

Языковые модели умеют писать код, переводить тексты, анализировать документы. При этом ни одна из них не помнит, о чем вы разговаривали с ней минуту назад. ChatGPT, Claude, DeepSeek — все эти продукты создают иллюзию памяти, хотя в основе каждого лежит языковая модель без единого байта собственных воспоминаний. В Work Solutions мы проектируем и разрабатываем продукты, в основе которых лежат языковые модели, и хорошо понимаем, как превратить «золотую рыбку» в полезный инструмент для бизнеса. В статье разберем, чем LLM отличается от продукта на ее основе, что такое контекстное окно и почему именно работа с контекстом определяет качество любого AI-решения.
Что такое LLM
LLM расшифровывается как Large Language Model, большая языковая модель — это генеративная нейросеть, обученная на большом объеме текста для распознавания паттернов и предсказания наиболее вероятного ответа по контексту. В современном понимании это очень общий термин. Под LLM описывают практически любую генеративную нейросетевую модель, обученную на большом количестве данных.
GPT от OpenAI, Gemini от Google, Claude от Anthropic, DeepSeek от одноименной китайской компании — все это примеры таких моделей. В основе каждой лежит архитектура Transformer, описанная в 2017 году командой Google Brain в статье «Attention Is All You Need». На сегодняшний день эта работа набрала более 173 000 цитирований и стала одной из десяти самых цитируемых научных статей XXI века.
С точки зрения инженера, модель представляет собой математическую функцию. На вход поступает текст, на выходе появляется текст. Между вызовами ничего не сохраняется. Программисты называют такое поведение чистой функцией: один и тот же вход при прочих равных дает один и тот же результат, без побочных эффектов, без состояния. Модель не знает, кто к ней обращается. Не знает, был ли до этого разговор. Каждый вызов API для нее как первый и единственный.
Эксперимент: как проверить, что у LLM нет памяти
Проще всего понять это через прямой вызов API. Откройте документацию OpenAI или Anthropic, отправьте в модель запрос: «Меня зовут Анна». В ответ получите что-нибудь вежливое. Вторым запросом спросите: «Как меня зовут?» Ответом будет: «У меня нет информации о вашем имени».
Попробуйте другой пример. Первый запрос: «Запомни число 42». Второй запрос: «Какое число я просил запомнить?» Модель не сможет ответить. Физически не сможет, потому что второй запрос обрабатывает та же модель, на тех же серверах, но для нее этот запрос абсолютно новый. Никакого «запоминания» не произошло.
Тот же эксперимент в интерфейсе ChatGPT даст противоположный результат. Чат-бот корректно назовет ваше имя и вспомнит число. Возникает вопрос: откуда «память»? Это не новая проблема: еще в ранних обзорах AI-инструментов мы отмечали, что «память» чат-бота обычно реализуется на уровне системы, а не самой модели.
Чем LLM отличается от ChatGPT и других AI-продуктов
GPT — это модель. ChatGPT — продукт, построенный поверх этой модели. Между ними находится слой обычного программного кода, который делает три вещи: хранит историю переписки, упаковывает ее в единый текст при каждом новом сообщении и отправляет этот текст в модель целиком.

Эта разница не абстрактная. Все языковые модели создаются в исследовательских лабораториях. Архитектуры проектируют, датасеты собирают, модели обучают на тысячах GPU. Это работа инженеров по искусственному интеллекту, и она может занимать годы. Результат этой работы и есть LLM: математическая функция, которая принимает текст и выдает текст.
Но между готовой моделью и продуктом, которым пользуются люди, лежит отдельная дистанция. OpenAI выпустила GPT-3 в июне 2020 года. Мы писали о ней в нашем нейродайджесте и уже тогда отмечали, что результаты впечатляют. ChatGPT, продукт на базе этой модели, появился только в ноябре 2022-го, спустя два с половиной года. Все это время модель существовала, работала через API, но продукта для массового пользователя не было.
Что именно добавили разработчики ChatGPT, чтобы превратить модель в продукт? Одну важную вещь: иллюзию памяти.
Представьте справочную службу, где оператор каждые пять минут меняется, но перед ответом новый оператор читает полную распечатку предыдущего разговора. Для клиента все выглядит как непрерывный диалог с одним человеком. В реальности каждый раз новый оператор, с нуля прочитавший всю переписку.
Архитектура чат-продукта выглядит так. Пользователь отправляет сообщение. Программный оркестратор берет все предыдущие сообщения, все ответы модели, добавляет системные инструкции и упаковывает это в один запрос. Модель получает полный текст разговора и генерирует ответ. Оркестратор сохраняет ответ и повторяет цикл при следующем сообщении.
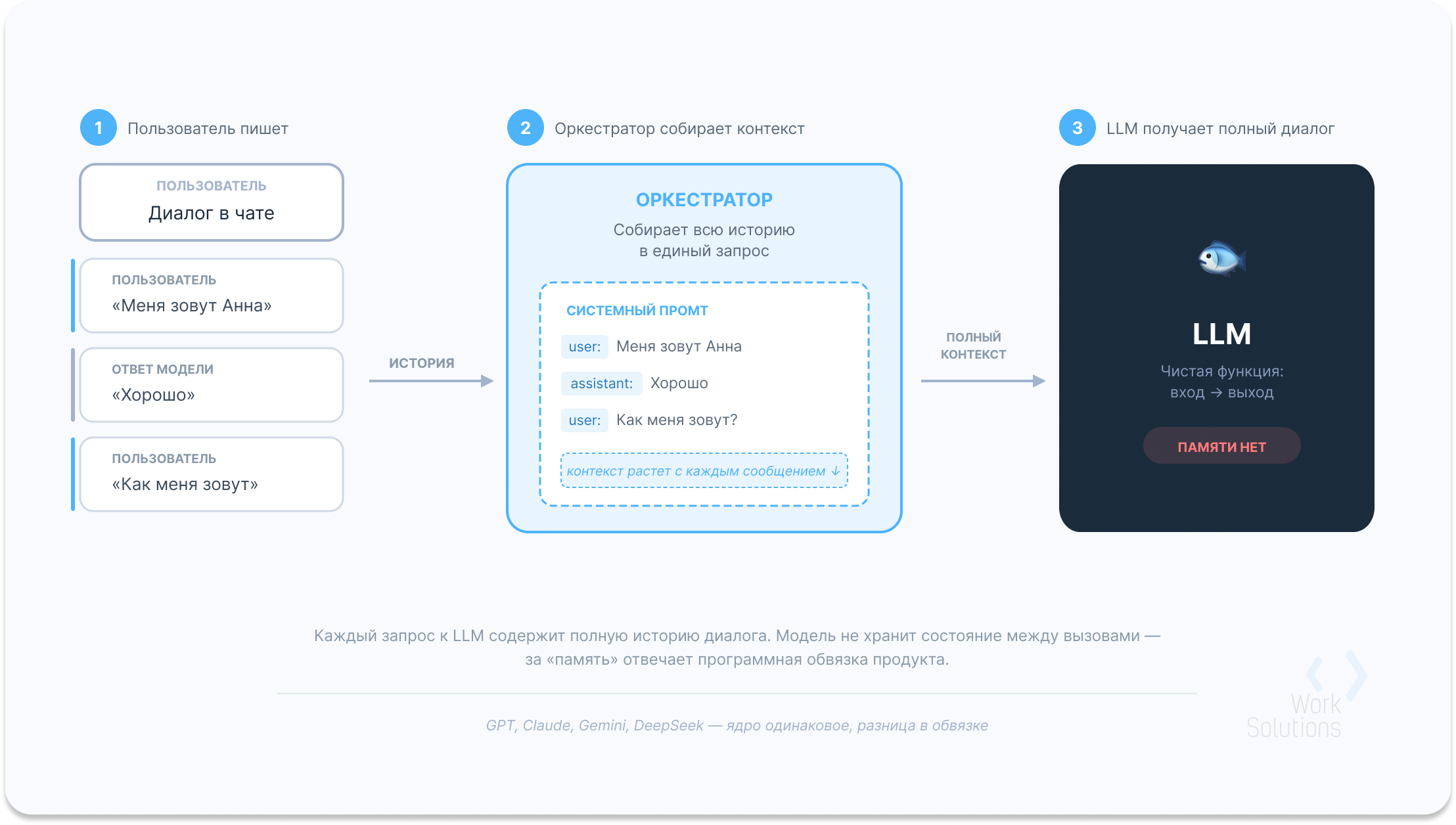
Как чат-продукт создает иллюзию памяти у LLM
Принципиальный момент: сама модель между вызовами не меняется. На серверах OpenAI, Anthropic или Google один и тот же экземпляр модели обрабатывает миллиарды запросов от разных пользователей. Никаких клиентских идентификаторов внутри модели нет. Все «умное» поведение обеспечивает программная обвязка продукта.
Контекстное окно LLM: сколько текста модель может обработать за один раз
У каждой модели есть лимит на объем входного текста. Этот лимит называется контекстным окном и измеряется в токенах.
Токен в контексте LLM — это единица текста, с которой работает модель. Один токен в русском языке равен примерно трем символам. Размер контекстного окна измеряется именно в токенах, а не в символах или словах.
Контекстные окна стремительно выросли за последние четыре года. В 2022 году стандартом считались 4 096 токенов. К началу 2026-го лидеры рынка предлагают от 200 000 до 10 миллионов. На стандартной странице А4 помещается около 1 800 символов. В таблице ниже собраны актуальные размеры контекстных окон с пересчетом в привычные единицы.
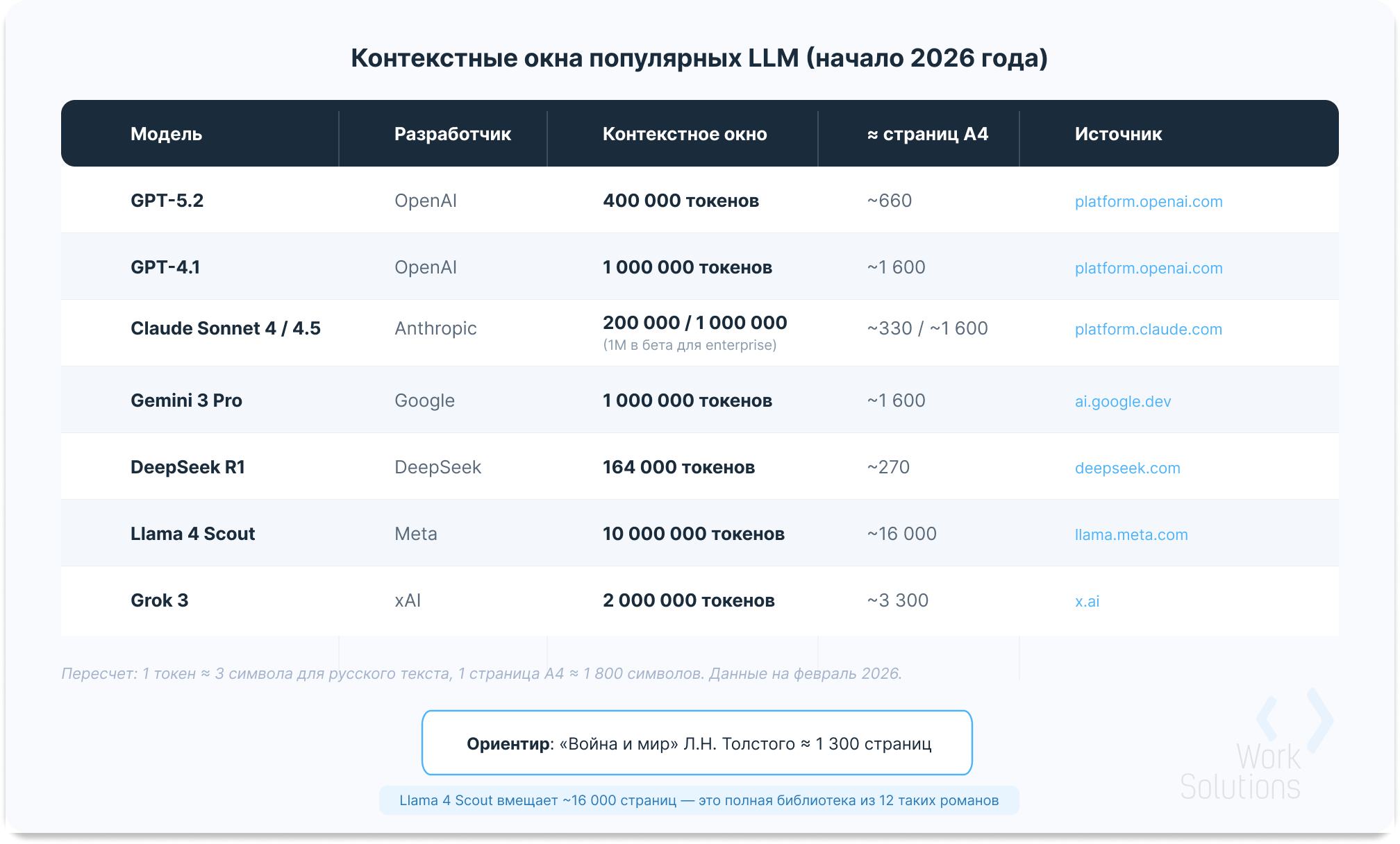
Контекстные окна популярных LLM в начале 2026 года: заявленные лимиты и примерный пересчет в страницы A4
Каждое новое сообщение в чате увеличивает контекст. К исходному промпту добавляются предыдущие реплики пользователя и ответы модели. Контекст растет линейно: десять обменов репликами могут занять 5 000 токенов, сто обменов могут вырасти до 50 000. В определенный момент контекст упирается в потолок окна.
Почему большое контекстное окно LLM не гарантирует качество
Маркетинговые цифры контекстного окна и реальная полезность не совпадают. Разработчик Грег Камрад в 2023 году предложил тест «Needle in a Haystack» (рус: иголка в стоге сена): в длинный текст вставляется один конкретный факт, а модель должна его найти. Тест стал стандартным бенчмарком для оценки длинного контекста. Его репозиторий на GitHub набрал более двух тысяч звезд, а результаты тестирования показали неутешительную картину.
На коротком контексте до 50 000 токенов большинство моделей находят «иголку» с точностью выше 90%. По мере роста контекста точность падает. Исследователи из Chroma Research в 2025 году ввели термин context rot для описания этого явления и показали, что деградация ускоряется на задачах сложнее простого лексического поиска.
Команда Adobe в феврале 2025 года опубликовала исследование NoLiMa, где «иголкой» был факт, требующий умозаключения: «Юки живет рядом с Земперовским оперным театром», а вопрос звучал «Какой персонаж бывал в Дрездене?». На коротких промтах модели справлялись в 90% случаев. На промтах в 32 000 токенов точность падала до 40-60%.
Отдельную проблему представляет позиционное смещение. Группа исследователей под руководством Нельсон Ф. Лью, Кевин Лин, Джон Хьюитт и др. в работе «Lost in the Middle» 2024 года показала, что модели лучше всего находят информацию в начале и в конце контекста, а середину «теряют». Эта U-образная кривая внимания проявляется у большинства моделей.
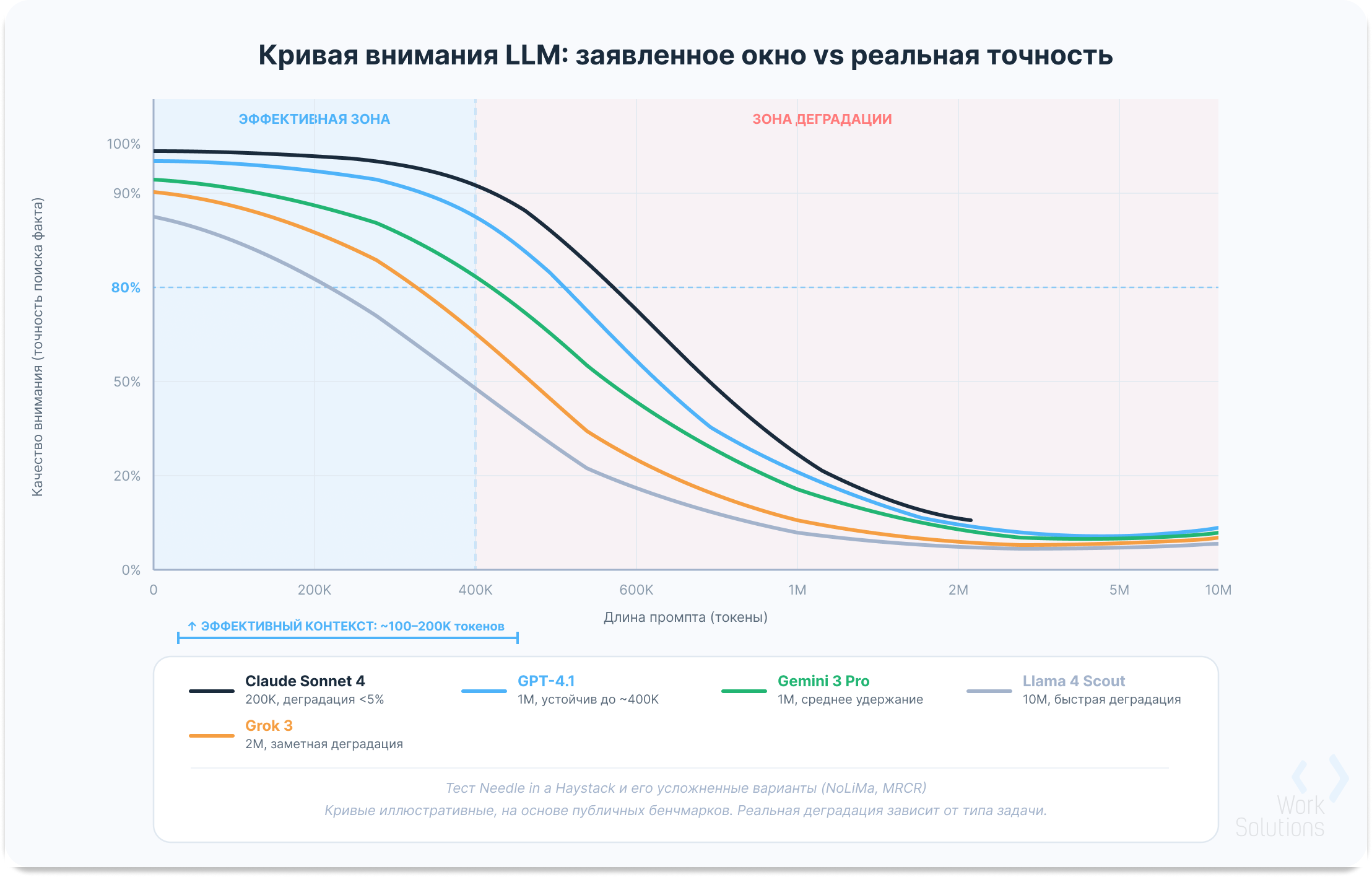
График деградации качества внимания LLM при увеличении длины промпта
Из этих наблюдений рождается понятие эффективного контекстного окна. Модель может принять на вход два миллиона токенов, но надежно работает только на первых 100 000 — 150 000. Остальной объем попадает в зону риска, где факты теряются, а качество ответов падает.
Плотность контекста в LLM: когда короткий промпт сложнее длинного
Размер контекста не единственный фактор. Существует менее очевидная характеристика: плотность ограничений внутри промпта.
Представьте задачу: сгенерировать картинку по фотографии в мультяшном стиле с теплыми тонами, но сохранить портретное сходство с человеком. Модель справляется. Дальше начинаются правки. «Сделай дерево на фоне крупнее». Готово. «Облака перекрась в голубой». Окей. «Убери машину справа». «Добавь лавочку на переднем плане». «Верни прежний оттенок кожи, он поменялся». К пятому сообщению модель держит в голове: стиль, палитру, сходство с оригиналом, размер дерева, цвет облаков, отсутствие машины, наличие лавочки и оттенок кожи. Промпт занимает полстраницы, а вычислительная нагрузка растет с каждым условием.
Каждое новое ограничение сужает пространство допустимых результатов. Модель на каждом шаге генерации проверяет соответствие всем правилам одновременно. На практике после 8–10 накопленных условий что-то начинает ломаться: дерево уменьшается обратно, машина возвращается, оттенок кожи снова уходит в холодный. Контекстное окно еще далеко от лимита, но плотность ограничений уже превышает возможности модели.
В разработке ситуация аналогичная. Если техническая спецификация содержит 40 взаимосвязанных требований к одному компоненту, модель начнет терять часть из них задолго до исчерпания контекстного окна.
Как работает LLM: генерация текста по токенам
Разберем механику на простом примере. Запрос: «Посоветуй, куда поехать в отпуск в марте». Модель не выдает готовый ответ целиком. Генерация идет по одному токену за цикл, как если бы человек печатал текст по одному слову.
Первый цикл: модель обрабатывает запрос и выдает «В». Второй цикл: на входе уже запрос плюс «В», выдает «марте». Третий: «хорошо». Четвертый: «подойдет». Слово за словом складывается фраза «В марте хорошо подойдет Шри-Ланка...», и на каждом шаге модель заново перечитывает все, что было до этого: и исходный вопрос, и все уже сгенерированные слова.
Чем длиннее ответ, тем больше «перечитывания» на каждое новое слово. Вычислительные затраты растут с каждым токеном. Фиксированная архитектура нейросети определяет объем вычислений за один проход. Общие затраты равны произведению вычислений за один цикл на количество циклов.
Из этого следует практически полезный вывод. Два отдельных запроса дают модели вдвое больше вычислительного ресурса, чем один длинный запрос с двумя задачами. Если сначала попросить модель составить план, а затем в новом запросе написать код по этому плану, результат окажется лучше, чем при решении обеих задач одним промптом.
Что происходит при переполнении контекста в LLM-продукте
Типичный сценарий. Разработчик использует AI-помощника для написания кода. Первые 20 сообщений все работает отлично. На 50-м сообщении модель начинает «забывать» ранние договоренности. На 100-м путает имена переменных, теряет архитектурные решения, принятые в начале диалога.
Это не ошибка модели. Это деградация контекста: ранние сообщения оказываются в «мертвой зоне» внимания, и модель перестает их учитывать.
Современные чат-продукты решают проблему переполнения контекста несколькими способами, и у каждого свои компромиссы.
Скользящее окно. Самый простой вариант. Рамка контекста сдвигается вперед, ранние сообщения удаляются. Дешево в реализации, но теряет все детали из удаленных фрагментов: имена переменных, числовые значения, принятые решения.
Суммаризация. Оркестратор периодически просит модель сжать историю диалога в короткий пересказ и подставляет его вместо полной переписки. Экономит токены, но неизбежно теряет нюансы: конкретную формулировку требования, точную цифру из ранних обсуждений, контекст принятого решения.
RAG (Retrieval Augmented Generation). Удаленные фрагменты индексируются во внешнем векторном хранилище. Когда пользователь задает вопрос, система ищет релевантные куски прошлых сообщений и подставляет их в контекст. Работает хорошо для фактов, но не гарантирует, что нужный фрагмент окажется в выборке.
Персистентная память. ChatGPT и Claude умеют извлекать ключевые факты из разговоров и сохранять их между сессиями: имя пользователя, предпочтения, рабочий стек. При новом диалоге эти факты автоматически добавляются в контекст. Подход решает проблему долгосрочного контекста, но хранит только то, что система сочла важным.
Селективная очистка контекста. Anthropic в документации к Claude описывает механизм выборочного удаления из контекста результатов вызова инструментов и промежуточных рассуждений модели. Вместо удаления целых сообщений система убирает технический «мусор», сохраняя пользовательский диалог нетронутым.
Ни один из подходов не решает проблему полностью. На практике зрелые продукты комбинируют несколько техник: скользящее окно плюс RAG, суммаризация плюс персистентная память. Задача инженера в том, чтобы выбрать правильную комбинацию под профиль продукта.
Практические приемы работы с контекстом: как снизить деградацию в LLM-чатах
Понимание механики контекстного окна дает набор конкретных инструментов для повседневной работы.
Одна задача в одном чате. Длинные диалоги неизбежно приводят к деградации контекста. Для каждой подзадачи лучше создавать отдельный чат. Результат предыдущего чата переносится в новый как входные данные.
Декомпозиция перед выполнением. Сначала просите модель составить план. Затем решайте каждый пункт плана отдельным запросом. Модель получает больше вычислительного ресурса на каждый этап, а контекст остается чистым.
Краткое описание проекта в начале каждого чата. Полстраницы текста с описанием задачи, стека технологий и текущего этапа. Такое описание занимает 200-300 токенов, но позволяет модели понять общую картину без загрузки всей истории.
Сохранение артефактов вне чата. Промежуточные результаты, будь то документы, фрагменты кода или спецификации, сохраняйте в отдельных файлах и подключайте к новым чатам по мере необходимости. Это позволяет оставаться в рамках эффективного контекстного окна.
Если модель начала «путаться» в деталях или противоречить ранним договоренностям, это сигнал к тому, что контекст переполнен. Создайте новый чат, перенесите туда актуальное описание задачи и последний рабочий артефакт.
Иерархия AI-продуктов: от чата до автономного агента
Разобравшись в основах, можно выстроить иерархию продуктов на базе языковых моделей.
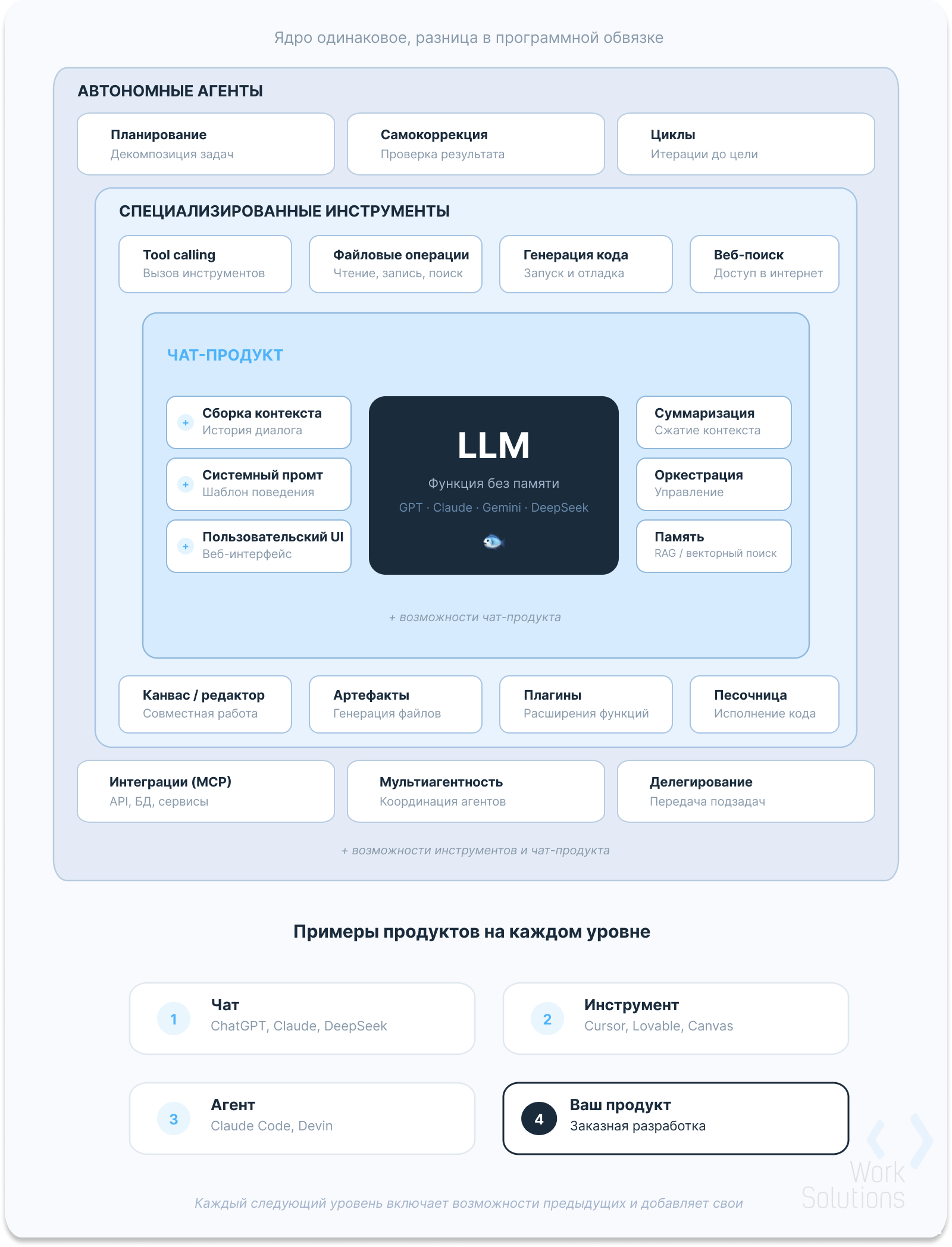
Иерархия AI-продуктов: от чат-интерфейса к инструментам и автономным агентам поверх одной и той же LLM
Базовый уровень — чат. Он берет на себя сборку контекста, отправку запросов и отображение ответов. ChatGPT, Claude, DeepSeek Chat работают по этому принципу.
Следующий уровень — специализированные инструменты. Канвасы для совместного редактирования, конструкторы интерфейсов вроде Lovable, кодерские помощники вроде Cursor. Каждый добавляет к базовому чату свою логику: управление файлами, вызов инструментов, интеграции с внешними сервисами.
Вершина — автономные агенты. Они самостоятельно декомпозируют задачи, выбирают инструменты, проверяют результаты и корректируют план. Claude Code, Devin и подобные системы относятся к этой категории.
Переход от чата к инструментам и агентам невозможен без стандартного способа подключения внешних систем. Именно эту задачу решает протокол MCP (Model Context Protocol). В ноябре 2024 года Anthropic представила его как открытый стандарт для подключения языковых моделей к внешним системам: базам данных, API, файловым хранилищам, CRM и другим сервисам. До MCP каждая интеграция требовала отдельного коннектора: подключить модель к Google Drive — один код, к Slack — другой, к внутренней базе — третий. MCP решает эту проблему так же, как USB-C решил проблему кабелей: один стандартный интерфейс вместо десятков проприетарных.
К началу 2026 года MCP поддерживают OpenAI, Google DeepMind и Microsoft. В декабре 2025 года Anthropic передала протокол в Agentic AI Foundation под управлением Linux Foundation. На GitHub появилось более 13 000 MCP-серверов. Протокол стал стандартом де-факто для подключения агентов к внешнему миру, и именно он делает возможным переход от простых чатов к полноценным автономным системам.
На каждом уровне ядро одно и то же — языковая модель без памяти. Разница исключительно в программной обвязке, и именно она определяет возможности и ограничения конечного продукта.
Разработка продуктов на базе LLM: что нужно знать

Создание продукта на основе языковой модели не требует знаний в области машинного обучения или нейронных сетей. Модель представляет собой готовый движок, доступный через API. Задача разработчика в том, чтобы построить вокруг этого движка продуктовую логику: управление контекстом, оркестрацию запросов, интеграцию с внешними системами, пользовательский интерфейс. Все это стандартная алгоритмическая работа.
Модели постоянно обновляются. GPT сменяется новой версией, Claude получает расширенное контекстное окно, Gemini улучшает плотность внимания. Фундаментальный принцип остается прежним: языковая модель — чистая функция без памяти, а «человеческое» поведение обеспечивает инженерная обвязка.
В Work Solutions накоплен опыт проектирования решений, где языковая модель выступает ядром продукта. Управление контекстом, оркестрация вызовов, интеграция с бизнес-системами решаются понятными инструментами и проверенными архитектурными паттернами. Если вашему бизнесу нужен продукт на базе LLM, будь то интеллектуальный чат-бот или автономный агент, оставьте заявку ниже. Расскажем, какое решение подойдет под вашу задачу, и поможем создать продукт, который будет работать.

