
GLIDE
Доступность: статья / репозиторий
OpenAI выложили исходный код GLIDE для генерации высококачественных синтетических изображений из текстовых описаний. Это модель-конкурент их собственной DALL-E, но она построена не на генеративно-состязательных сетях, а имеет в основе диффузионный подход, о котором подробнее писали в июльской подборке. Это отличие позволяет модели быть более производительной, при этом имея в три раза меньше параметров (3.5 млрд параметров против 12 млрд). Архитектура состоит из двух моделей — первая генерирует изображение с разрешением 64×64, а вторая улучшает разрешение до 256×256 пикселей.
HyperStyle
Доступность: страница проекта / статья / репозиторий / колаб
Реконструкция исходного изображения — важная задача для GAN-моделей. Для того, чтобы манипулировать сгенерированными изображениями, нужно получить код скрытого пространства, который соответствует входному фото. Обычно для этого используют градиентый спуск и без изменения тренировочных параметров итеративно меняют код до тех пор, пока сгенерированное изображение не станет похожим на исходное. Это медленный процесс, который пытаются ускорить различными подходами, в результате чего, как правило, страдает точность.
Исследователи из Тель-Авивского университета предложили использовать гиперсеть, которая обучается модулировать веса StyleGAN, чтобы точно воссоздавать заданное изображение в редактируемых областях скрытого пространства. Этот подход в десятки раз быстрее и точнее существующих.
GANGealing
Доступность: страница проекта / публикация в блоге / статья / репозиторий

Исследователи из Adobe, MIT и Беркли предложили новый способ решения задачи плотного визуального выравнивания. Алгоритм с помощью пространственного преобразователя обертывает случайные выборки из GAN, обученной на повернутых изображениях, в совместном целевом режиме.
С помощью этого фреймворка пользователь сможет переместить маску на неровное изображение без необходимости ручного выравнивания, и этот результат покадрово применится к целому видео. Такой подход открывает массу новых возможностей в AR.
PoE-GAN
Доступность: статья
Не прошло и месяца с релиза интерактивного онлайн-демо для Gaugan2 от NVIDIA, как компания представила новую более производительную генеративную модель для решения той же задачи — создания фотореалистичных пейзажей из текстового описания, набросков и карт сегментации. Подход позволяет синтезировать изображения, обусловленные множественными входными модальностями или любым их подмножеством, даже пустым набором.
Animated Drawings
Доступность: онлайн-демо / публикация в блоге
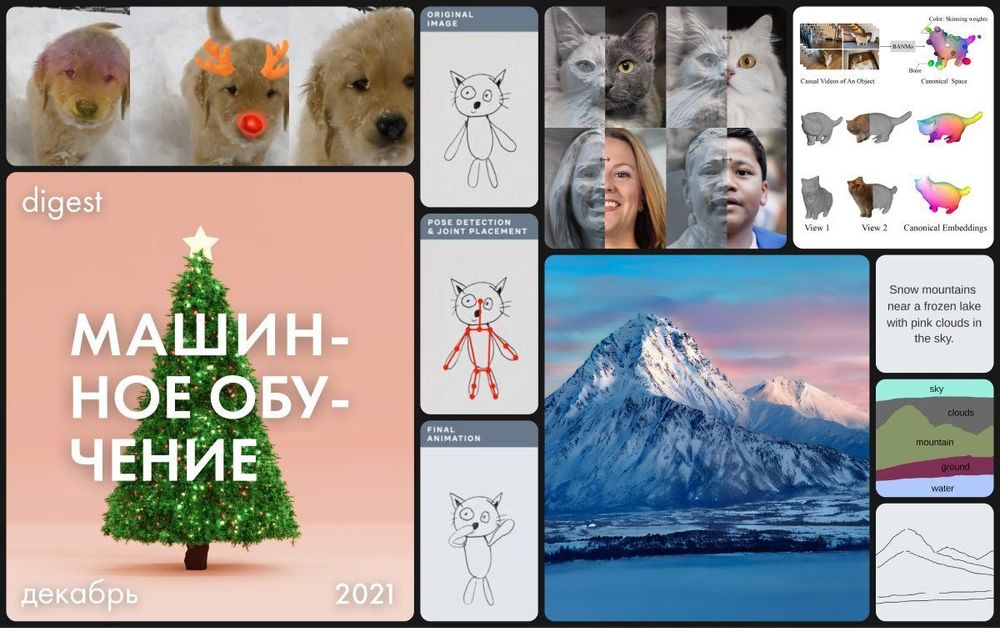
Детские рисунки часто выглядят абстрактно и причудливо, что даже человеку не всегда легко понять, где у изображенной фигуры руки и ноги. Для современных моделей, которые превосходно справляются с обнаружением объектов на фотографиях и картинах, это задача остается очень сложной. Исследователи Meta AI представили первый в своем роде способ автоматической анимации нарисованных детьми людей и человекоподобных персонажей.
EG3D
Доступность: страница проекта / статья / репозиторий

Генерация высококачественных трехмерных объектов с использованием только наборов двухмерных изображений как правило либо требует больших вычислений, либо приближает значения, что сказывается на точности 3D. Данный подход разделяет генерацию функций и нейронный рендеринг, позволяя использовать самые современные GAN-модели, и имеет гибридную сетевую архитектуру для синтеза изображений высокого разрешения, а также высококачественной трехмерной геометрии.
BANMo
Доступность: страница проекта / статья

Обычно при реконструкции артикулируемых 3D-объектов опираются на специализированные датчики (например, синхронизированные многокамерные системы) или предварительно созданные 3D-модели. Эти подходы не позволяет быстро подстраиваться под разнообразие форм. Данный подход позволяет создавать анимированные 3D-модели по наборам видео, снятым на обычную камеру смартфона.
Dream Field
Доступность: страница проекта / статья

Подход объединяет мультимодальные представления и нейронный рендеринг для генерации 3D-моделей исключительно из текстовых описаний. В основе модели совмещены NeRF и CLIP архитектуры, что позволяет не опираться на обучающие данные, ограниченные наборами категорий, которые есть в существующих датасетах типа ShapeNet.
Это был 24-й выпуск дайджеста. Обычно в заключении мы прощаемся с вами до следующей встречи через месяц, но на этот раз традицию придется нарушить.
На протяжении двух лет мы старались сделать подборку интересным источником знаний о том, что происходит в ML-индустрии. Вскоре мы столкнулись с тем, что задач, которые активно пытаются решить исследователи, не так много, публичных кейсов применения алгоритмов в продакшене еще меньше. Технологии устаревают быстро, а различия между подходами столь тонкие, что донести их в одном абзаце невозможно.
Мы решили переработать формат нейродайджеста и перейти на квартальный график — следующий выпуск планируется в апреле. Спасибо, что были с нами, не прощаемся!