Начнем подборку с новостей из области NLP. Языковых моделей становится все больше, некоторые из них уже активно используются в продакшне, про другие пока есть только громкие пресс-релизы. Коротко пройдемся по самым важным новостям.
Как вы помните, в прошлом году Microsoft получила уникальные права на использование GPT-3. И вот за прошлый месяц на базе языковой модели от Open AI были представлены сразу два продукта.
Power Apps Ideas
Доступность: публикация в блоге
В платформу разработки приложений с низким уровнем кода Power Fx добавили возможность создавать новую функциональность без знания формул, через описание на естественном языке. Таким образом GPT-3 снижает порог вхождения в программирование, а платформа отчасти начинает стирать границу между лоукод и ноукод решениями.
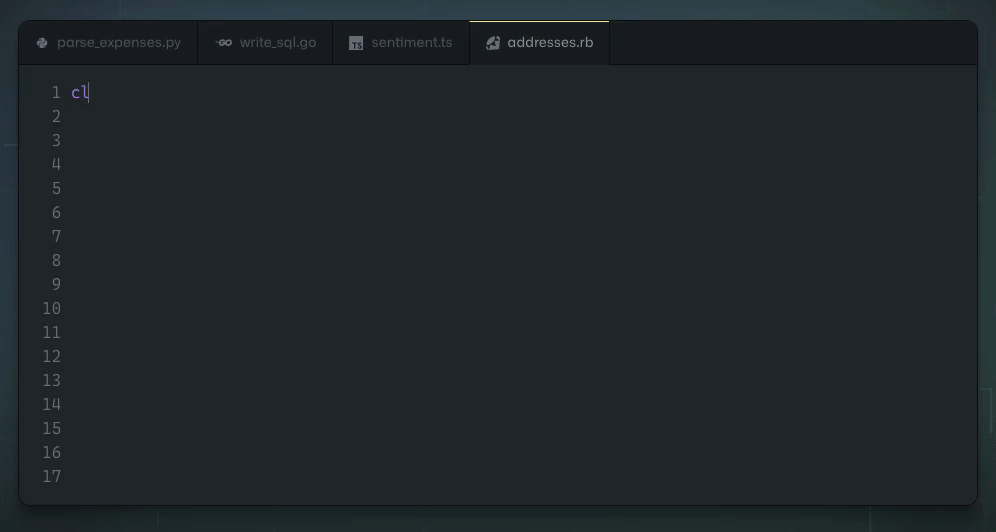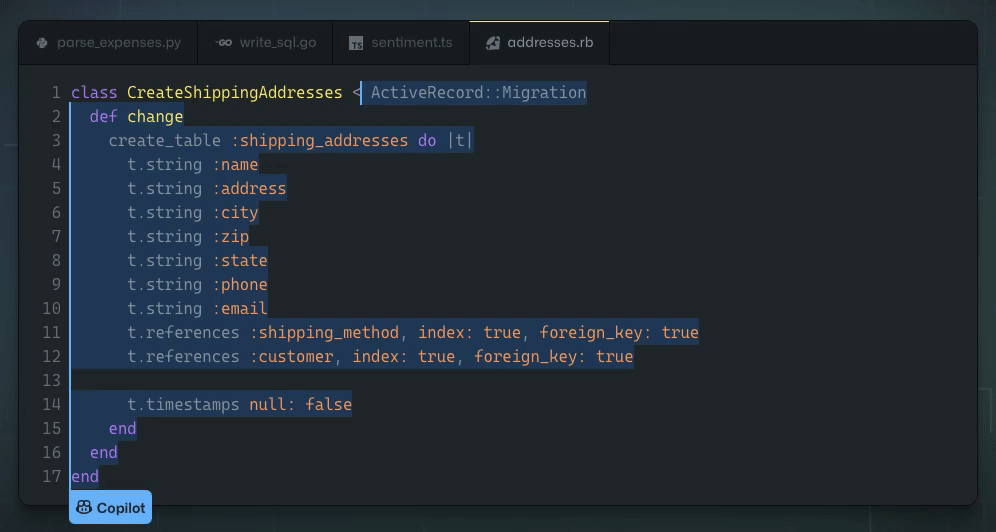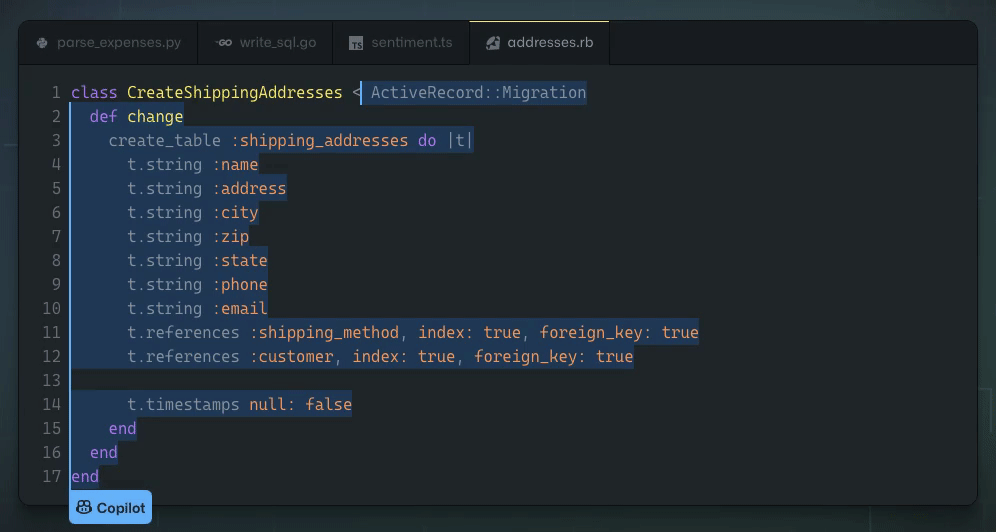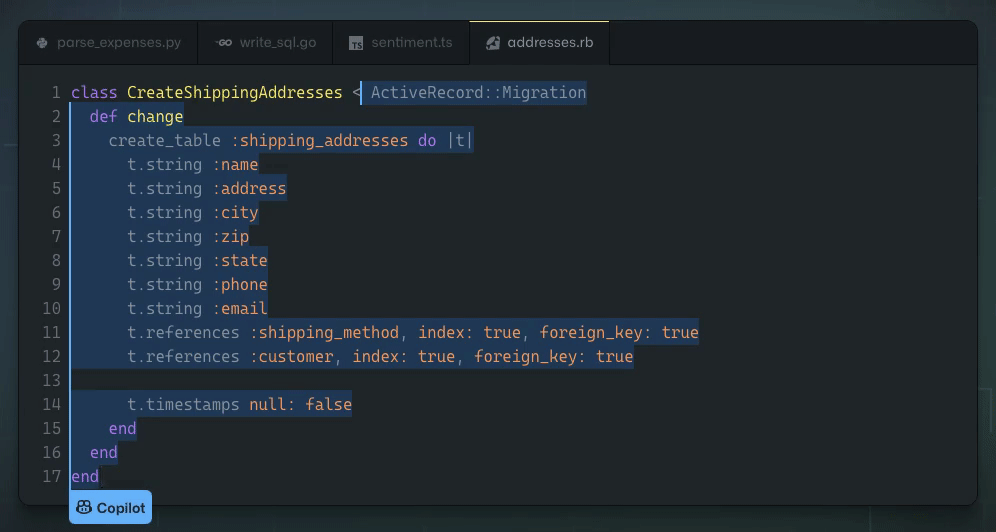
Copilot
Доступность: страница проекта
Второй совместный продукт запущен еще и при поддержке GitHub. Это ассистент программиста, который предлагает добавить одну или несколько строк кода в зависимости от контекста уже написанного кода и комментариев. Copilot показывает хорошие результаты работы с JavaScript и Python, и по словам гендиректора GitHub Ната Фридмана, большинство получивших ранний доступ разработчиков удовлетворены работой, и не отключают ассистента в течение дня.
Ожидаемо, обе технологии вызвали споры среди разработчиков: одни видят в них потенциал для повышения продуктивности, другие — угрозу профессии.
Wu Dao 2.0
Доступность: публикация в блоге (осторожно, китайский)
В начале июня разлетелась новость об убийце GPT-3 из Китая. Исследователи из Пекинской Академии Искусственного Интеллекта (BAAI) заявили о создании модели на 1,75 триллиона тренировочных параметров, что в десять раз больше модели от Open AI. Модель мультимодальна, и может работать как с текстами, так и с изображениями. Для обучения потребовалось 4.9 терабайтов отобранных данных.
Модель способна выполнять не только задачи обработки естественного языка и генерации текста, но также распознавать и генерировать фотореалистичные изображения из текстового описания, добавлятья описания к изображениям и даже предсказывать 3D-структуру белков как Alpha-Fold. Если верить исследователям, то модель достигла SOTA-показателей на 9 бенчмарках, включая SuperGLUE и ImageNet.
«Балабоба» и YaLM
Доступность: страница проекта / публикация в блоге
Команда «Яндекса» представила сервис генерации текстов «Балабоба», в основе которого разработанная ими языковая модель YaLM на трансформер-архитектуре на 13 млрд параметров. Подробнее о том, как устроена модель, и как она обучалась, можно узнать непосредственно на Хабре.
TextStyleBrush
Доступность: публикация в блоге / датасет
Facebook AI представили модель, которая заменяет текст с сохранением стиля всего по одному слову и справляется даже с рукописным текстом. Модель обучена понимать не только разную типографику и каллиграфию, но также различные повороты, наклоны и искажения, которые возникают при письме на бумаге. Модель работает таким образом, что отделяет содержание текста внутри изображения от того, как этот текст выглядит. Таким образом, полученный стиль можно переносить на любой текст.

Авторы признают, что модель пока плохо справляется с разноцветным текстом и надписями на металлических поверхностях, но результаты все равно впечатляют — уже видно, что качественный фотореалистичный перевод становится ближе, а типографские атаки и дипфейковые надписи опаснее.
Barbershop
Доступность: страница проекта / статья / репозиторий
При совмещении элементов из нескольких изображений возникают сложности из-за различий в освещении, геометрии сцены, перекрывании одних объектов другими и т.д. Из-за этого даже с учетом возможностей GAN синтезировать реалистичные волосы или лица, их по-прежнему сложно объединить на разных снимках. Данный инструмент фокусируется на переносе причесок, с помощью GAN-инверсии.

Исследователи демонстрируют новые скрытое пространство для смешивания изображений, которое лучше сохраняет детали. Подход позволяет передавать характеристики из нескольких эталонных изображений, включая отдельные черты вроде родинок и морщин для синтеза правдоподобных согласованных изображений.
SIMSWAP
Доступность: статья / репозиторий / колаб

У популярных дипфейк моделей либо отсутствует возможность обобщать до произвольной идентичности, либо не сохраняются такие атрибуты как выражение лица и направление взгляда. Авторы этого фреймворка смогли добиться возможности переносить лица на фото и видео без потери разных нюансов вроде макияжа.
GANTheftAuto
Доступность: видео-демонстрация / репозиторий

Если в прошлом месяце мы рассмотрели, как с помощью нейросетей можно получить фотореалистичную картинку в Grand Theft Auto, то здесь энтузиасты не просто улучшили графику, а воссоздали виртуальный мир игры с помощью генеративно-состязательной сети. В основе их подхода GameGAN от NVIDIA, с помощью которой исследователи уже сделали копию Pac-Man. Теперь мы видим, что обучив модель на видео отдельной игры, можно создать ее клон, даже такой сложной как GTA.
VOLO
Доступность: статья / репозиторий
Для классификации изображений принято использовать сверточные нейронные сети, но все большую популярность набирает архитектура Vision Transformer (ViT), в основе которой self-attention. Она демонстрирует лучшие результаты, но пока уступает по производительности. Новая архитектура Vision Outlooker (VOLO) призвана решить проблемы производительности с помощью нового механизма outlook attention. Без предобучения модель достигла высокого показателя 87,1% на бенчамарке ImageNet.
Alias-Free GAN
Доступность: страница проекта / репозиторий

Процесс синтеза типичных генеративных состязательных сетей сильно зависит от абсолютных пиксельных координат, из-за чего возникают различные искажения текстуры объектов — например, на сгенерированных фотографиях неестественно двигаются волосы и возникает эффект мерцания. Исследователи видят причину в неправильной обработке сигнала, которая вызывает наложение спектров в сети генератора. В представленном методе сигналы интерпретируются как непрерывные, что не позволяет нежелательным данным попасть в процесс иерархического синтеза. Благодаря этому переходы между разными признаками при генерации выглядят более плавными.
WebVid
Доступность: статья / репозиторий
Огромный набор данных с парами из коротких видеороликов и текстовых описаний, полученных из интернета. Ролики разнообразны и богаты по содержанию. Датасет содержит 10,7 млн пар видео-текст суммарно на 52 тысячи часов.
На этом все, спасибо за внимание и до встречи через месяц!