

В марте было особенно много новостей про применение самообучения для задач компьютерного зрения. Главная проблема, которую пытаются решить самообучающиеся модели — выполнять задачи, не полагаясь на тщательно подобранные и помеченные наборы данных. FAIR и Microsoft представили сразу несколько исследований на эту тему.
SEER
Доступность: публикация в блоге / статья
Исследователи из Facebook представили SEER (SElf-supERvised), модель из 1.3 млрд параметров для определения объектов на фото. Алгоритм обучен на миллиарде неразмеченных фото из Instagram и показал результат 84.2% на датасете Imagenet.
В основе модели — алгоритм SwAV для онлайн-кластеризации изображений по сходству, сверточная нейросеть RegNet для оптимизации работы и VISSL — новая опенсорс-библиотека для PyTorch. Последняя содержит обширный набор тестов и целый зоопарк из более чем 60 предобученных self-supervised моделей, которые можно применять на задачах разного масштаба.
Learning from videos
Доступность: публикация в блоге
Исследователи Facebook также рассказали, что самообучающиеся нейросети тренируются не только на фотографиях, но и на загруженных пользователями видео. Эти алгоритмы уже используются в продакшене для рекомендаций в Instagram Reels, где видео часто следуют трендам и содержат одинаковые танцевальные движения и музыку, что позволяет создавать эмбединги и сравнивать степень схожести. Также благодаря алгоритму мы скоро увидим автоматически генерируемые субтитры, так как качество распознавания речи улучшилось на 20%.
Time-Space Transformer

Доступность: публикация в блоге / статья
Алгоритм TimeSformer учится понимать видео через обработку последовательных данных с учётом контекста временных меток. Такой метод self-attention доказал свой успех в применении трансформеров в NLP. Раньше для задач понимания видео использовали 3D сверточные сети, которые требуют в разы больше вычислительных мощностей. Из-за этого обрабатывать можно было только короткие видео по несколько секунд. Применение self-attention позволит обрабатывать видео по несколько минут, возможно в режиме реального времени. Так, например, алгоритм может научиться собирать кубик Рубика, наблюдая за последовательностью действий человека, что открывает большие перспективы.
Swin Transformer
Доступность: статья / репозиторий
Microsoft представила новую архитектуру, которая позволит применять трансформеров для общих задач компьютерного зрения. Если в тексте алгоритму приходится работать со словами, то в видео обрабатываются отдельные пиксели, что затрудняет применение трансформеров. Чтобы решить эту проблему, данный подход предлагает вычислять представление трансформера через смещенные промежутки, ограничивая тем самым потребление мощностей. Исходный код обещают скоро добавить, а пока доступна неофициальная имплементация на PyTorch.
LightningDOT

Доступность: статья / репозиторий
Обучение трансформеров одновременно на текстах и изображениях показало свою эффективность в решении разных задач. Но из-за рассеивания внимания такие модели работают медленно и требуют больших мощностей.
Исследователи из Microsoft представили подход, который значительно ускоряет скорость получения результатов при поиске изображений по описанию. Вместо мультимодального внимания метод предлагает предварительно обучать модель для автономного извлечения индексов характеристик и мгновенного сопоставления скалярных произведений с дальнейшим переоценкой. Метод продемонстрировал SOTA-показатели на датасетах Flickr30K и COCO.
Involution
Доступность: статья / репозиторий
Еще одна попытка найти компромисс между сверточными сетями и self-attention от исследователей из пекинского университета. Involution — это нейронный примитив общего назначения, который универсален для ряда моделей глубокого обучения для различных задач компьютерного зрения.
TagMe

Доступность: страница проекта
Для обучения высокоточных моделей обнаружения объектов требуются большие и разнообразные размеченные датасеты, создание которых стоит больших денег. Новый подход позволяет автоматизировать этот процесс. На входе модель принимает GPS-координаты объекта и области кадра, которые соотносятся с ними. Далее модель сопоставляет изменение координат и изменяющихся пикселей в видео, автоматически создавая баундинг бокс. Таким образом, стоимость процедуры снижается в сотню раз.
PF-AFN
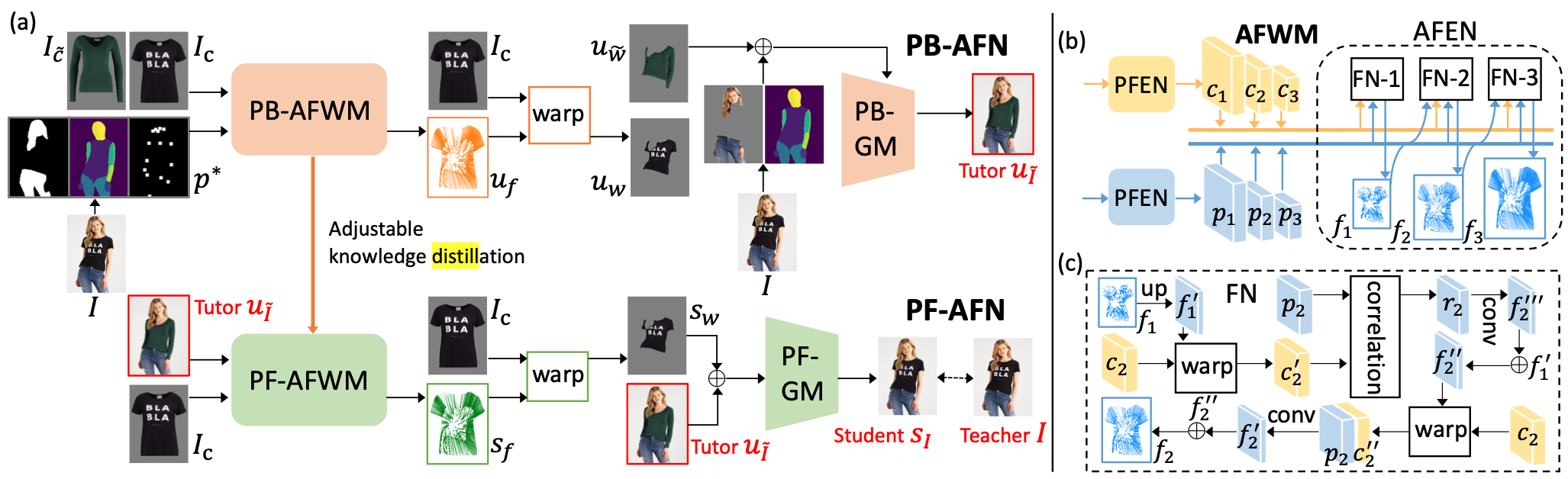
Доступность: статья / репозиторий
Можно сказать, что каждый месяц появляется новая GAN-модель для виртуальной примерки вещей. И демонстрируемые результаты предсказуемо становятся лучше. Авторы этого исследования также представили модель, которая принимает на вход изображения человека и предмета одежды, а на выходе соответственно отдает изображение целевой персоны в этой одежде. Новизна здесь в том, что модель использует дистилляцию знаний, а не парсинг человека на изображении.
Latent Composition

Доступность: страница проекта / статья / репозиторий / коллаб
Помимо виртуального шоппинга GAN также популярен для задач коллажирования изображений с помощью управления латентным пространством, о чем мы не раз рассказывали в предыдущих выпусках. В данном случае исследователи из MIT используют скрытую регрессионную сеть, которая учится на недостающих данных для дополнения композиции изображения. Комбинация сети регрессоров и предварительно обученного GAN формирует предварительные реалистичные изображения, несмотря на неполные данные на входе. На основе этих изображений модель завершает композицию.
Infinite Images

Доступность: страница проекта
Исследователи из MIT представили нейросеть, которая создает «бесконечные» изображения. На вход подается картинка, к которой нейросеть подбирает наиболее подходящий кадр из базы в несколько миллионов изображений. Этот кадр дорисовывается с учетом геометрии сцены, то есть, подгоняется под исходный кадр. Алгоритм может имитировать не только движение камеры вперед, как Infinite nature, но и движение в бок, как при панорамной съемке.
GANsformer

Доступность: статья / исходный код
На основе StyleGAN исследователи из Стэнфорда создали новый тип трансформера, в котором информация от скрытых переменных передается к визуальным характеристикам и наоборот в непрерывном цикле обратной связи для улучшения качества синтезируемых изображений. Модель демонстрирует хорошие результаты на разных датасетах, от виртуальных рендеров до реальных уличных сцен. Помимо хорошего качества, результаты более интерпретируемые, и модель обучается быстрее аналогов.
FaceBlit

Доступность: страница проекта / статья
Исследователи из Чешского технологического университета показали новый GAN для переноса стилей для селфи. Отличие от других подходов в том, что алгоритм сохраняет детали стиля семантически значимым образом. То есть, например, если какой-то штрих используется для изображения линии скул, то и на целевом изображении он будет применен для прорисовки скул.
Мультимодальные нейроны CLIP
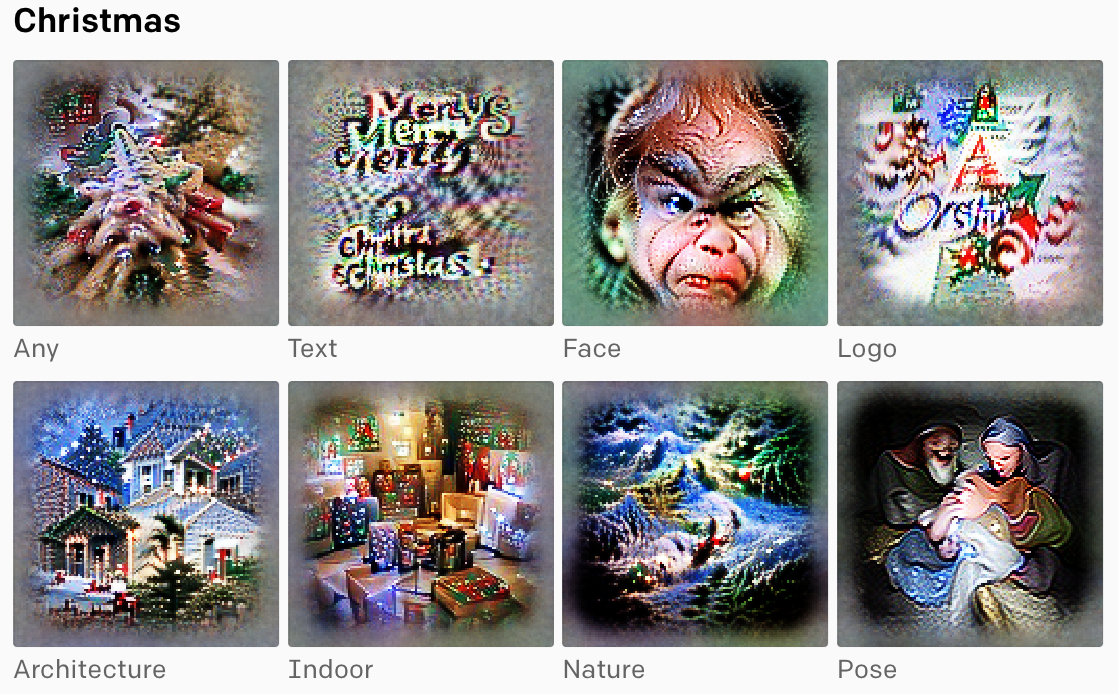
Доступность: публикация в блоге / репозиторий
В марте быстро разлетелась новость о том, что умный алгоритм CLIP от Open AI легко обмануть при помощи ручки и бумаги, заставив модель ошибочно принять яблоко за iPod например.Open AI объяснили уязвимость к «типографским атакам» особенностью устройства нейросети.
Исследователи обнаружили, что в CLIP есть мультимодальные нейроны, которые реагируют на одно и то же понятие, независимо от того, как оно представлено — в виде текста, рисунка или фотографии. То есть, нейросеть от Open AI немного в этом плане похожа на человеческий мозг — наши нейроны реагируют на кластеры абстрактных концепций, сосредоточенных вокруг общей высокоуровневой темы, а не на конкретный образ.
Например, если вы поклонник Халли Берри, то в вашем мозге есть отдельный нейрон, который «выстреливает» всякий раз, когда вы видите фото актрисы в гриме, нарисованный портрет или просто текст с ее именем. Оказалось, что большинство нейронов в CLIP легко поддаются интерпретации. На сайте можно посмотреть отобранные нейроны из последнего слоя. Каждый нейрон представлен визуализацией характеристик, предварительно отобранных людьми, чтобы было проще понять каждый нейрон. Понимание того, как устроены мультимодальные нейроны, поможет лучше понять, как модель осуществляет классификацию.
P.S. Теперь в конце дайджеста мы будем сообщать, если в открытый доступ выложили исходники каких-то моделей, о которых мы рассказывали в предыдущих подборках.
Итак, в марте стали доступными:
- исходный код и коллаб проекта Infinite Nature из январской подборки;
- интерактивное демо для Monster Mash из сентябрьского выпуска;
- GPT-Neo, неофициальная имплементация GPT-3 из 2.7 млрд параметров от Eleuther.ai.
- Опенсорс-сообщество продолжает радовать, и в марте даже появился сервис, через который можно подать жалобу на невоспроизводимые результаты исследований.
На этом все, спасибо за внимание и до встречи в следующем месяце!


