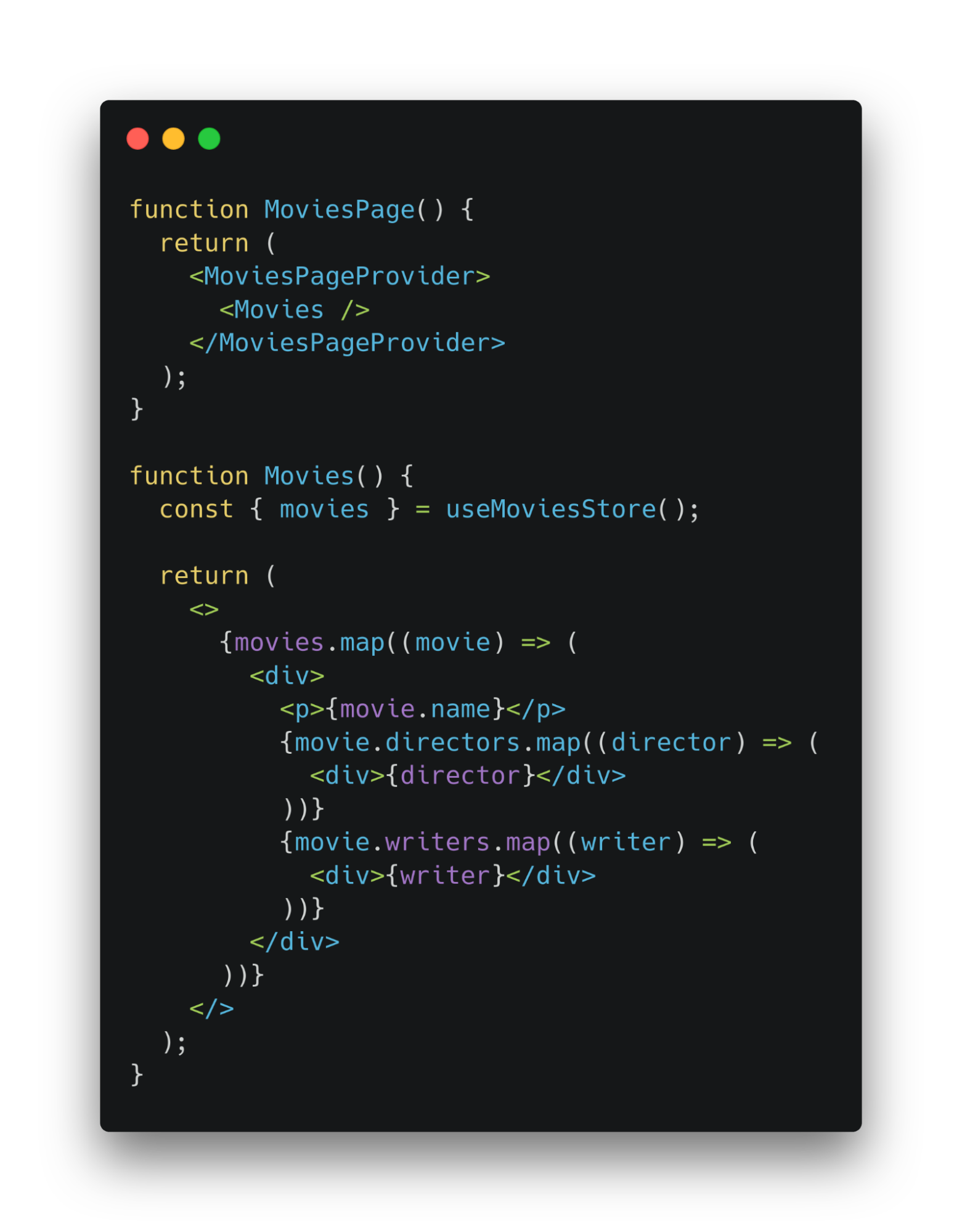
Теперь можно использовать сущности. Их получили через геттер стора.
Что делать, если нужно создать новый фильм? Тогда данные, которые отправляем на бэкенд, должны быть реактивными на фронтенде. Но также должны храниться отдельно от данных ввода. Нам нужна «обертка», которая хранит состояние, обновляет его, позволяет считывать и гарантирует типизацию. Для ее создания используем observable класс библиотеки mobx. Создадим класс Model, от которого будем наследовать «обертки».
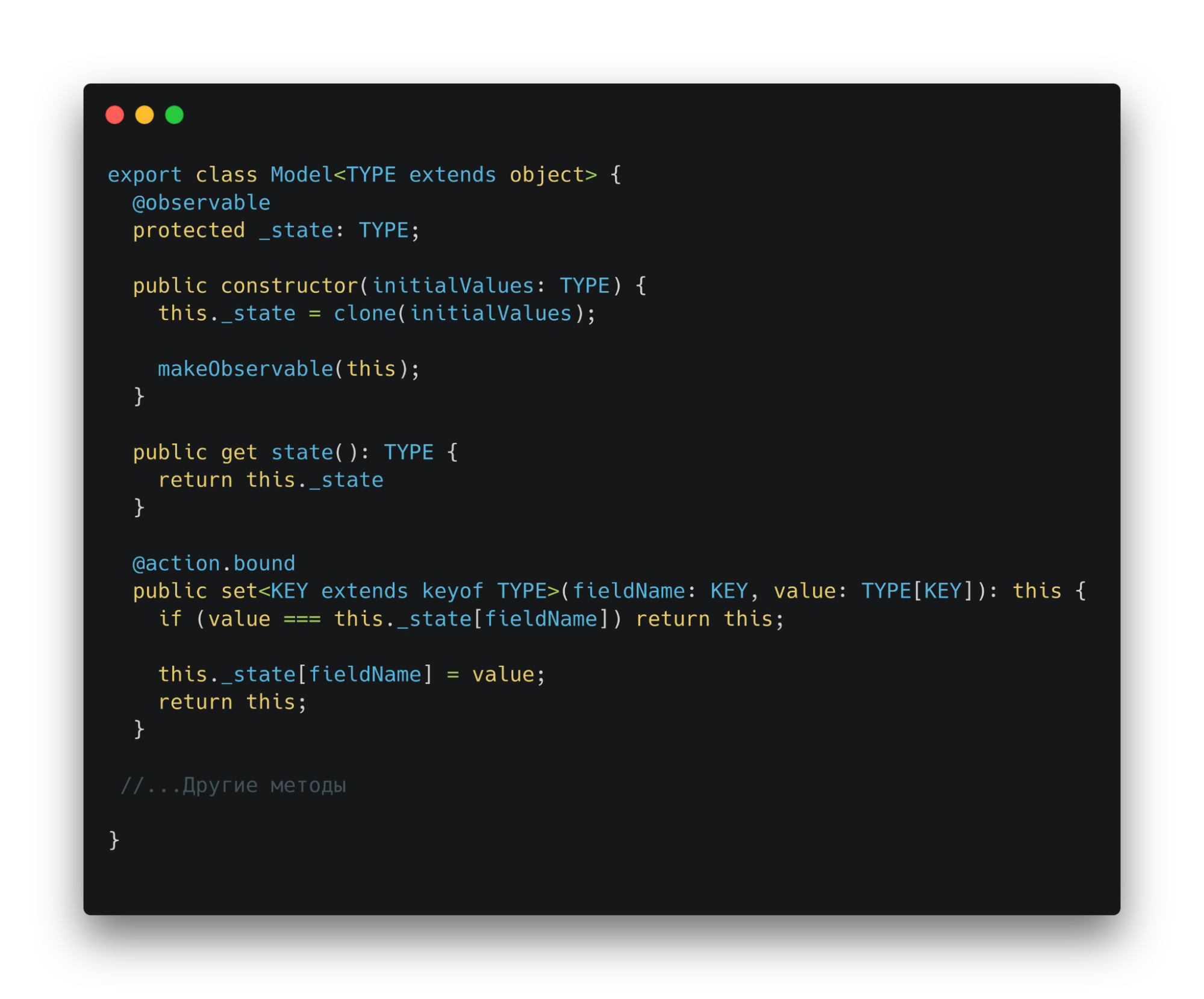
Обновление данных из формы создания происходит в подклассе Model. В конструктор по умолчанию передается объект с пустыми значениями. Это происходит, чтобы создавать готовую модель.
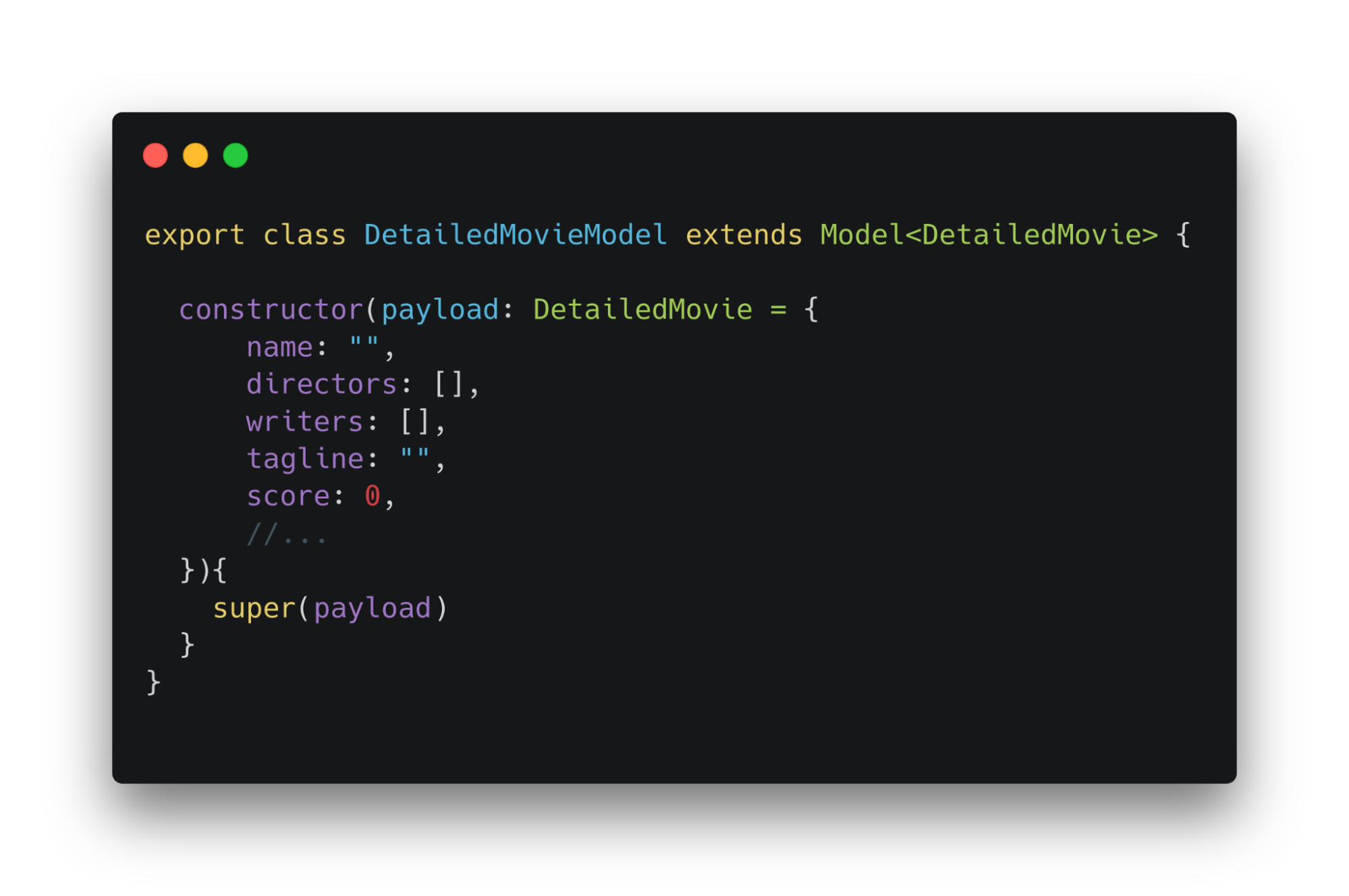
Теперь добавим метод в сервис детального фильма. Он будет отправлять запрос на создание фильма. Обновление данных формы будет реализовываться через использование model.
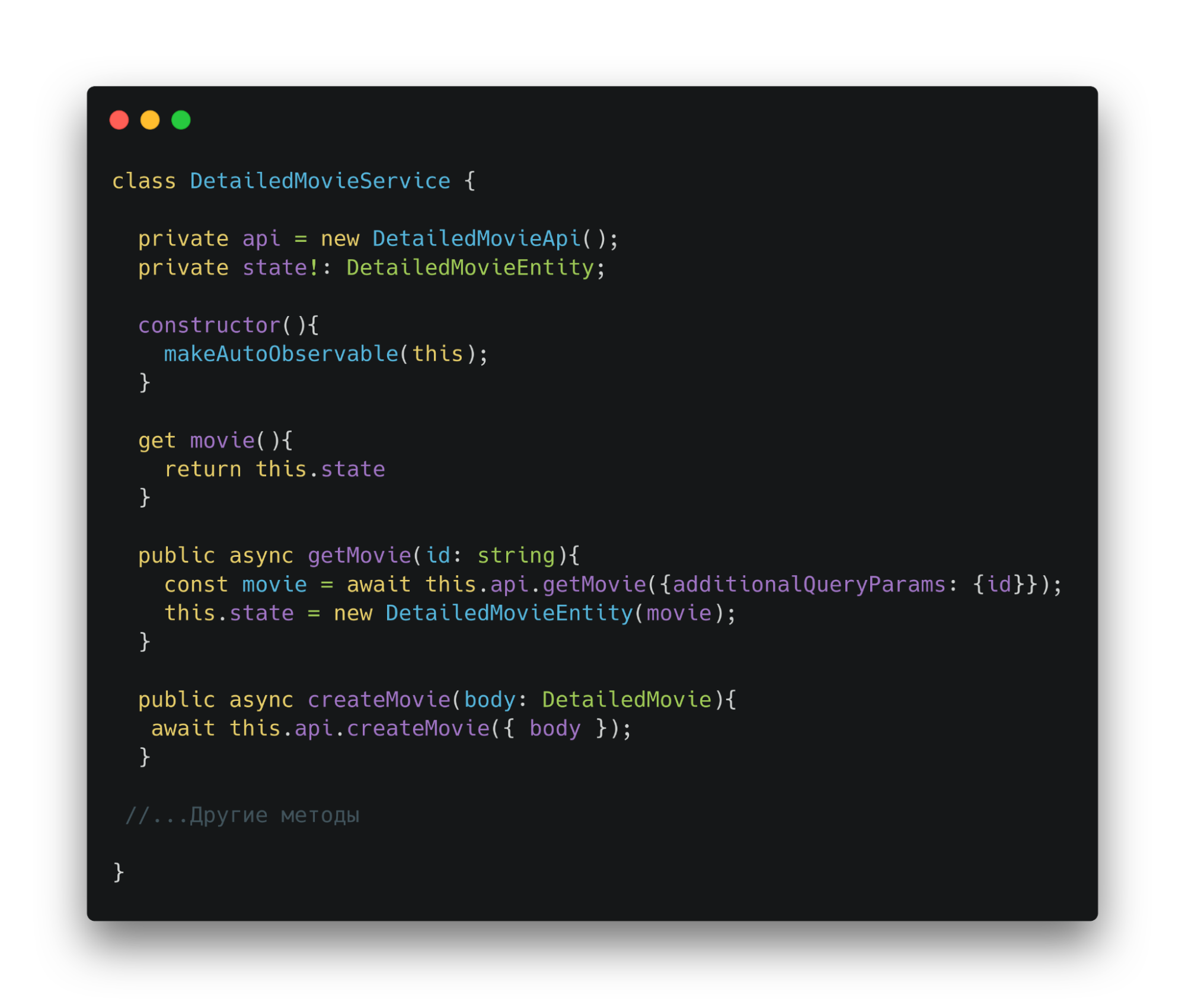
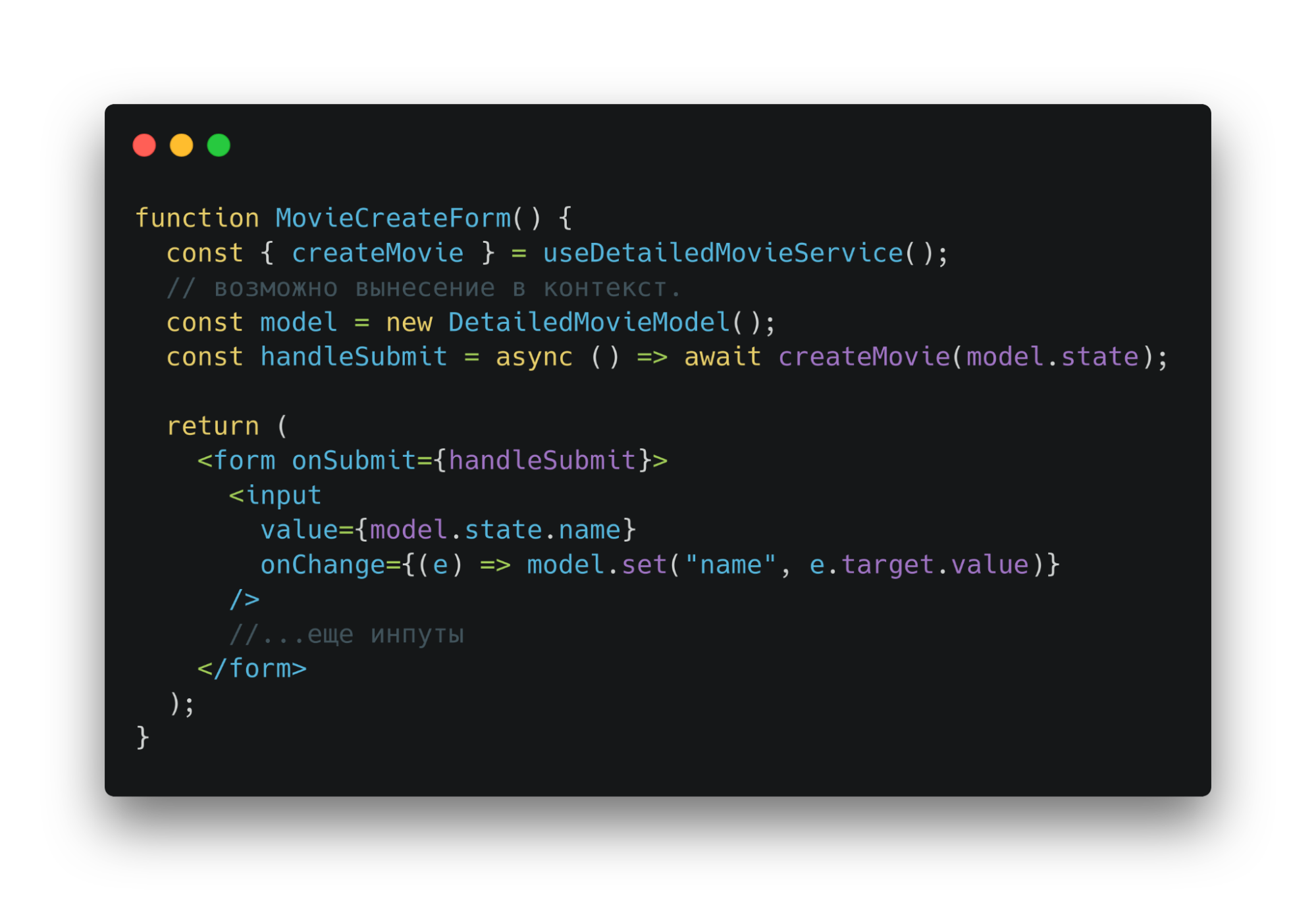
Далее можно использовать model и метод сервиса в ui. Model — часть ui-адаптера. Она хранит и обновляет данные. Потом отправит в метод сервиса.
Если же нужно обновить, например, оценку фильма, можно создать еще один метод сервиса. Он отправит запрос на бэкенд и получит обновленные данные. Далее создаст новую сущность фильма и перезапишет state.
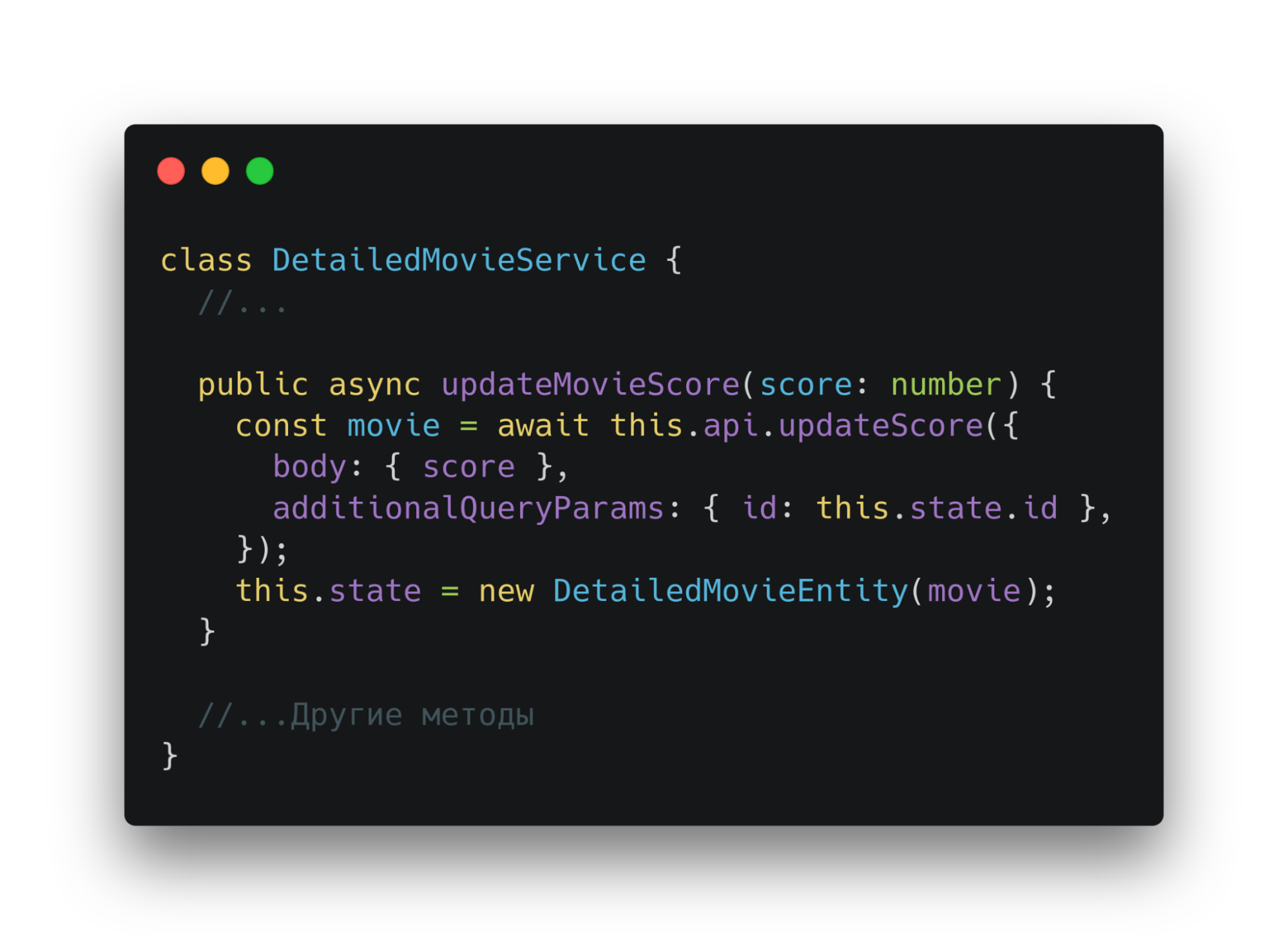
Теперь используем метод сервиса в ui через контекст.
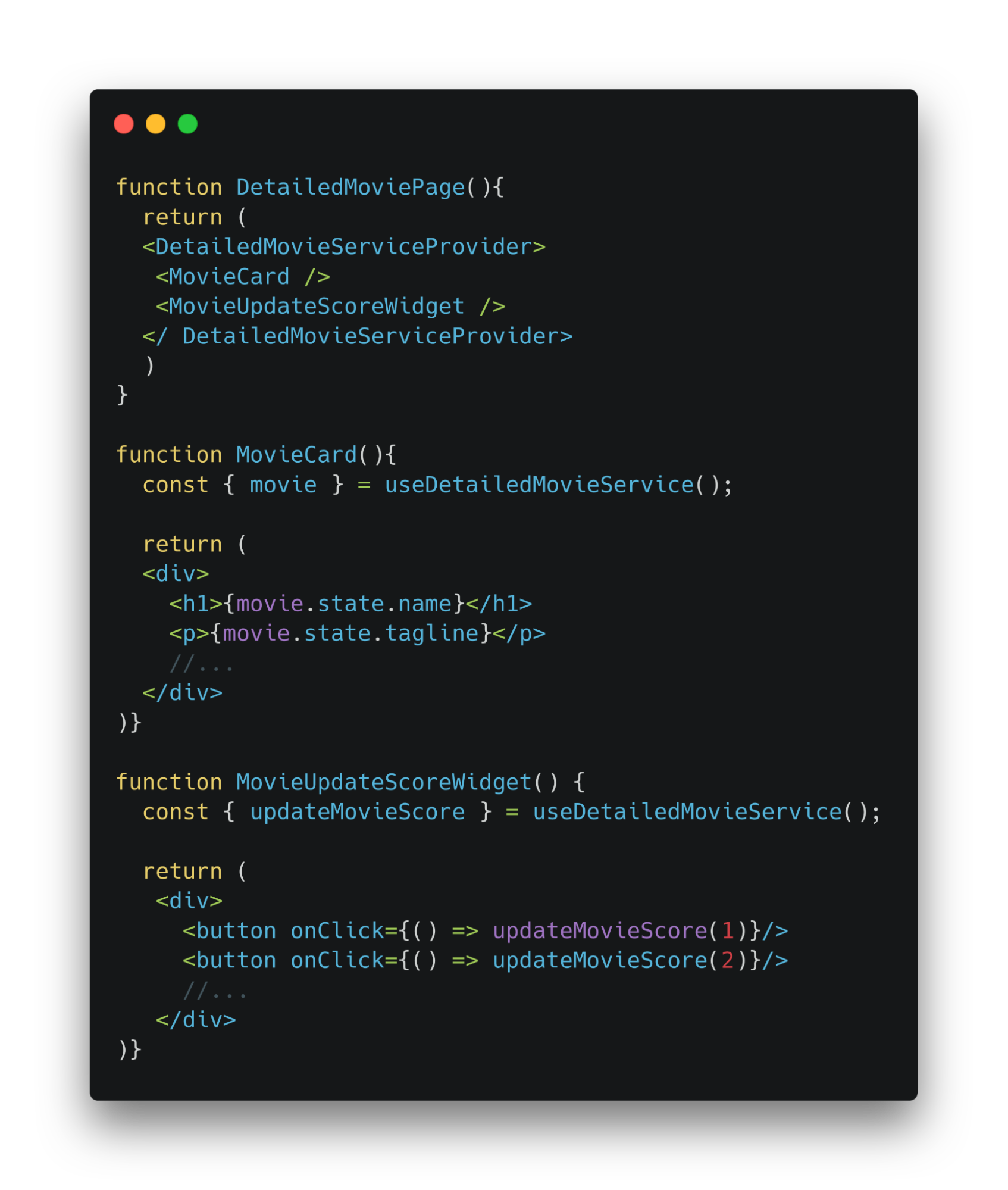
В этом примере данные фильма хранятся в контексте компонента страницы. Но они могут понадобиться всему приложению. Что тогда делать? Есть выход.
Например, данные текущего пользователя хранятся в контексте компонента App, то есть в контексте всего приложения. Можно получить единственный вид с бэкенда, который должен сохраняться между обновлениями страницы.
Есть два пути — в Cookies или в LocalStorage. Куки хранят не более 4096 байт информации. Обычно там находятся данные, нужные серверу, например, токены авторизации.
Если имеем дело с данными, которые нужны только клиентской части приложения, то складываем их в LocalStorage. Например, о выбранной теме приложения или языке.
Вывод
Мы изучили пример организации работы с данными во фронтенд приложении. Из него можно выделить несколько общих советов. Они помогут при разработке:
- Сервис взаимодействия фронтенда с бэкендом должен формировать функции запросов. В них передается конфиг. После чего для отправки запроса нужно всего лишь передать функциям динамические данные при их вызове.
- Реализовывайте миддлвары запросов. Позволяют расширить возможности взаимодействия с сервером. Это происходит без модификации api-класса или возвращаемых им функций;
- Разделяйте структуры данных. Используются во фронт-приложении и приходят с бэкенда. Даже простое разделение интерфейсов объектов бизнес-логики и DTO может спасти от проблем;
- Тайпскрипт не способен типизировать даннные в рантайме. Для этого используйте тайпгарды или готовые библиотеки;
- Приложение важно разделять на слои — инфраструктурный, сервисный и доменный. Инфраструктурный соединяет приложение с бэкендом и ui. Доменный хранит бизнес-данные и реализует бизнес-логику. Сервисный предоставляет точку связи между ними;
- Нужные компонентам данные стоит хранить в их контексте;
- Данные, которые должны сохраняться между обновлениями страницы, храните в Cookies или LocalStorage.
Реализовывать эти советы возможно и с помощью других решений. Например, структуру приложения можно задать через паттерн Model-Constructor-Serialazier или через методологию Feature-Sliced Design. А для декодирования json реально использовать runtypes или кастомные тайпгарды. Но реализация советов, которые предлагаем мы, решит следующие проблемы:
- Позволит упростить и ускорить добавление новых запросов на бэкенд;
- Предоставит возможность быстро расширять функционал работы с запросами;
- Упростит обработку ошибок;
- Ускорит время актуализации фронтенда под изменения бэкенда.
- Увеличит устойчивость фронтенда к изменениям бэкенда;
- Отвяжет этапы обработки данных друг от друга — api-запросы, бизнес-логику и отображение. Это позволит проще и быстрее вносить изменения в процесс работы на любом из этапов;
- Уменьшит вероятность багов, связанных с хранением данных.
С реализацией представленных принципов можно ознакомиться в репозитории, который подготовлен по материалам статьи – здесь.


