Похоже, не один наш дайджест не обходится без упоминания разработок Open AI: в июле самой обсуждаемой темой в области машинного обучения стал новый алгоритм GPT-3. Технически это не одна модель, а целое семейство, которое для удобства обобщают под единым названием. В самой крупной модели используется 175 млрд параметров, а для обучения использовался датасет размером 570 Gb, в который вошли отфильтрованные данные из архивов Common Crawl и высококачественные данные WebText2, Books1, Books2 и Wikipedia.
Здесь стоит отметить, что модель предобучена, и не требует файн тюнинга под конкретные задачи: для достижения лучших результатов рекомендуется предоставлять ей хотя бы один (one-shot) или несколько (few-shot) примеров решения задач на входе, но можно обойтись вообще без них (zero-shot). Чтобы модель сгенерировала решение задачи, достаточно описать задачу на английском языке. Принято считать, что это алгоритм генерации текстов, но уже видно, что потенциал намного богаче.
Модель была представлена еще в мае, уже тогда Open AI продемонстрировали, что обученная на репозиториях GitHub GPT-3 способна успешно генерировать код Python, и вот, спустя полтора месяца первые счастливчики получили доступ к API и показали свои наработки. Результаты просто потрясающие. Нам, как разработчикам, конечно же, интересно, насколько этот алгоритм упростит нашу жизнь, а может, и создаст конкуренцию.Уже появился сервис debuild.co, который по текстовому описанию функции создает работающий код и неплохо верстает.
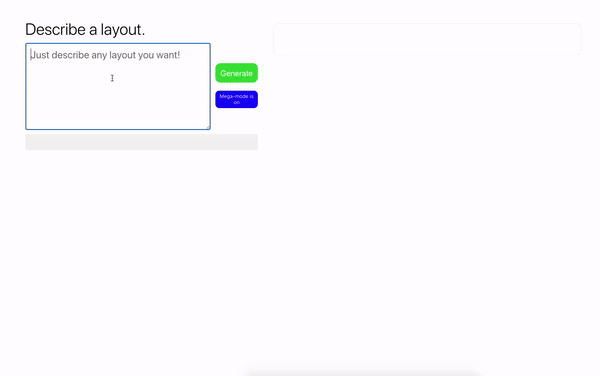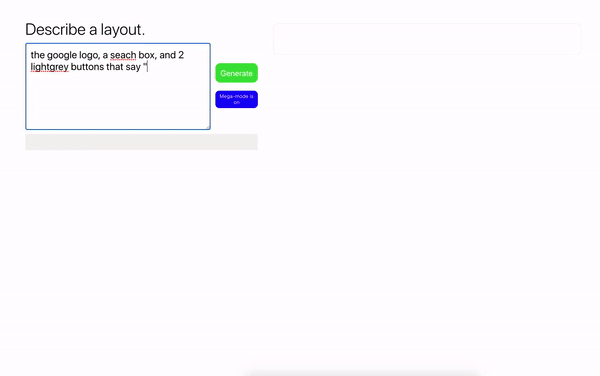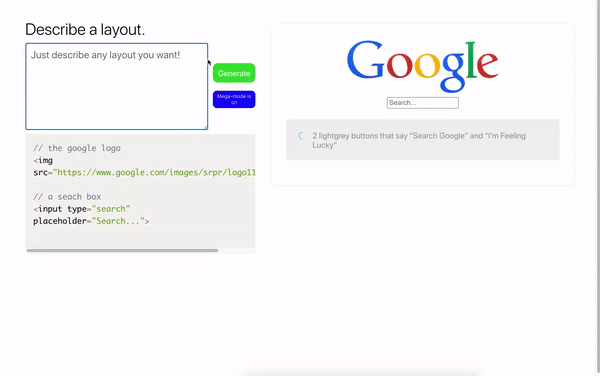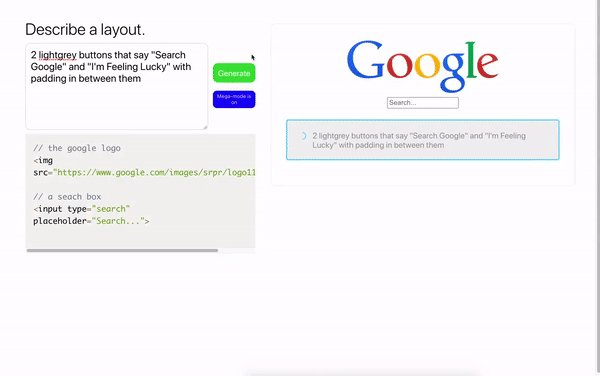
Использовать наработки можно не только в веб-программировании, но и в дизайне. Модель способна по текстовому описанию генерировать JSON данные и переводить их в макет Figma.
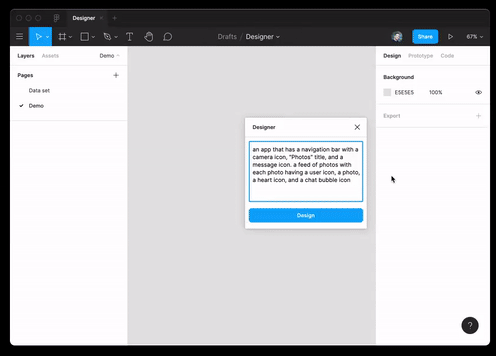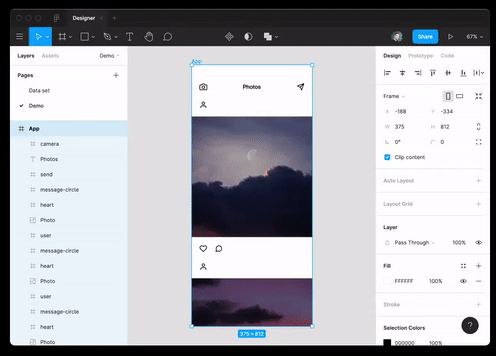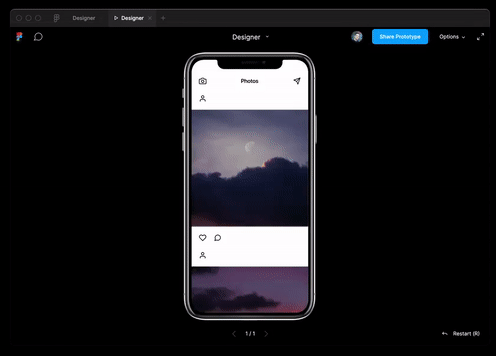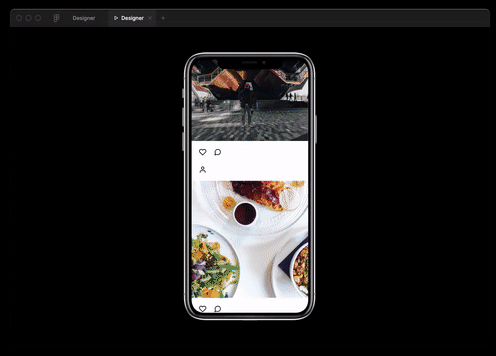
А также ей практически удалось пройти собеседование на должность Ruby-разработчика.
На этом новости об использовании машинного обучения в программировании не заканчиваются.
TransCoder
Миграция кодовой базы с архаичного языка программирования, такого как COBOL, на современную альтернативу, вроде Java или C++, является сложной, ресурсоемкой задачей, требующей от специалистов владения обеими технологиями. При этом архаичные языки по сей день используется в мэйнфреймах по всему миру, из-за чего перед владельцами часто возникает сложный выбор — либо вручную переводить кодовую базу на современный язык, либо продолжать поддерживать легаси-код.
Facebook представил самообучающуюся модель с открытым исходным кодом, которая поможет облегчить эту задачу. Это первая система, способная переводить код с одного языка программирования на другой, не требуя параллельных данных для обучения. По оценкам создателей, модель правильно переводит более 90% функций Java в C++, 74,8% функций C++ в Java и 68,7% функций из Java в Python. Что выше показателей коммерческих аналогов.
ContraCode
Инструменты разработки все чаще используют машинное обучение для понимания и изменения написанного человеком кода. Главная сложность при работе алгоритмов с кодом заключается в нехватке размеченных наборов данных.
Исследователи из Беркли предлагают решить эту проблему с помощью метода ContraCode. Авторы считают, что программы с одинаковой функциональностью должны обладать одинаковыми репрезентациями, и наоборот. Поэтому они генерируют варианты кода для сравнительного обучения (Contrastive Learning). Для создания данных переименовывают переменные, переформатируют и обфусцируют код.
В дальнейшем, самообучаемая по такому методу модель, сможет предсказывать типы, определять ошибки, проводить суммаризацию кода и т.д. Учитывая эти и другие достижения в области, возможно, в скором времени машины научаться писать код не хуже людей.
DeepSIM

Авторы этого исследования показывают, что генеративно-состязательная сеть на одном целевом изображении способна справляться со сложными манипуляциями.
Модель учится сопоставлять примитивное представление изображения (например, только края предметов на фото) с самим изображением. Во время манипуляции генератор позволяет модифицировать изображения, изменяя их примитивное представление на входе и мэппируя его через сеть. Этот подход решает проблему DNN, которая требует огромного набора данных для обучения. Результаты впечатляют.
3D Photo Inpainting

Очередной способ преобразования двухмерных RGB-D изображений в трехмерные. Алгоритм воссоздает области, которые скрыты объектами на оригинальном изображении. В качестве базового представления использовалось многослойное изображение глубины, на основе которого модель итеративно синтезирует новые данные о цвете и глубине для невидимой области с учетом контекста. На выходе получаются фотографии, к которым можно добавить эффект параллакса с помощью стандартных графических движков. Доступен колаб, где можно протестировать модель самостоятельно.
HiDT

Команда российских исследователей представила алгоритм с открытым исходным кодом, который меняет время суток на фотографиях. Моделирование изменений освещения на фотографиях с высоким разрешением является сложной задачей. Представленный алгоритм сочетает в себе генеративную модель image-to-image и схему апсемплинга, которая позволяет производить преобразования на изображениях с высоким разрешением. Важно отметить, что модель обучалась на статических изображениях разных ландшафтов без временных меток.
Swapping Autoencoder

Если HiDT умеет качественно изменять освещение на изображениях, то эта нейронная сеть, обученная на разных наборах данных, способна менять не только время суток, но и ландшафт. К сожалению, возможности посмотреть исходный код нет, поэтому остается только восхищаться видео, которое демонстрирует возможности этой модели.
SCAN
Нейронная сеть с открытым исходным кодом, которая самостоятельно группирует изображения в семантически значимые кластеры. Новизна авторского подхода в том, что разделяются этапы обучения и кластеризации. Сначала запускается задача по обучению признакам, потом модель опирается на полученные на первом этапе данные при кластеризации. Это позволяет добиваться лучших результатов, чем другие подобные модели.
RetrieveGAN

Генерирующие нейросети стремительно развиваются, и RetrieveGAN очередное тому подтверждение. Алгоритм на основе текстового описания сцены использует фрагменты существующих изображений для создания уникальных новых. Пока на получаемых изображениях есть множество артефактов, и выглядят они не очень правдоподобно, но в будущем это может открыть новые возможности в сфере фотомонтажа.
Слежение за пассажирами лифта
Благодаря достижениям в области компьютерного зрения и машинного обучения, слежение за людьми становится еще более эффективным. Группа исследователей из Шанхая по заказу крупного девелопера разработали систему социального контроля поведения в лифтах в реальном времени. Система способна выявлять подозрительную активность в лифтах. Таким образом создатели надеются предотвращать вандализм, сексуальные домогательства, наркоторговлю. Также система заметит, если на каком-то этаже люди будут останавливаться чаще: так, например, уже удалось выявить общепит, который незаконно работает в квартире. Система уже установлена и наблюдает за сотней тысяч лифтов.
Вот таким насыщенным получился июль. Посмотрим, какие новости принесет нам следующий месяц. Спасибо за внимание!