
На WS митап-3, посвещенный Java, бэкенд-разработчик Work Solutions Олег Яшлян поделился опытом применения DDD (Domain-Driven Design) для работы с legacy-системами. В этой статье — подробный разбор подхода к реорганизации устаревшего кода, основанный на опыте работы Work Solutions с энтерпрайз-проектами. Полную запись выступления можно посмотреть в конце статьи.
Что такое legacy enterprise-разработка на самом деле
В мире enterprise-разработки встреча с легаси неизбежна. Жизненный цикл которых составляет от 5 лет до бесконечности, поэтому шанс попасть на поддержку такой системы существенно выше, чем на ее начальную разработку. И реакция разработчиков на legacy-код часто зависит от их опыта: джуниоры приходят в ужас, мидлы относятся с пониманием, а опытные разработчики воспринимают это как часть работы.
Определения legacy-систем разнятся от источника к источнику. Некоторые считают, что это любая программа без тестов, другие — что это код старше года, третьи — что это любая система, разработанная «не нами». Но наиболее точное определение дал Майкл Физерс в книге «Эффективная работа с унаследованным кодом»:

Legacy — это система, для поддержания которой требуются значительные усилия.
Когда разработчики сталкиваются с legacy-системой, первая мысль — «давайте перепишем всё с нуля». Это желание понятно: кто не хочет создать красивую, надежную систему на актуальном стеке? Однако такой подход часто не учитывает бизнес-реальность.
Ценность приложения для бизнеса определяется простой формулой:
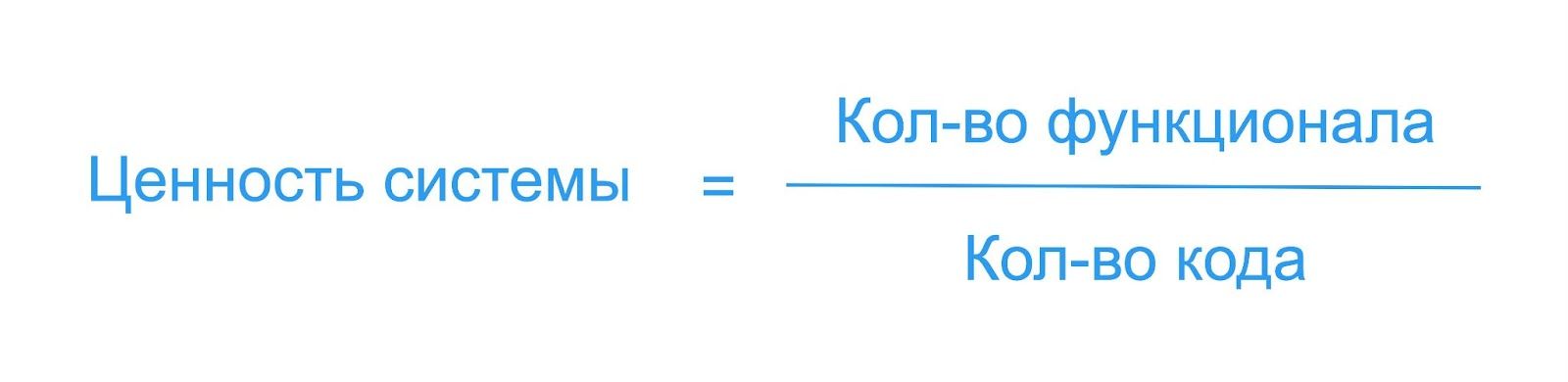

Для бизнеса система тем ценнее, чем больше функционала обеспечивается меньшим количеством кода. При этом качество кода, как ни парадоксально, часто отходит на второй план. Даже если поддержка платформы требует в 2-3 раза больше ресурсов, чем могла бы, бизнес может быть вполне доволен, пока она приносит прибыль.
При постоянной работе с legacy-системой важно определить реалистичные цели:
- Возможность эффективно разрабатывать новый функционал;
- Способность оперативно исправлять возникающие ошибки;
- Сокращение времени на поддержку;
- Создание комфортных условий для работы команды.
Дилемма разработчика: переписать нельзя поддерживать
Типичный сценарий: разработчики приходят к бизнесу с предложением переписать систему. «Код ужасен, работать с ним сложно, давайте заморозим разработку на пару лет и создадим всё заново!» Или ещё интереснее — предлагают нанять вторую команду для поддержки старой системы, пока первая будет писать новую. Неудивительно, что бизнес редко приходит в восторг от таких идей.
Помимо очевидных бизнес-возражений по поводу полного рефакторинга, существует и технический риск: кто может гарантировать, что новая система окажется качественнее существующей? История разработки показывает, что самые ужасные legacy-системы часто начинались с самых лучших намерений.
Полное переписывание системы может быть оправдано только в двух случаях:
1. Когда приложение перестало приносить бизнесу прибыль;
2. Когда система технически не функционирует.
Существует и другая крайность — смириться с ситуацией и продолжать поддерживать систему, наращивая технический долг и подпирая костыли новыми костылями. Но это тупиковый путь, который только усугубит проблемы.
Очевидно, нужен третий путь — подход, который позволит сочетать преимущества «чистого» кода и новой архитектуры с возможностью непрерывной поставки свежего функционала. Необходимо найти способ постепенного улучшения системы без остановки её развития.
Что такое Domain-Driven Design
Среди множества подходов к legacy в разработке особенно выделяется концепция «углубляющего рефакторинга», предложенная Эриком Эвансом в книге «Предметно-ориентированное проектирование. Структуризация сложных программных систем». Этот подход позволяет постепенно улучшать систему, сохраняя её работоспособность.

Domain-Driven Design (DDD) или предметно-ориентированное проектирование — это подход к разработке, при котором программисты сначала глубоко погружаются в бизнес-задачи, а затем строят архитектуру, максимально соответствующую реальным процессам. Вместо навязывания технических абстракций, DDD предлагает «послушать» бизнес, перенять его терминологию и логику, чтобы система стала естественным продолжением предметной области, а не инородной конструкцией со своими правилами и языком.
Подход к реанимации legacy-систем с помощью DDD основан на нескольких ключевых источниках:
- Практический опыт работы с legacy-системами;
- Книга Эрика Эванса "Предметно-ориентированное проектирование";
- Работы Вона Вернона по реализации DDD.
Исследования Владимира Хорикова о работе с унаследованными проектами
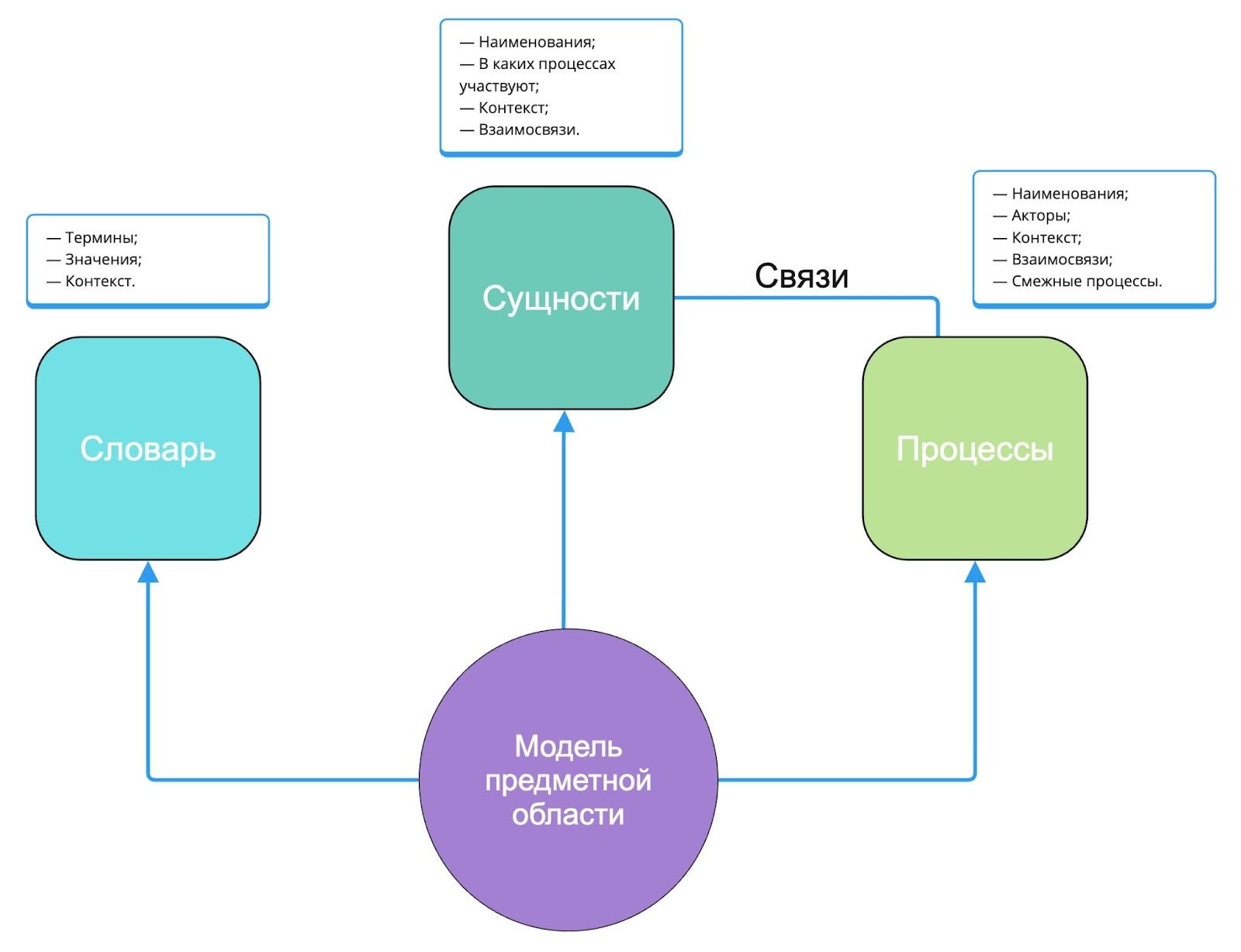
Задача разработчика — трансформировать этот хаос в понятную и структурированную систему. Для этого нужно:
- Выявить ключевые сущности системы;
- Определить основные бизнес-процессы;
- Установить реальные связи между компонентами;
- Создать четкую модель предметной области.
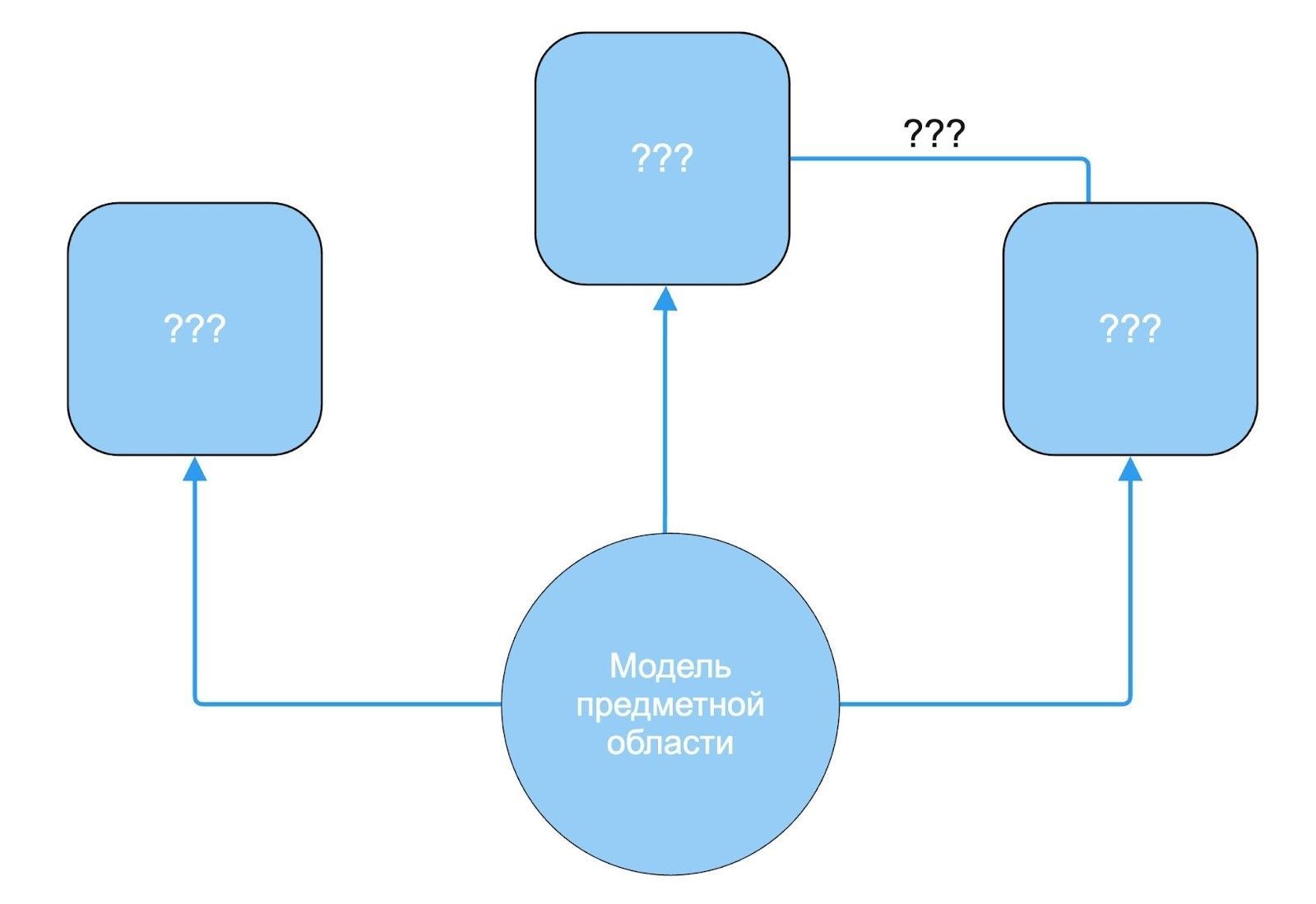
Так выглядит предметная область на старте: клубок сущностей и связей вместо структурированной модели
Единый язык как основа трансформации legacy-систем
Первый и основополагающий стратегический паттерн DDD — Ubiquitous Language (Единый язык). Это выверенный набор терминов из бизнес-области, который используется как для общения между бизнесом и разработкой, так и для описания всех сущностей и процессов внутри ограниченного контекста предметной области.
Единый язык решает одну из главных проблем при работе с legacy-системами: разрыв в коммуникации между бизнесом и разработкой. Часто одни и те же процессы или сущности называются по-разному разными участниками процесса, что приводит к путанице и ошибкам в реализации.

Важные аспекты Ubiquitous Language:
- Использование терминов из бизнес-домена;
- Непротиворечивость определений;
- Применение во всех слоях приложения;
- Использование в документации и коде.
Единый язык предметной области должен использоваться как разработчиками, так и представителями бизнеса для успешной коммуникации. При этом язык не навязывается бизнесу разработчиками, а наоборот — заимствуется у бизнеса и формализуется в виде глоссария.
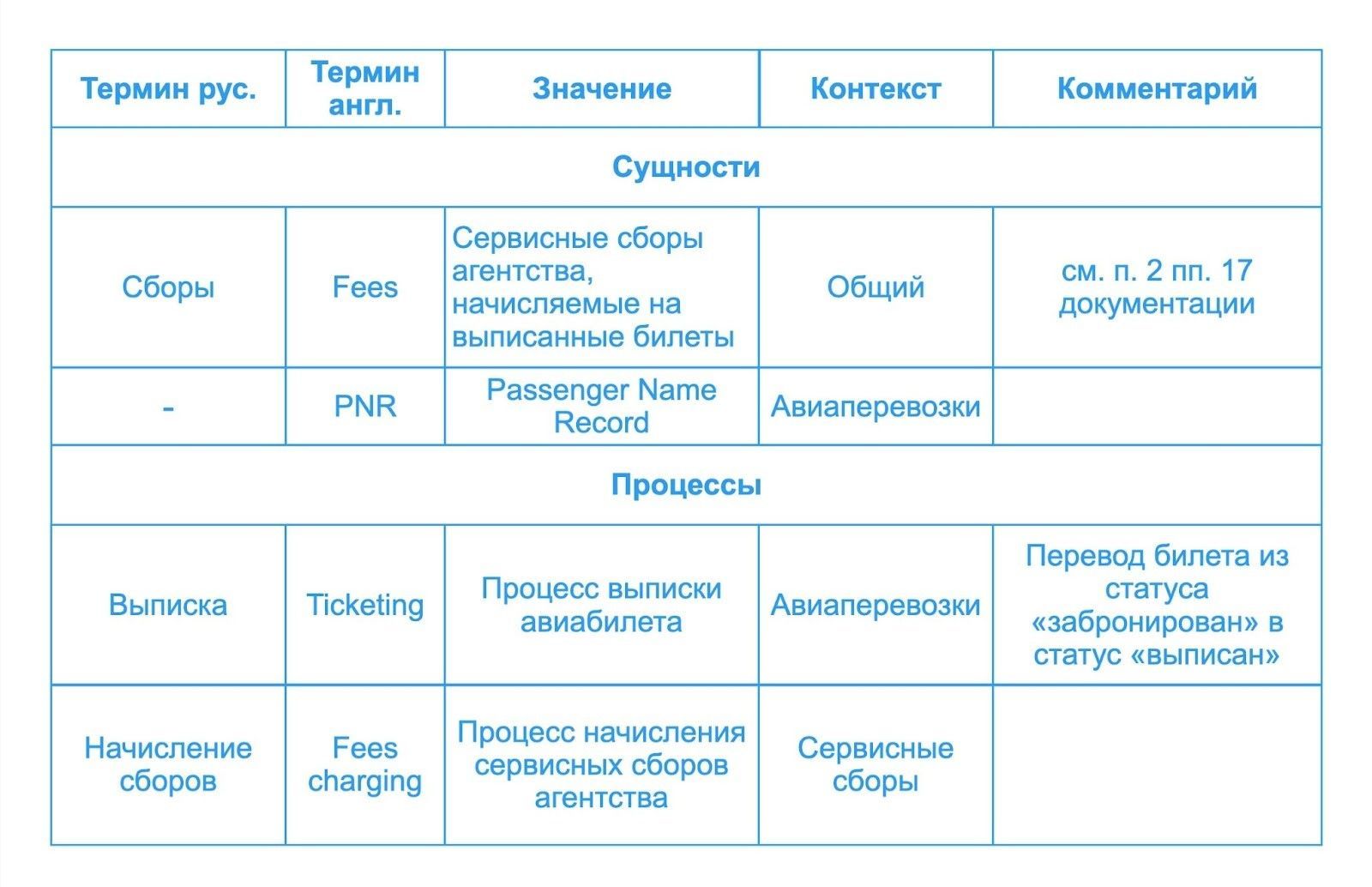
Глоссарий предметной области: термины, определения и примеры, которые снижают порог входа в проект
Структурированный глоссарий содержит термины на русском и английском языках, точные определения, примеры использования в контексте, а также необходимые пояснительные комментарии.
Практическая ценность глоссария:
1. Снижение порога входа для новых разработчиков благодаря единому именованию процессов и сущностей;
2. Улучшение коммуникации с бизнесом;
3. Формирование общего понимания процессов.
Отдельно отметим психологический аспект: использование языка предметной области демонстрирует бизнесу, что разработчики действительно погружены в контекст задач и понимают цели заказчика.
Паттерны DDD
Паттерны DDD делятся на две категории: стратегические (архитектурные) и тактические. Стратегические паттерны, такие как Ubiquitous Language, который мы уже рассмотрели, отличаются простотой в понимании и внедрении при высокой эффективности.
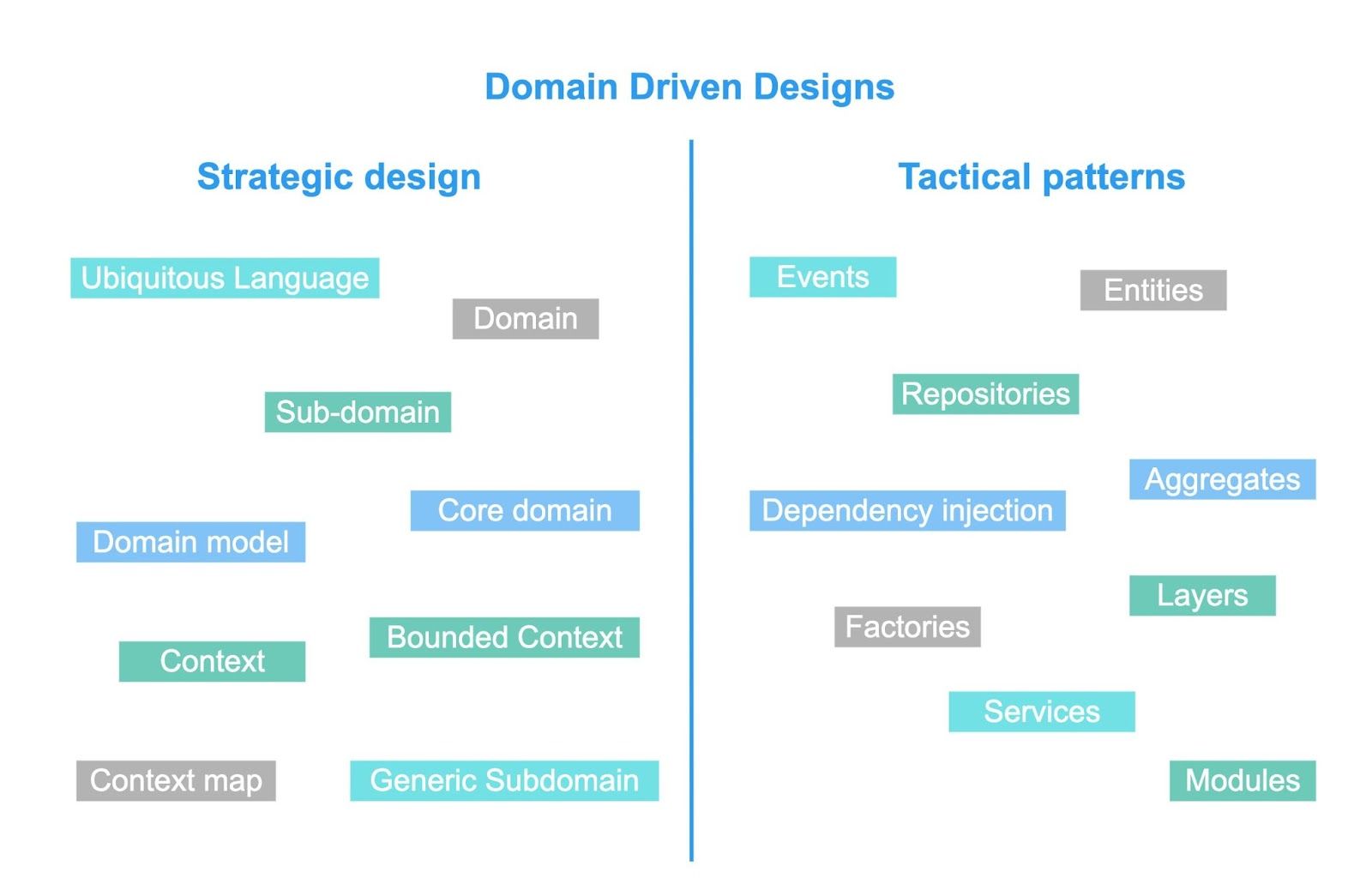
Паттерны DDD: стратегические паттерны для архитектуры и тактические для кода
Учитывая обширность темы DDD, сегодня сосредоточимся на ключевых паттернах, особенно полезных при работе с legacy-системами. Такой подход поможет нам сфокусироваться на практическом применении DDD для улучшения существующего кода.
Business Travel: понимание предметной области
В качестве примера выбрали предметную область business travel по двум причинам:
1. Work Solutions специализируется в этом направлении;
2. Рассматриваемые примеры основаны на реальном опыте работы с аналогичными проектами.
Это позволит нам рассмотреть применение DDD на конкретных, практических примерах из реальной разработки, а не только в теории.
Business travel агрегатор представляет собой систему, которая объединяет различные сервисы для организации деловых поездок.

Business travel агрегатор: единая точка доступа к авиабилетам, отелям, ж/д и другим сервисам командировок
Суть business travel направления заключается в предоставлении комплексного сервиса по организации командировок. Владелец бизнеса получает доступ к единой системе, где может самостоятельно или предоставить возможность сотрудникам:
- Приобретать авиабилеты;
- Покупать железнодорожные билеты;
- Бронировать гостиничные номера;
- Заказывать трансфер;
- Организовывать другие аспекты деловых поездок.
Агрегатор выступает единой точкой доступа, собирая предложения от различных операторов и представляя их через унифицированный интерфейс на сайтах агентств. Это позволяет клиентам получить полный цикл услуг для организации командировок в режиме «одного окна».
Для демонстрации принципов DDD сузим широкую область business travel до контекста агрегации и продажи авиабилетов. Система агрегирует данные от поставщиков авиауслуг и предоставляет возможность оформления билетов.
Прежде чем приступить к рефакторингу такой системы, важно определить ее смысловое ядро (Core Domain). В терминологии DDD это не просто набор основных функций, а часть системы, которая имеет критическое значение для бизнеса. Core Domain обычно обладает несколькими характерными признаками: выступает важнейшей частью бизнеса,дает компании уникальную позицию на рынке, генерирует основную прибыль и, что особенно важно, не может быть просто заменен готовым коробочным решением.
На первый взгляд может показаться, что для системы агрегации авиабилетов смысловым ядром является процесс их продажи. Однако это не совсем так. Если платформа использует внешний агрегатор, то ему делегируется эта ответственность. Даже при разработке собственной системы поставщики обычно предоставляют механизмы, предотвращающие выписку билетов по неактуальным данным.
При анализе business travel агрегатора важно правильно определить смысловое ядро платформы. Вопреки первому впечатлению, это не процесс продажи билетов, а система сервисных сборов (Fees) — механизм начисления комиссий при продаже билетов. Именно она обеспечивает бизнесу конкурентное преимущество через прозрачность расчетов, гибкую систему лояльности, а также удобную отчетность и контроль расходов.
Проблемы традиционного подхода к разработке
Классический подход к разработке часто приводит к парадоксальной ситуации: несмотря на рост компетенций команды, приложение становится всё более хаотичным. Типичный сценарий выглядит так:
- Сначала выявляются все возможные сущности и процессы;
- На их основе создается фундамент системы;
- Разрабатывается сопутствующий функционал;
- Параллельно растет понимание предметной области;
- Приходит осознание ошибочности начальных решений;
- К этому моменту объем кода уже слишком велик для фундаментальных изменений;
- Новый функционал наращивается на некорректном фундаменте.
DDD предлагает другой путь:
- Выявление только ключевых процессов и сущностей;
- Обсуждение найденного с представителями бизнеса;
- Разработка фундамента на основе полученных знаний;
- Целенаправленное изучение предметной области;
- Своевременное выявление и исправление ошибочных решений;
- Разработка дополнительного функционала;
- Постоянное углубление знаний о предметной области;
- Регулярный углубляющий рефакторинг.
Основной момент — постоянное взаимодействие с бизнесом и итеративный подход к разработке. Невозможно сначала полностью изучить предметную область, а потом написать идеальное приложение, ведь бизнес не даст столько времени на анализ, без написания кода сложно правильно сформулировать проблематику, а само понимание предметной области естественным образом растет в процессе разработки.
Классический путь к легаси: фундамент строится до понимания домена, а затем обрастает хаотичным функционалом
При работе с legacy неизбежно приходится начинать с минимальным пониманием предметной области. Поначалу это приводит к ошибкам в определении поддоменов, неправильному установлению границ контекстов и непониманию взаимосвязей процессов. Но именно через этот опыт, включая долгие обсуждения с аналитиками, происходит реальное погружение в предметную область.

В отличие от обычного рефакторинга, который улучшает читаемости и оптимизацию кода без изменения функциональности, углубляющий рефакторинг преследует более масштабную цель. Он призван привести кодовую базу в соответствие с реальными бизнес-процессами, опираясь на растущее понимание предметной области.
Для успешного погружения в domain необходимо использовать различные подходы к изучению. Начать можно с анализа существующего кода и документации — даже в не лучшем состоянии они дают представление о текущей реализации бизнес-процессов. Параллельно важно заниматься самостоятельным изучением: читать специализированную литературу, смотреть записи бизнес-конференций, разбираться в отраслевых стандартах.
Однако самым эффективным методом остается прямое общение с представителями бизнеса. Именно оно позволяет получить информацию из первых рук и понять неочевидные аспекты бизнес-процессов, которые сложно уловить только через документацию. Сочетание всех этих подходов, постоянное углубление знаний и регулярный рефакторинг кода позволяют постепенно привести систему к состоянию, когда она действительно отражает реальные бизнес-процессы.

Поиск возможностей для рефакторинга
Идеальный момент для начала углубляющего рефакторинга наступает, когда бизнес сам запрашивает изменения в ключевой функциональности. В нашем случае это запрос на модификацию программы лояльности — прямое попадание в смысловое ядро системы.
Теперь, когда мы понимаем, что такое legacy, какие есть основы предметно-ориентированного проектирования и базовые принципы применения DDD, можно перейти к практической части: анализу текущей системы расчета и начисления сборов, её хранению в БД и планированию необходимых изменений.
Анатомия типичного сервиса в legacy-системе
Перед нами типичный пример «сервиса» из legacy-системы — класс AviaService. Подобные классы хорошо знакомы большинству разработчиков, и они часто становятся источником многих проблем в больших приложениях.
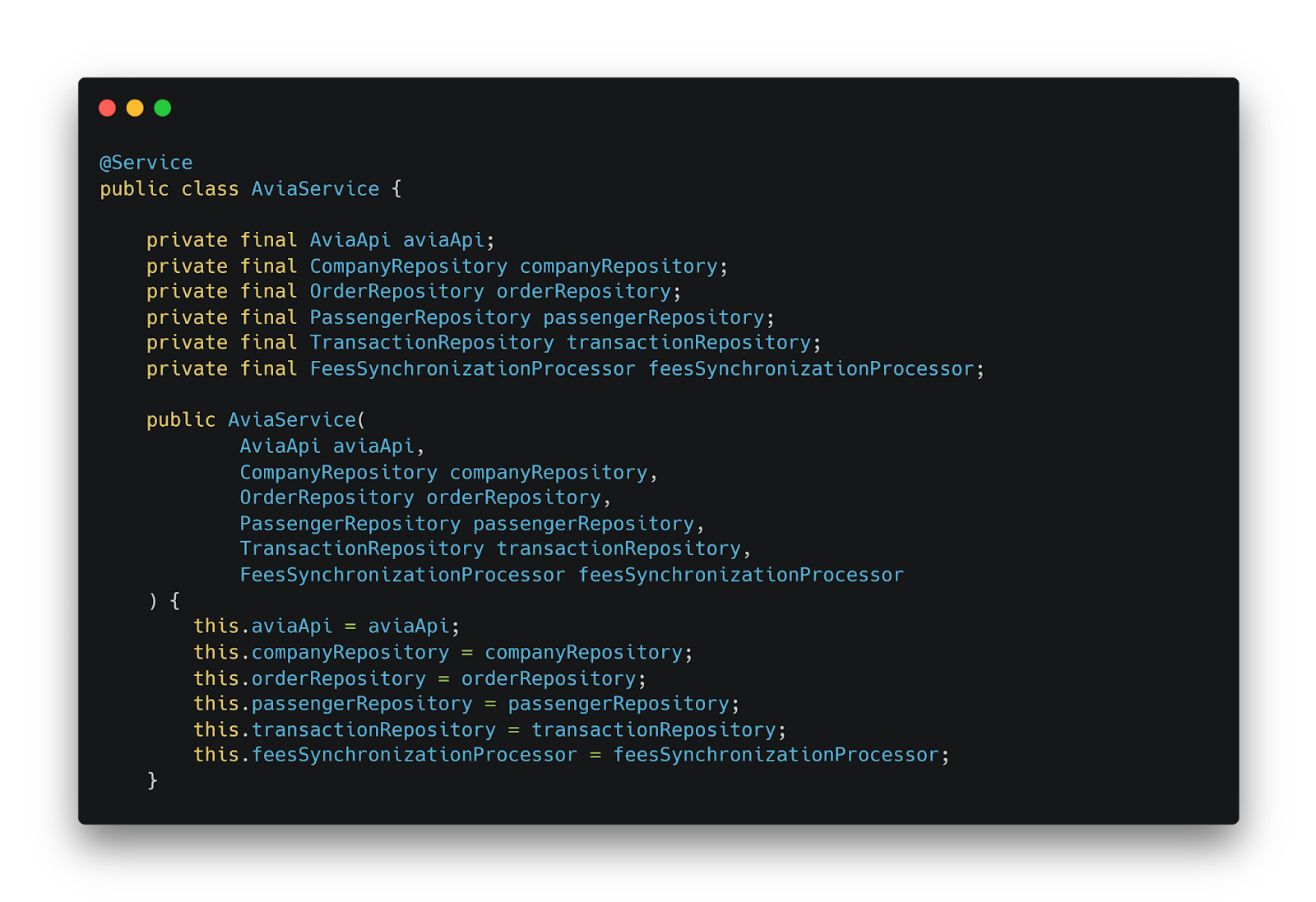
Типичный AviaService в legacy-системе: тысячи строк кода и десятки зависимостей в одном классе
В таких сервисах обычно встречаются тысячи строк кода в одном классе и множество зависимостей от других компонентов системы. Они берут на себя слишком широкий спектр задач — от аутентификации пользователей до взаимодействия с внешними системами, от управления бизнес-логикой до работы с базой данных. По сути, такой сервис становится монолитом внутри монолита, нарушая все принципы чистой архитектуры и единой ответственности.
Проблемы начинаются с названий
В методе ticketIssue мы сразу видим первую проблему legacy-кода — неправильное именование. Хотя можно предположить, что метод отвечает за выписку билета, название не соответствует принятой в предметной области терминологии. В контексте авиабилетов правильнее было бы использовать термин issueTicket, что точнее отражает бизнес-процесс.
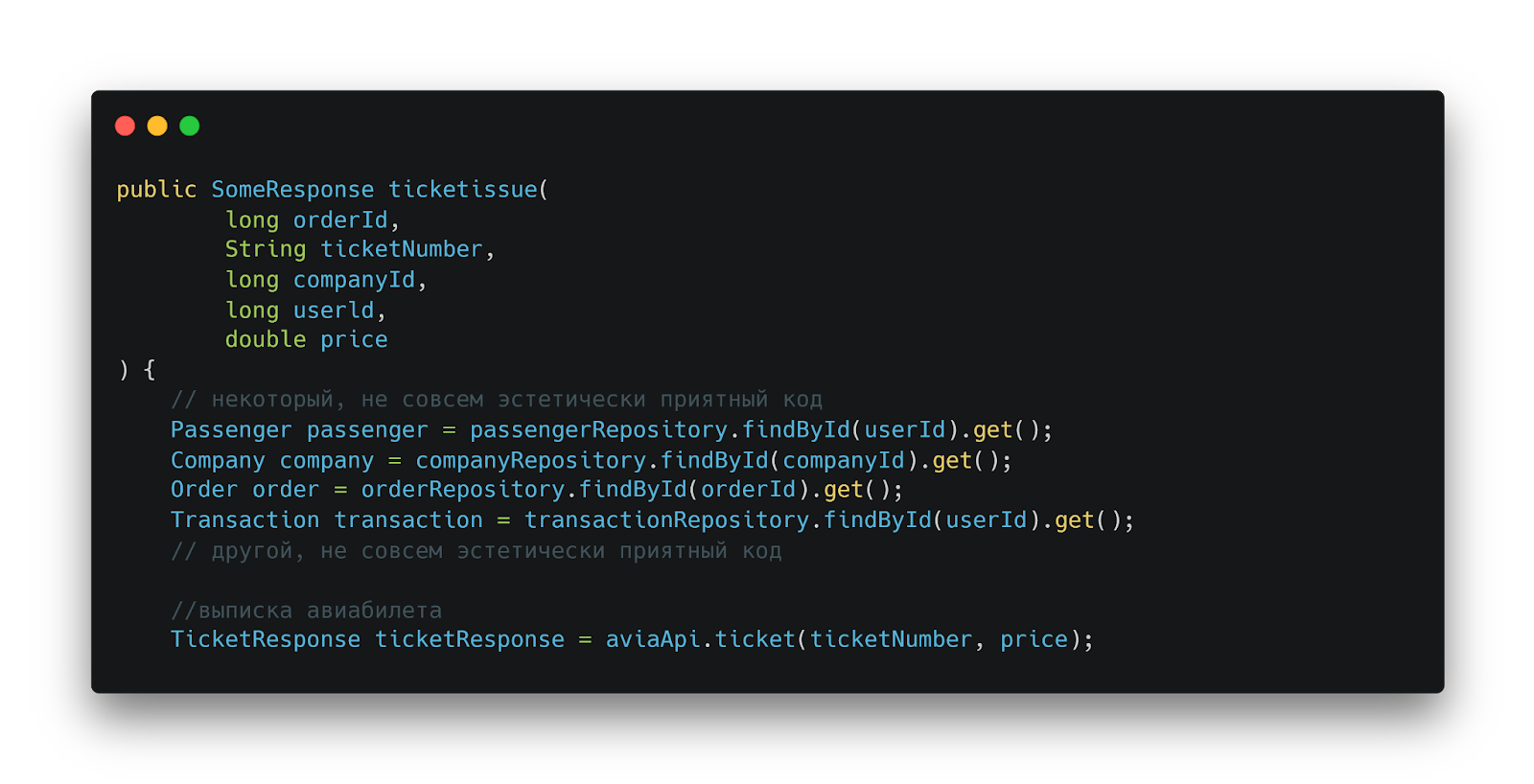
Метод ticketIssue: пример несоответствия именования принятому в домене языку (issueTicket было бы корректнее)
Помимо проблемы с названием, метод демонстрирует и другие типичные проблемы legacy-кода:
- Большое количество аргументов;
- Небезопасное использование .get() без проверки на наличие значения;
- Отсутствие явного разделения бизнес-логики.
Погружение в Legacy: анатомия системы расчета сборов
При первом взгляде на метод расчета сервисного сбора открывается классическая картина legacy-кода. В теле метода творится настоящее «волшебство» – множество строк кода, выполняющих различные проверки и манипуляции с данными. Однако самое интересное скрывается на 56-й строке.
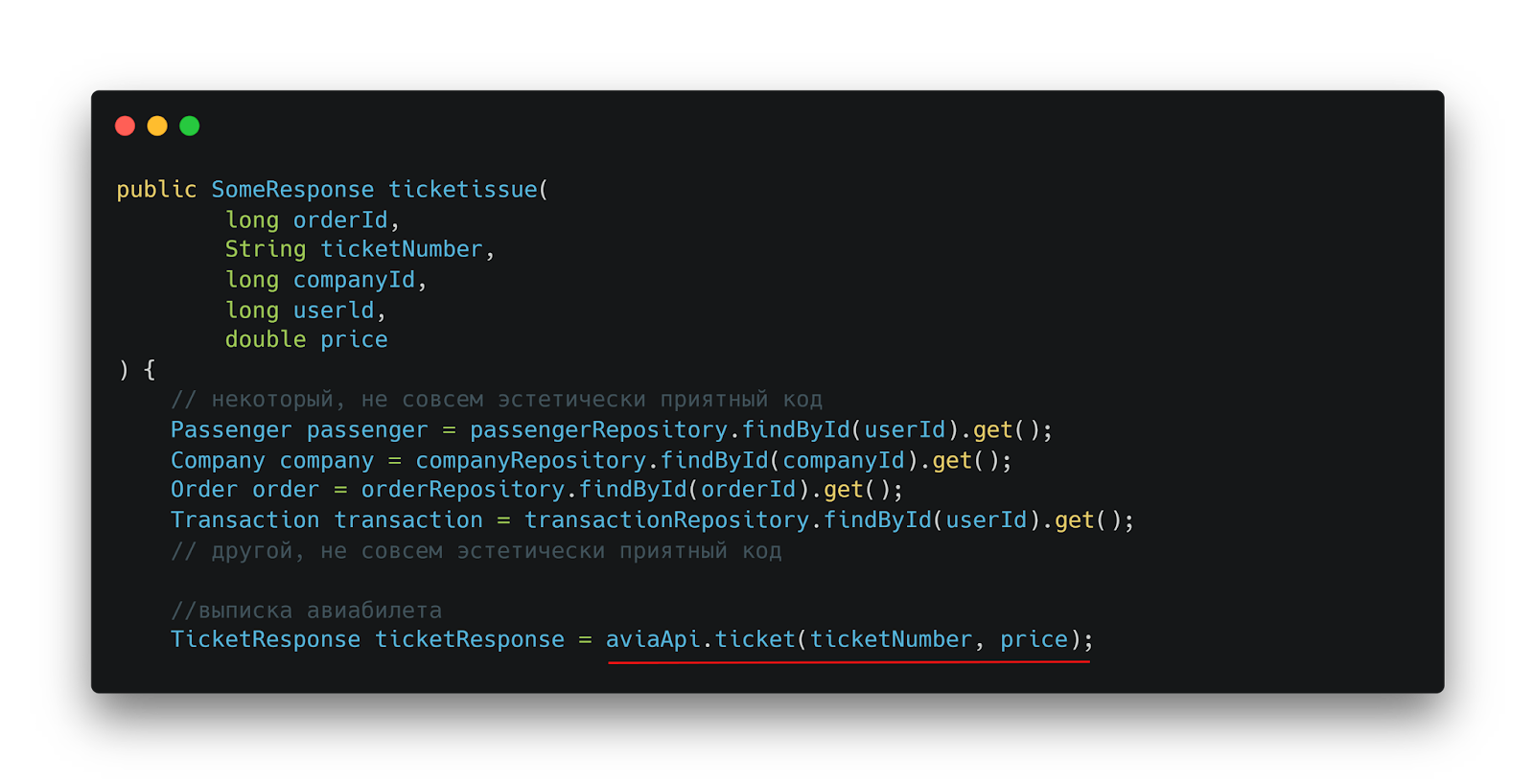
Длинный метод расчёта сборов: проверки, ветвления и ключевая логика, спрятанная в середине тела метода
После прохождения всех проверок и подготовительных действий код наконец добирается до своей истинной цели – вызова авиационного API для выписки билета. Именно здесь начинается самое интересное.
Процесс расчета сервисного сбора реализован весьма своеобразно. Стоимость билета умножается на некий загадочный коэффициент, который просто зашит прямо в коде.
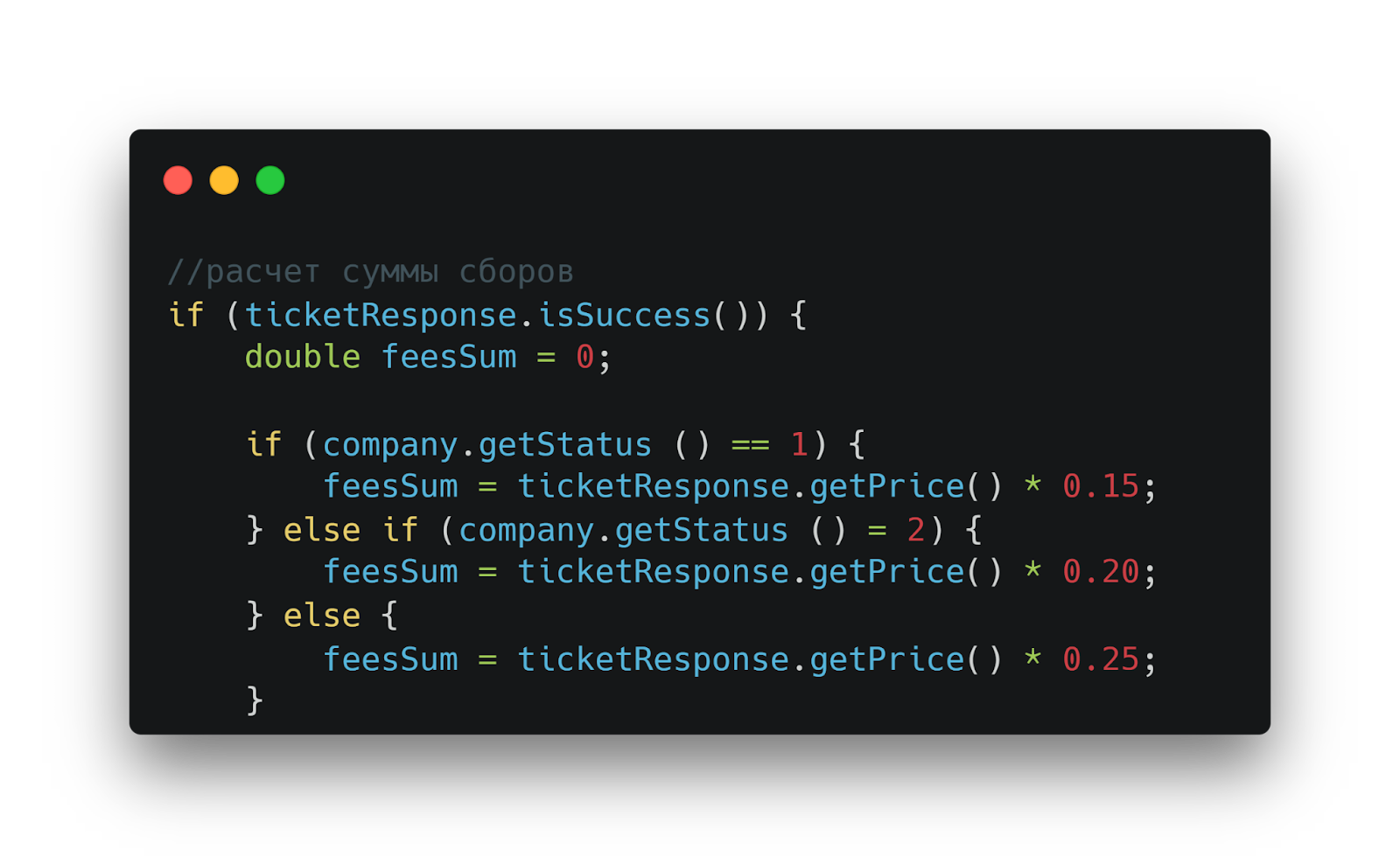
Расчёт сервисного сбора: стоимость билета умножается на «магический» коэффициент, зашитый в код
Но это только начало увлекательного путешествия по дебрям legacy. Сам коэффициент зависит от неких целочисленных статусов компаний, природа которых остается загадкой для любого нового разработчика.
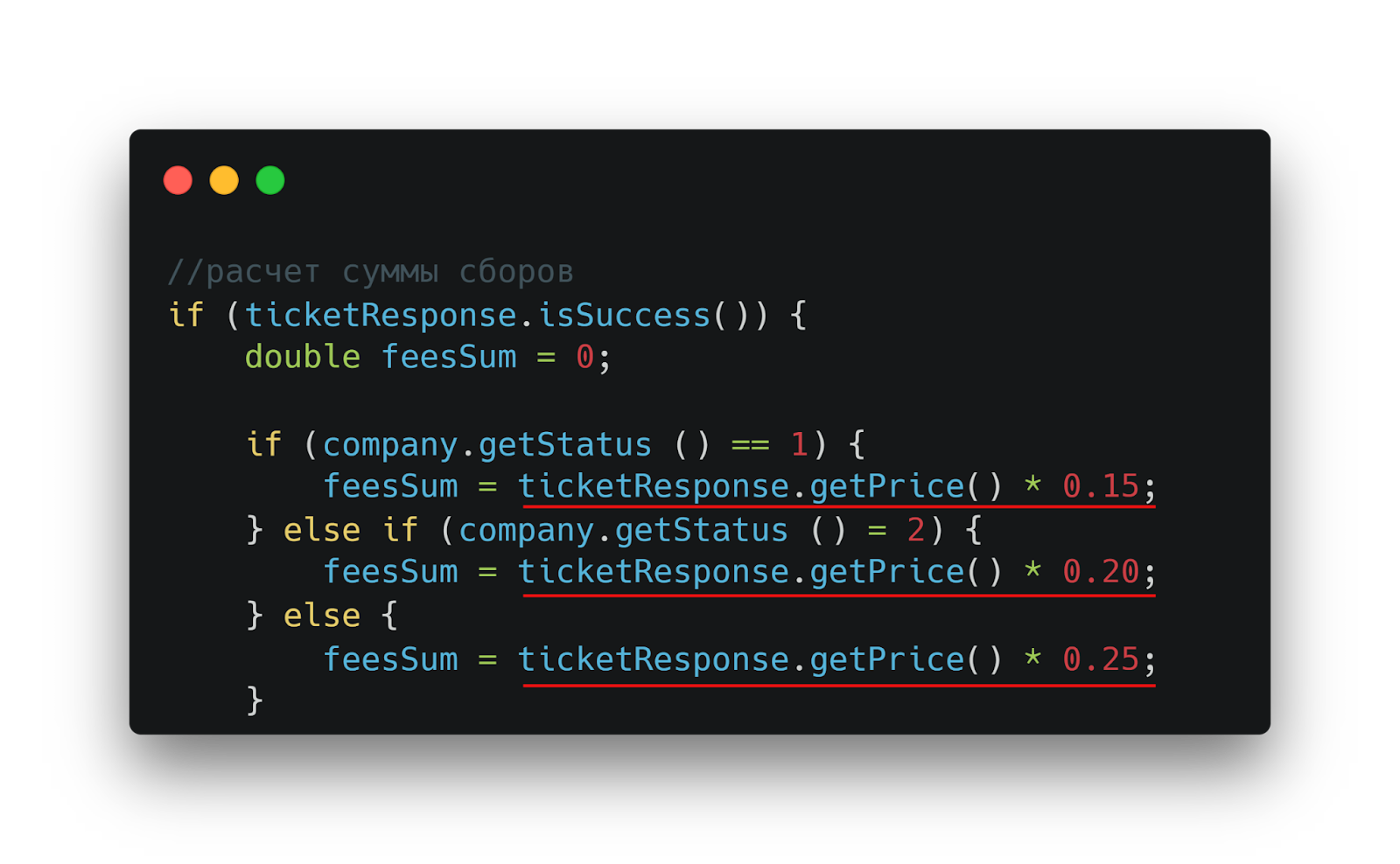
Неочевидная бизнес-логика: коэффициент зависит от числовых статусов компании, смысл которых неочевиден разработчику
«Креативное» хранение данных

После расчета сбора начинается настоящее приключение с сохранением данных. База данных используется с поистине творческим размахом — данные одновременно записываются в три разные таблицы.
Но и этого оказалось недостаточно! В системе обнаруживается четвертая таблица — company — с загадочным полем FEESAM. Именно в такие моменты разработчику приходится включать режим детектива.
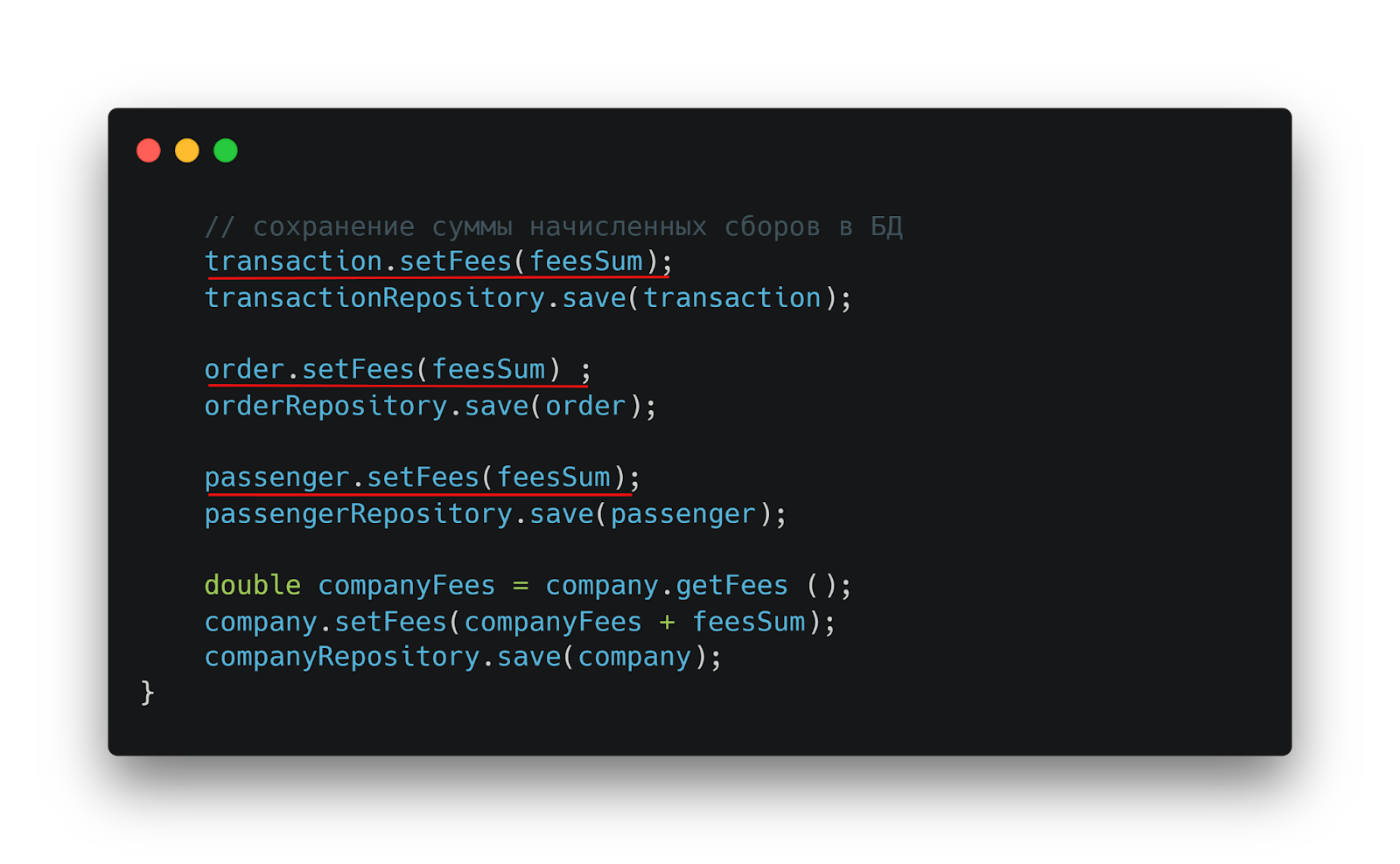
«Креативное» хранение данных: сервисные сборы одновременно записываются в три разные таблицы
Применяя метод дедукции, можно предположить, что company в данном контексте — это клиент бизнеса, FEESAM хранит сумму всех начисленных сборов, а загадочный целочисленный код представляет статус клиента в программе лояльности.
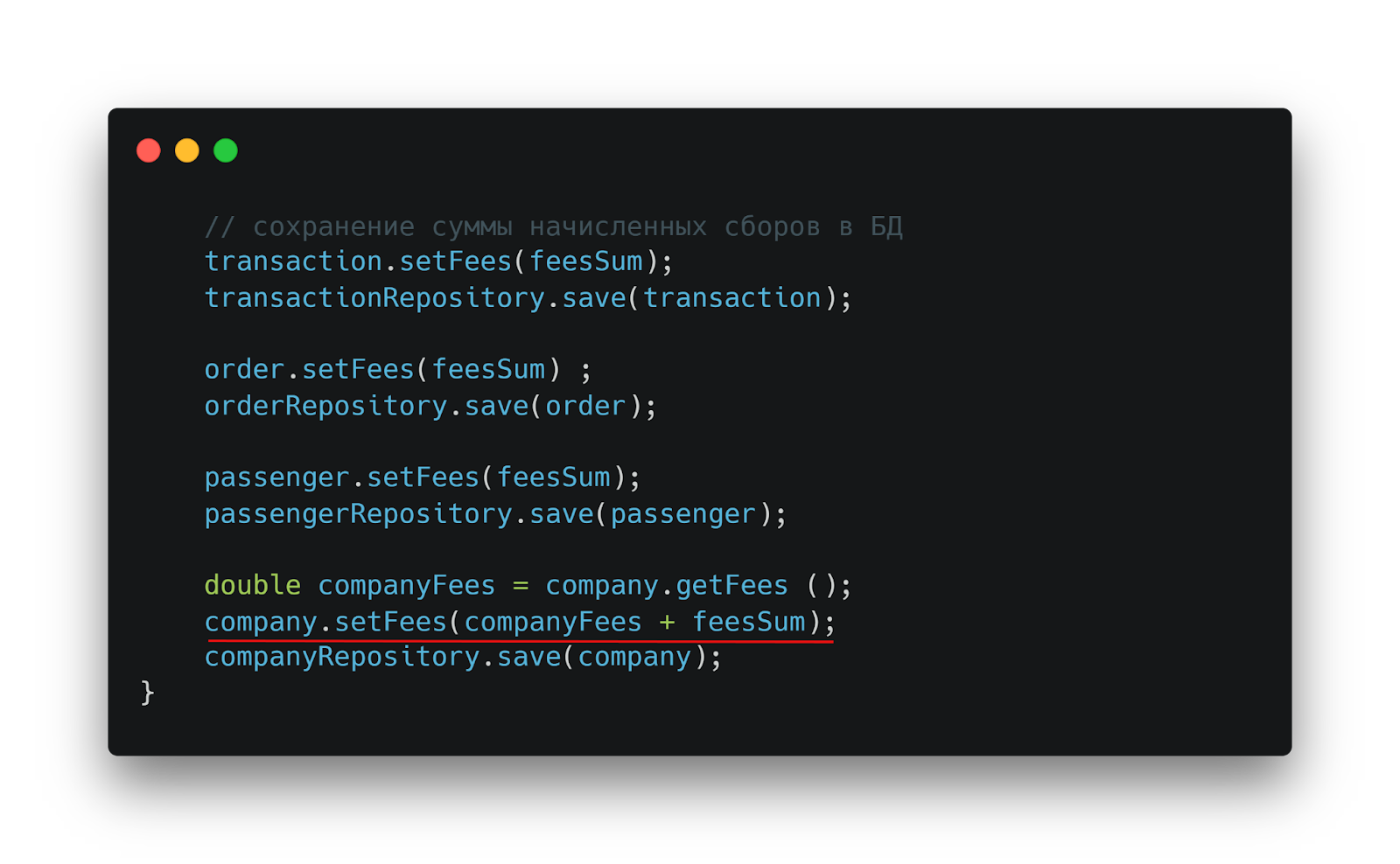
Поле FEESAM в таблице company: сумма всех начисленных сборов, завязанная на неочевидный статус клиента
При взгляде на структуру таблиц в базе данных становится очевидным: система отчаянно нуждается в переработке. Денормализация данных, дублирование информации и отсутствие четких связей между таблицами создают благодатную почву для потенциальных ошибок и усложняют поддержку системы.

Денормализованная база: дублирующиеся данные и слабые связи между таблицами осложняют развитие системы
Глядя на это «великолепие», становится понятно — пришло время для серьезных изменений. Дальнейшие рассуждения стоит направить в сторону выявления границ смыслового ядра в коде, его изоляции и обеспечения надежного взаимодействия с остальной системой.
Выявление смыслового ядра
В этом нелегком деле на помощь приходит паттерн «Дистилляция» из арсенала DDD. И речь идет о стратегическом паттерне domain-driven design, позволяющем отделить смысловое ядро от всего лишнего, сохранив саму суть.
«Дистилляция»: выделение ядра начисления сборов и отделение его от вспомогательной логики

Тщательный анализ исходного кода в сочетании с продуктивными обсуждениями с бизнес-аналитиками позволил выявить ключевой процесс уровня смыслового ядра – расчет суммы сбора на основе стоимости билета с учетом статусов клиентов в программе лояльности.
Для начала посмотрим на структуру проекта после применения паттерна дистилляции:
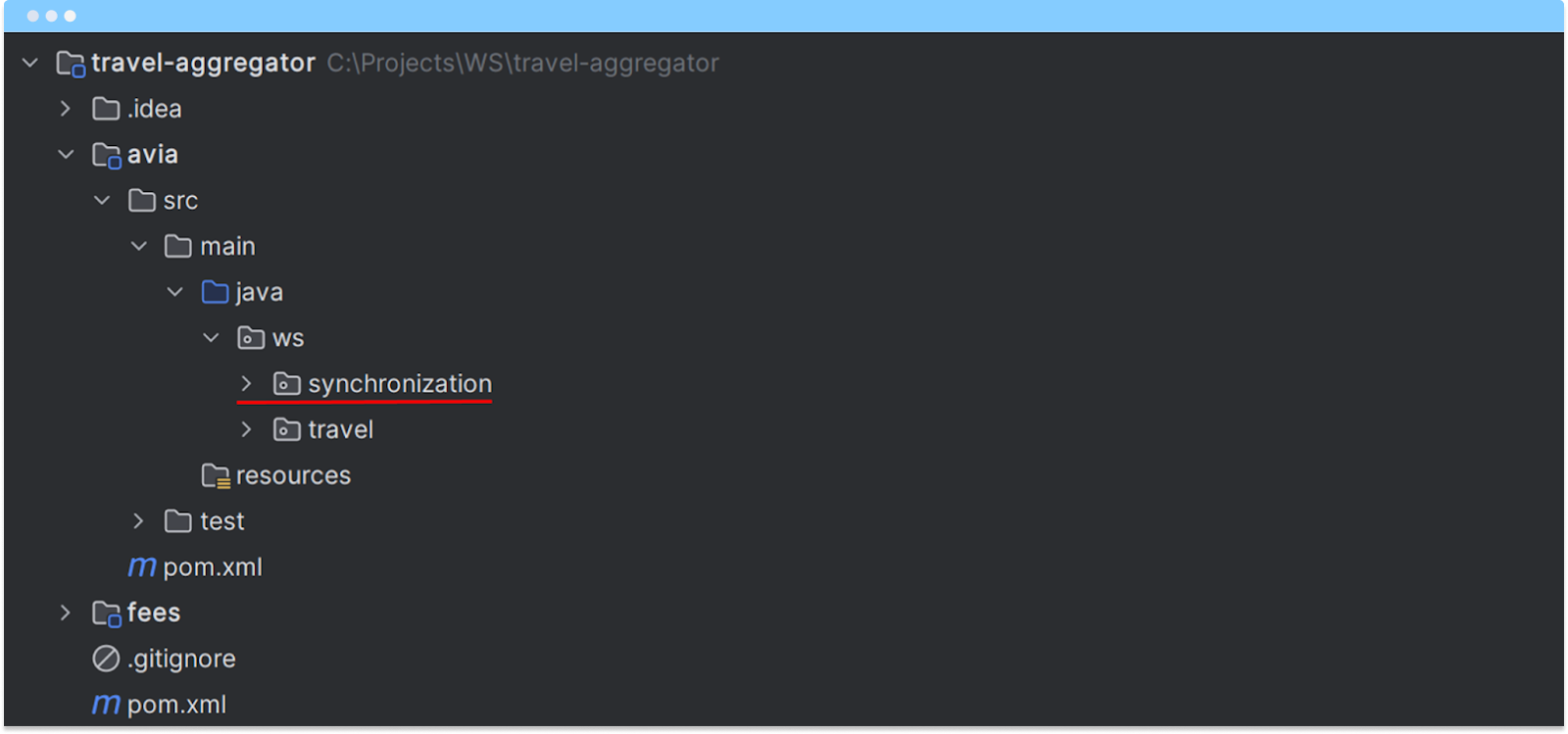
Результат дистилляции: legacy-модуль avia и новый модуль fees с выделенным ядром сервисных сборов
В результате рефакторинга появилась четкая структура с разделением на:
- Модуль avia — существующая legacy-система;
- Модуль fees — новая подсистема сервисных сборов.
Строим новую структуру: реализация смыслового ядра
При практической реализации DDD разделили систему на два основных модуля: avia (существующая legacy-система) и fees (новая подсистема сборов). На данном этапе весь функционал реализован в рамках монолита. К вопросу о монолитной и микросервисной архитектурах вернемся позже, а пока рассмотрим реализацию REST-контроллера:
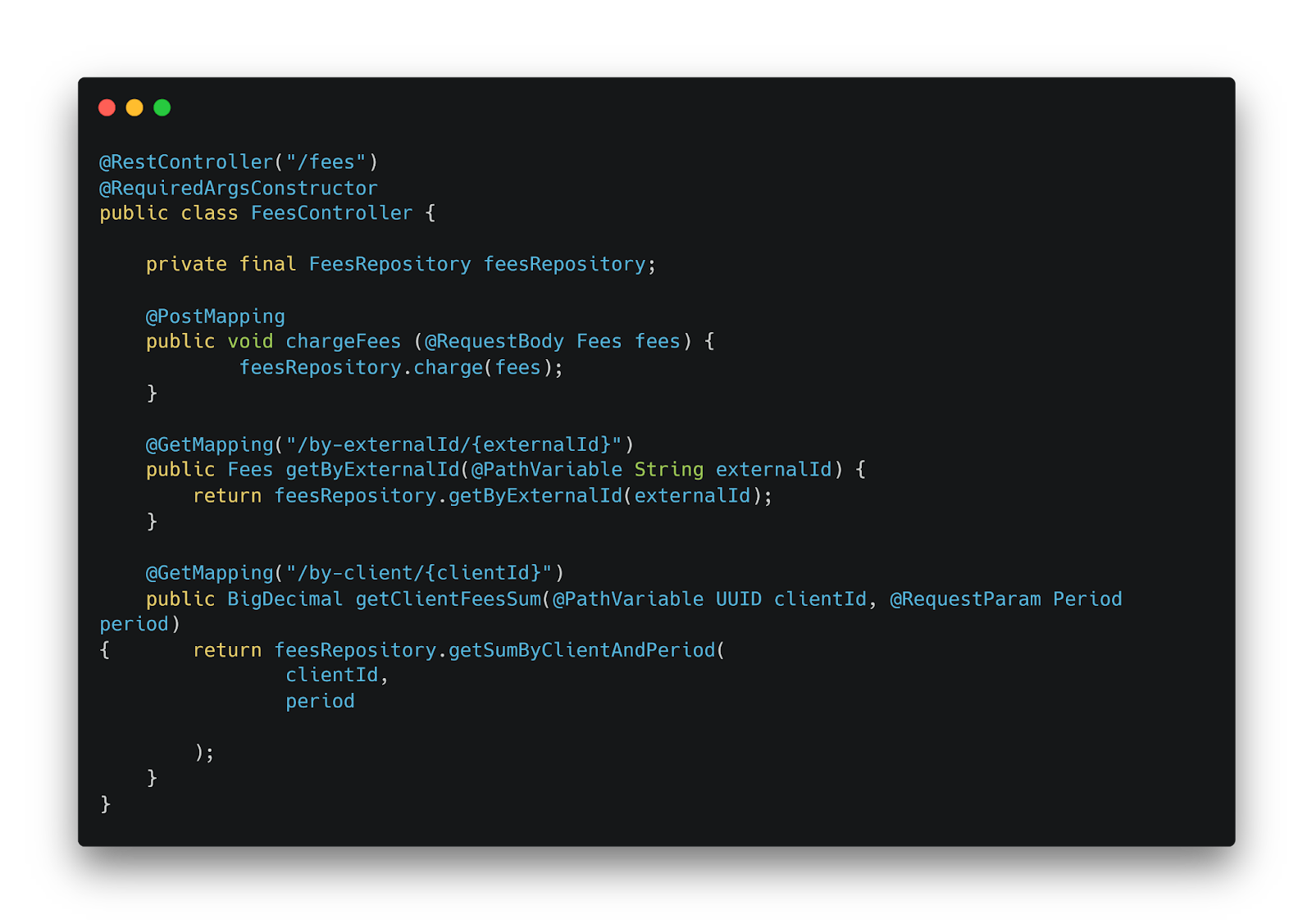
FeesController — точка входа в ядро: методы для расчёта и получения данных о сервисных сборах
REST-контроллер FeesController стал точкой входа в смысловое ядро. В нем реализованы три основных метода:
- chargeFees для расчета и начисления сборов;
- getByExternalId для получения данных о начисленных сборах по внешнему идентификатору;
- getClientFeesSum для получения суммы сборов по идентификатору клиента за период.
Метод chargeFees принимает модель fees, содержащую все необходимые для расчета данные. В качестве зависимости контроллер работает с FeesRepository — репозиторием уровня бизнес-логики, а не стандартным JPA-репозиторием.
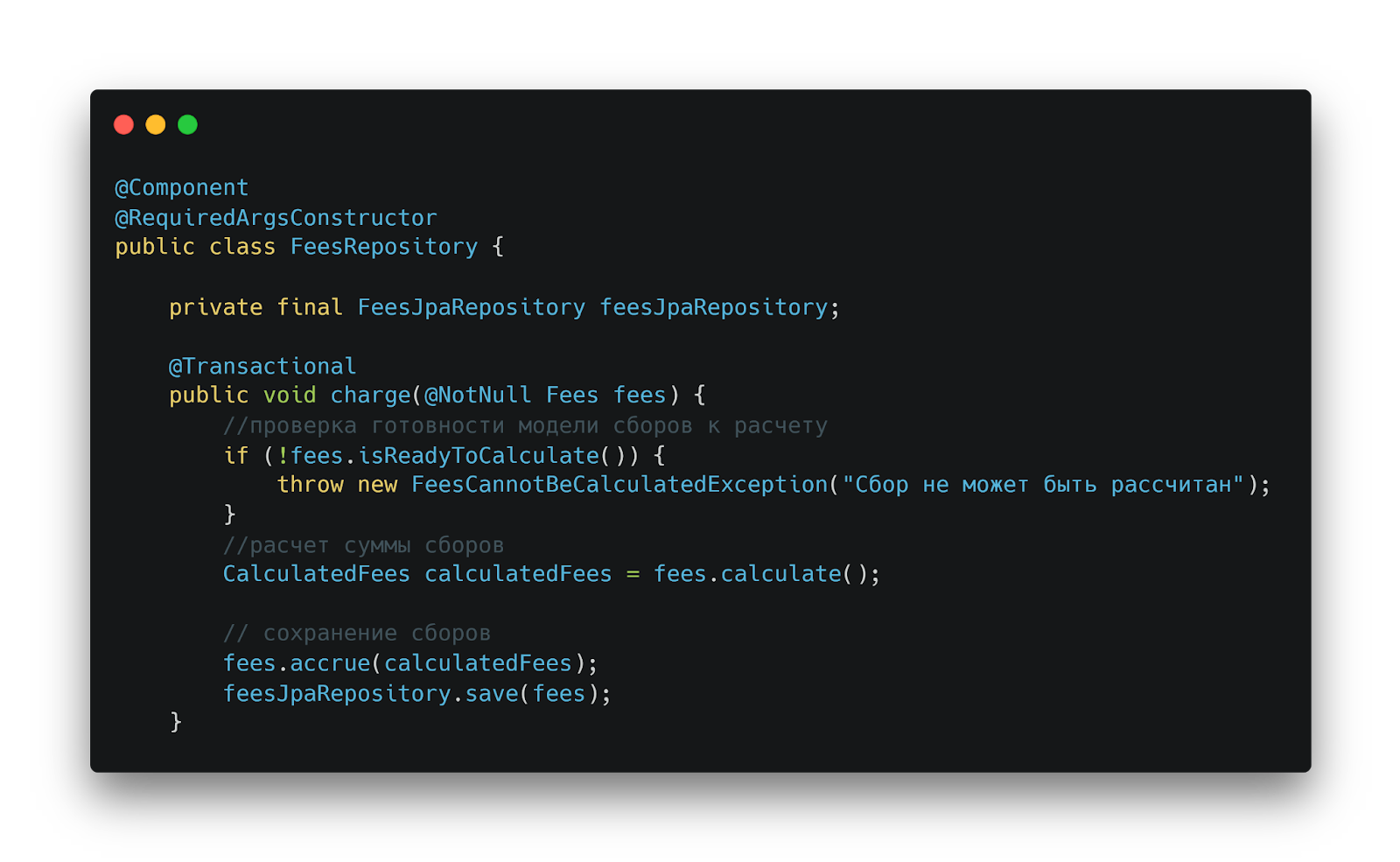
FeesRepository: репозиторий бизнес-логики, отвечающий за оркестрацию расчёта и сохранения сборов
Основная задача репозитория — оркестрация транзакций. JPA-репозиторий используется внутри для непосредственного сохранения модели в базу данных. Обработка запроса включает:
- Валидацию модели на готовность к расчету;
- При невалидных данных или уже рассчитанной сумме сбора — выброс исключения;
- Расчет суммы сервисного сбора;
- Начисление и сохранение в базу данных.
Вся бизнес-логика инкапсулирована внутри модели Fees, а репозиторий выступает оркестратором. В данном примере можно было обойтись без репозитория, делегировав логику модели, но в реальных проектах с множеством сложных процессов оркестрация необходима.
Модель Fees: прагматичный подход к DDD

Модель Fees: прагматичная доменная модель на основе ORM-сущности с инкапсулированной логикой расчёта
При проектировании модели Fees пришлось найти баланс между чистотой DDD и практичностью. В результате модель основана на ORM-сущности — решение, которое заставит вздрогнуть приверженцев чистого DDD. В реальности построить полноценную доменную модель на основе ORM-сущности сложно, так как ее жизненным циклом управляет ORM, а не бизнес-процессы. Но для демонстрации подхода такое решение оптимально.
Модель инкапсулирует все необходимые данные:
- Внутренний целочисленный ID;
- Внешний строковый ID для интеграции с legacy;
- ID клиента;
- Сумма сбора;
- База расчета (стоимость билета);
- Список политик лояльности.
Bubble Context и защита границ
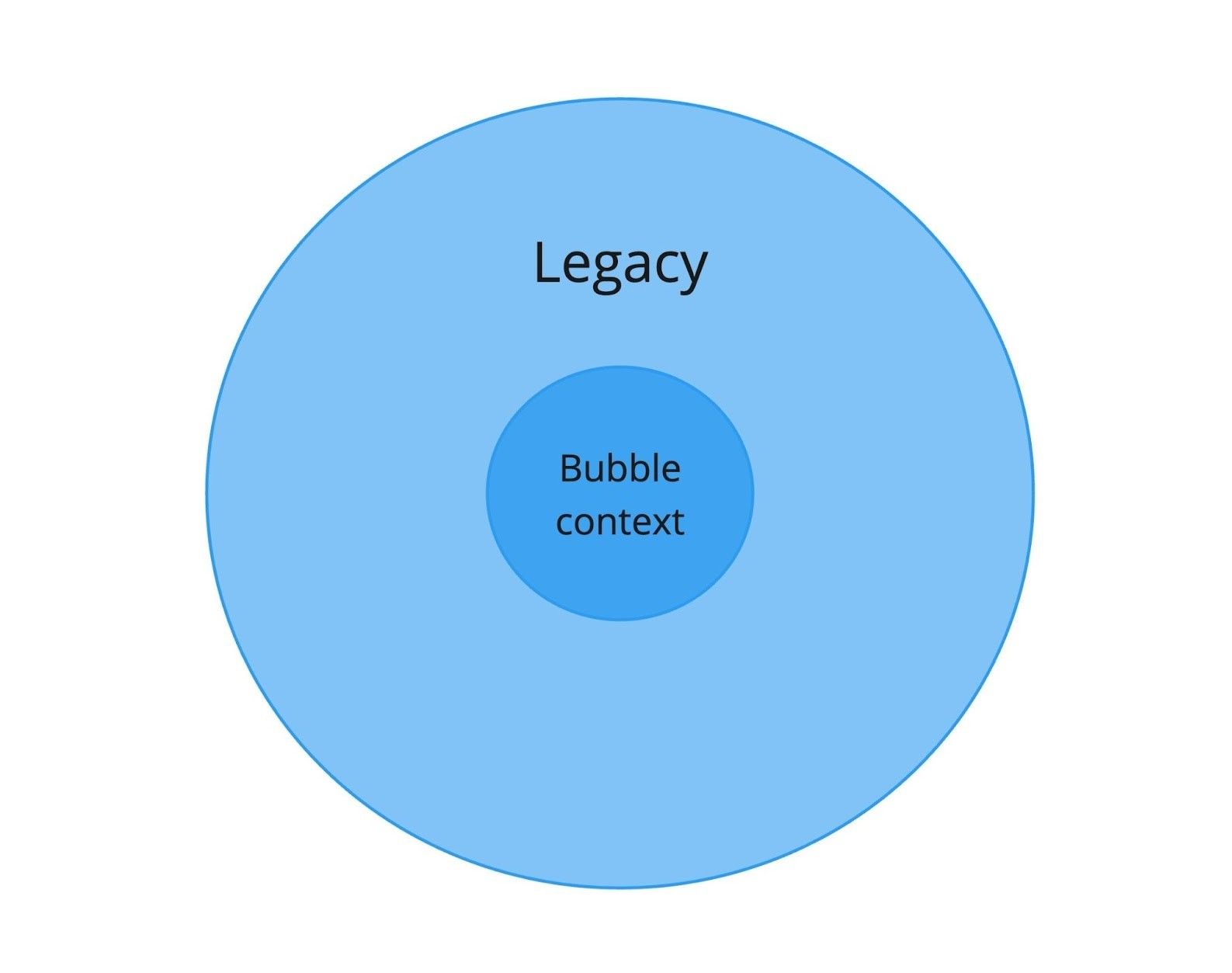
Bubble Context: изолированное ядро в море legacy-кода
В результате рефакторинга образовался так называемый bubble context — «пузырь» чистого кода в море legacy. Теперь важно правильно организовать поток данных между старой и новой частями системы.

Защита ядра от внешних воздействий
Legacy-система с ее хаотичностью и аномалиями рассматривается как внешняя, которой нельзя доверять. Задача следующего этапа — обеспечить защищенное взаимодействие между компонентами, не допуская проникновения старых моделей в новый код.
Защита нового кода: внедрение Anti-Corruption Layer
При работе с legacy-системами одна из основных задач — обеспечить безопасное взаимодействие между старым и новым кодом. В DDD для этого есть специальный паттерн — Anti-Corruption Layer (ACL) или предохранительный уровень.
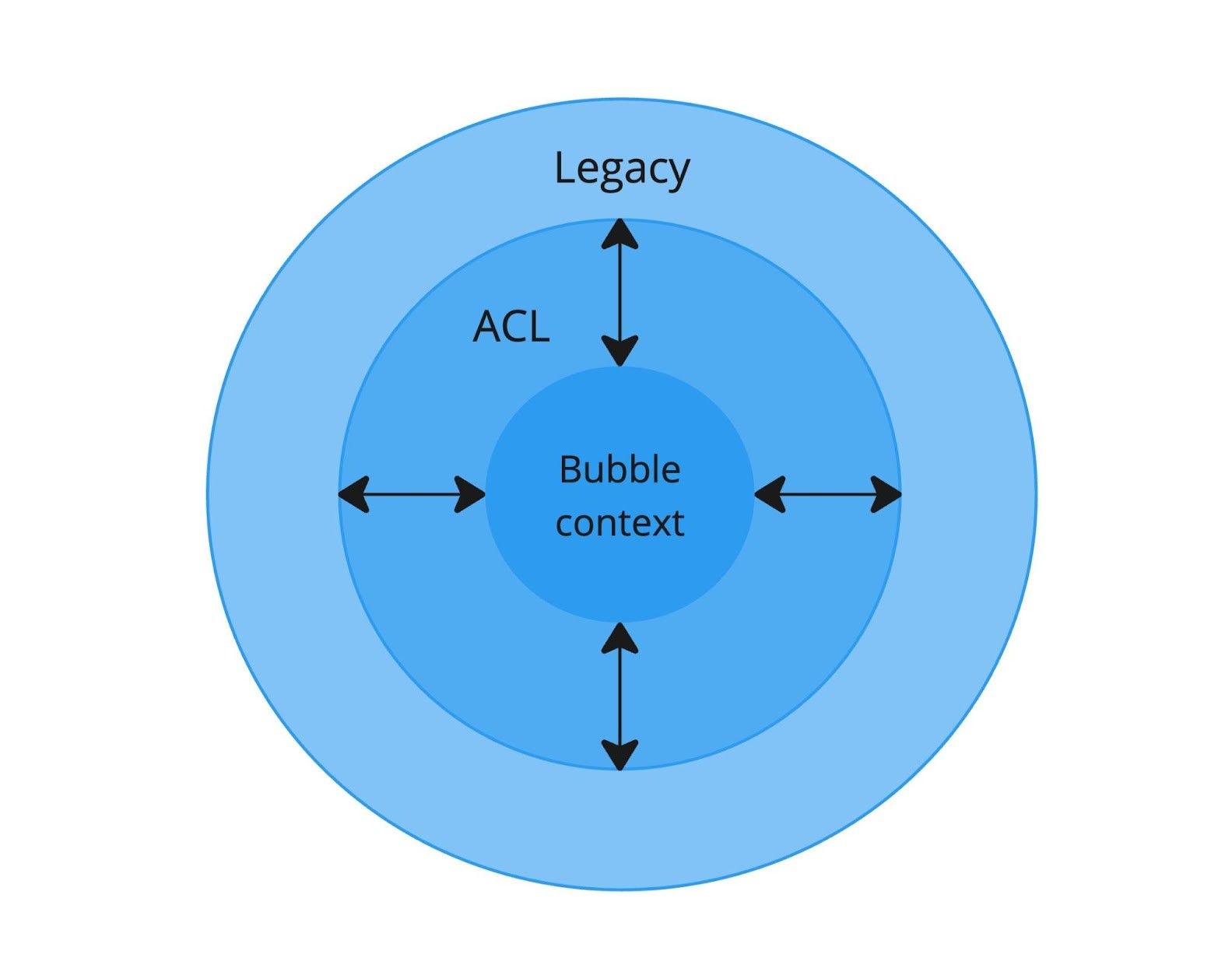
ACL как защитный слой между legacy-системой и новым кодом
ACL выполняет две важные функции. Во-первых, защищает legacy-систему от изменений в смысловом ядре. Ведь ядро только появилось, оно будет развиваться и меняться, но при этом старая платформа должна стабильно работать с функционалом сборов. Во-вторых, защищает новый код от «загрязнения» legacy-системой.
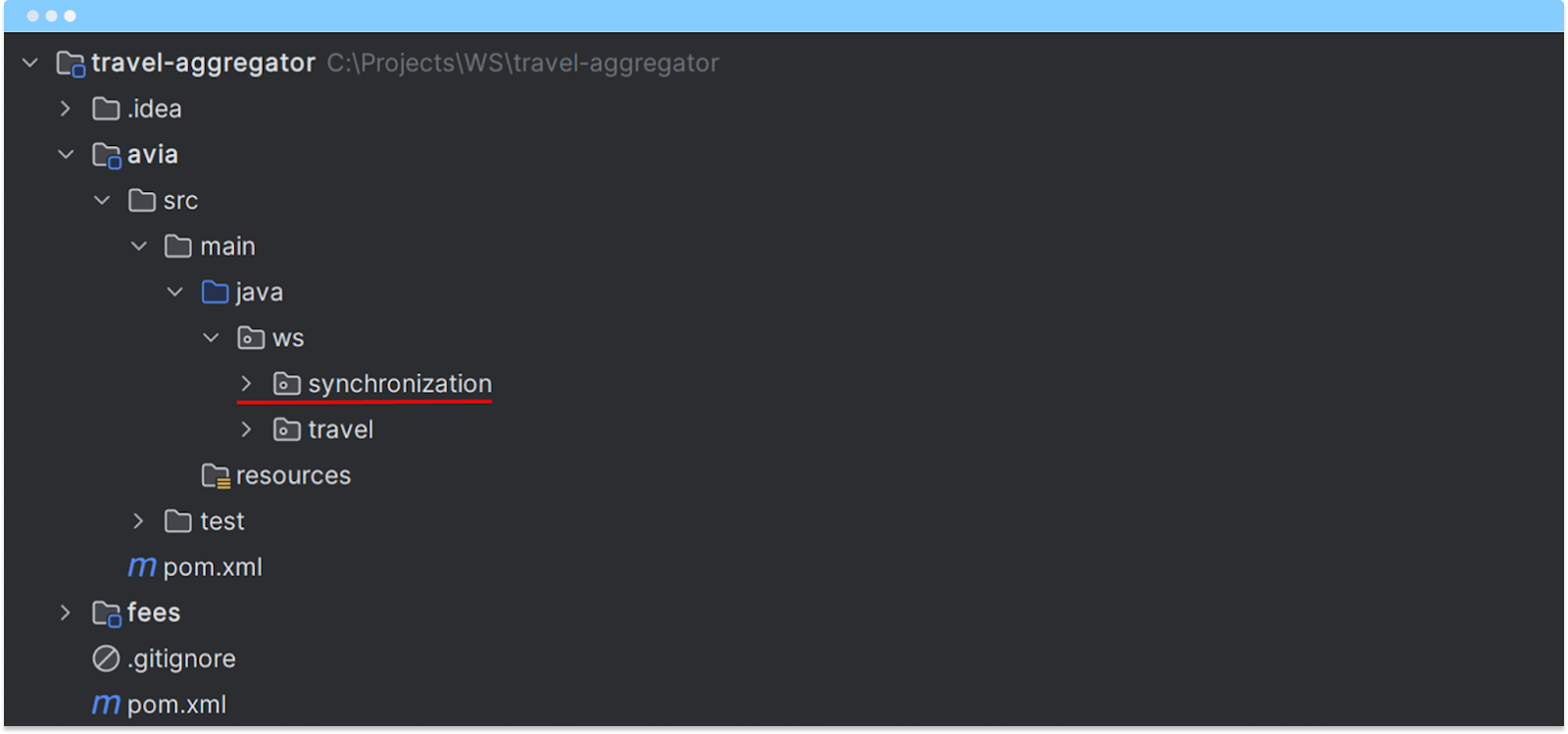
Структура проекта с выделенным пакетом synchronization
В модуле avia создали пакет synchronization — размещение ACL. Такое расположение выбрано для текущей монолитной архитектуры, хотя в других ситуациях ACL может быть вынесен в отдельный модуль или даже сервис.
Интерфейс взаимодействия
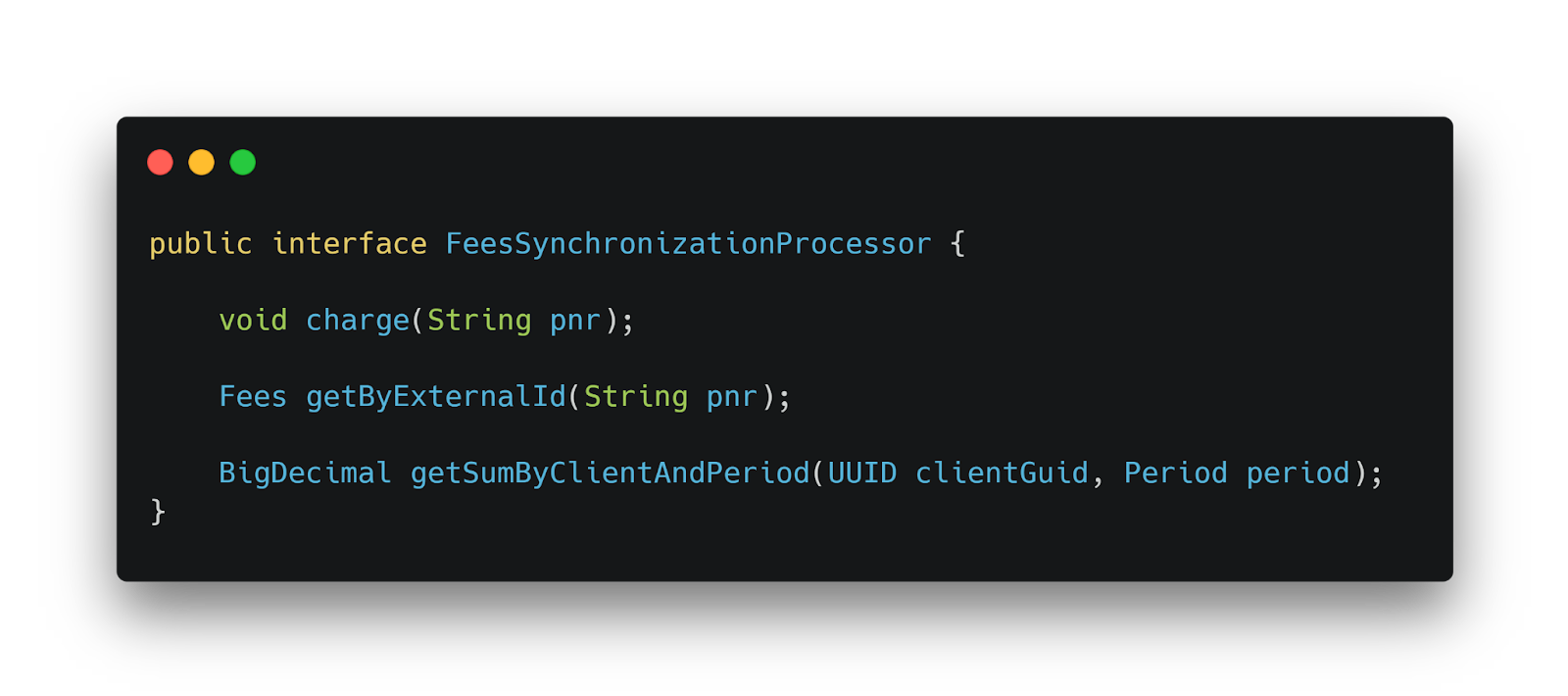
Интерфейс FeesSynchronizationProcessor для взаимодействия с legacy-системой
Ключевой элемент ACL — интерфейс для взаимодействия legacy-системы с новым функционалом сборов. Он предоставляет три метода:
- charge для расчета и начисления сборов;
- getByExternalId для получения данных по внешнему идентификатору;
- getSumByClientAndPeriod для получения суммы сборов за период.
Реализация адаптера

Адаптер LegacyFeesSynchronizationProcessor
Адаптер принимает на вход PNR (Passenger Name Record) — естественный уникальный идентификатор в предметной области авиаперевозок. По этому номеру происходит получение информации о билете и списка политик лояльности из старой базы данных, после данные трансформируются в новую модель Fees.
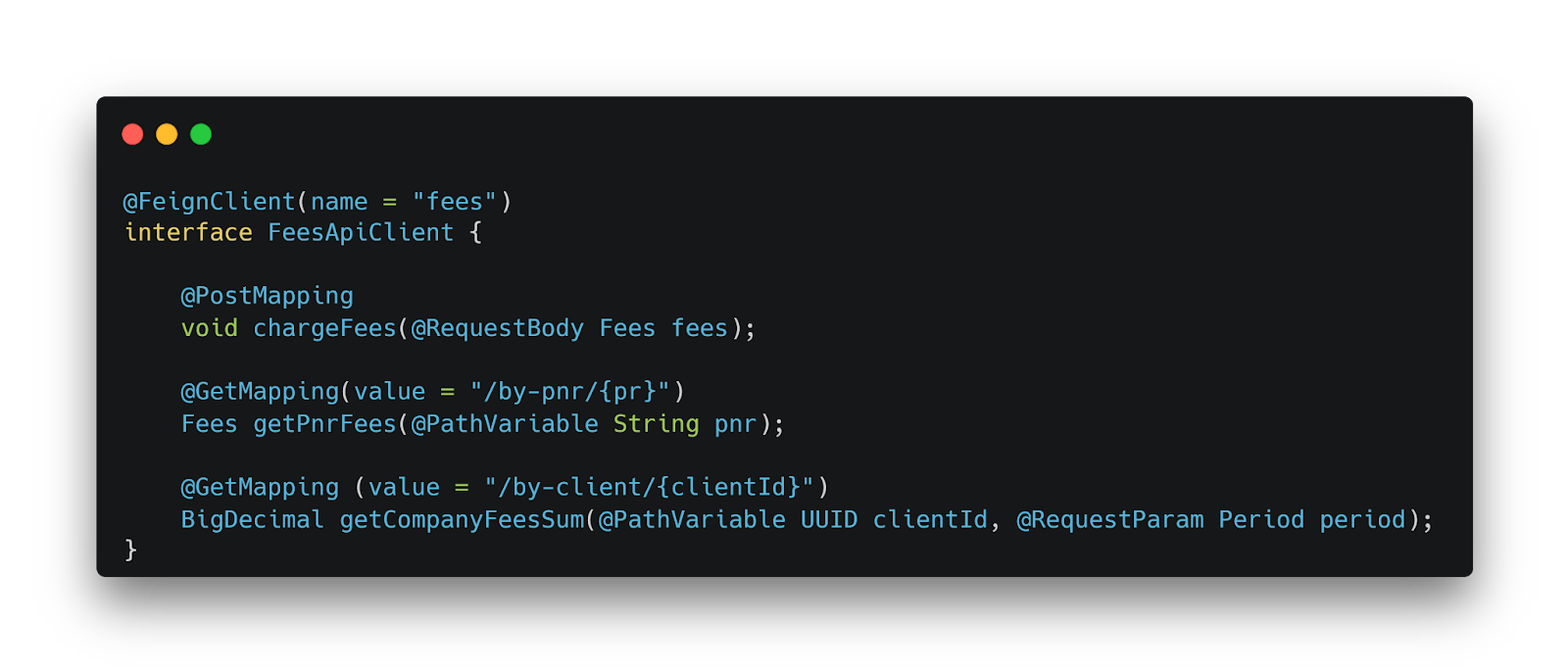
HTTP-клиент для взаимодействия с новым API
Для взаимодействия с новым API использовали Feign-клиент с package-private уровнем доступа. Это технически ограничивает возможность legacy-системы напрямую вызывать новый функционал, минуя предохранительный уровень.
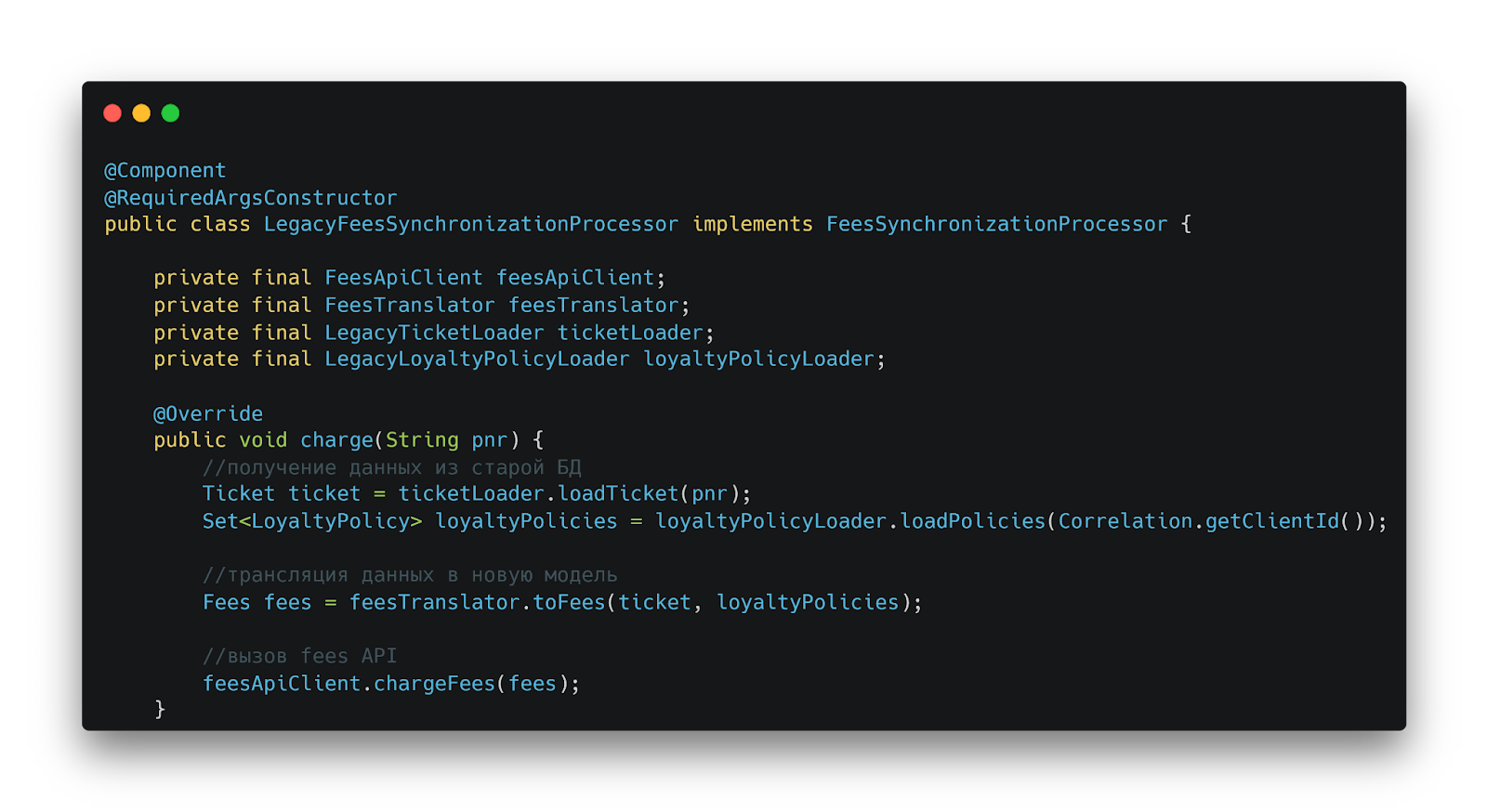
Процесс трансляции данных через ACL
Интересный момент возник при работе со списком политик лояльности. Хотя функционал программы лояльности еще не переработан, уже сейчас адаптер транслирует старые целочисленные статусы в новую структуру политик лояльности. Это подготовка к будущим изменениям — ведь именно необходимость переработки программы лояльности стала триггером для всего рефакторинга.
Работа с данными: от legacy к современной архитектуре
В любом достаточно зрелом enterprise-проекте рано или поздно встает вопрос реорганизации данных. В нашем случае система обросла множеством связей: данные о сборах хранились сразу в четырех таблицах, что создавало серьезные проблемы с поддержкой и развитием функционала.
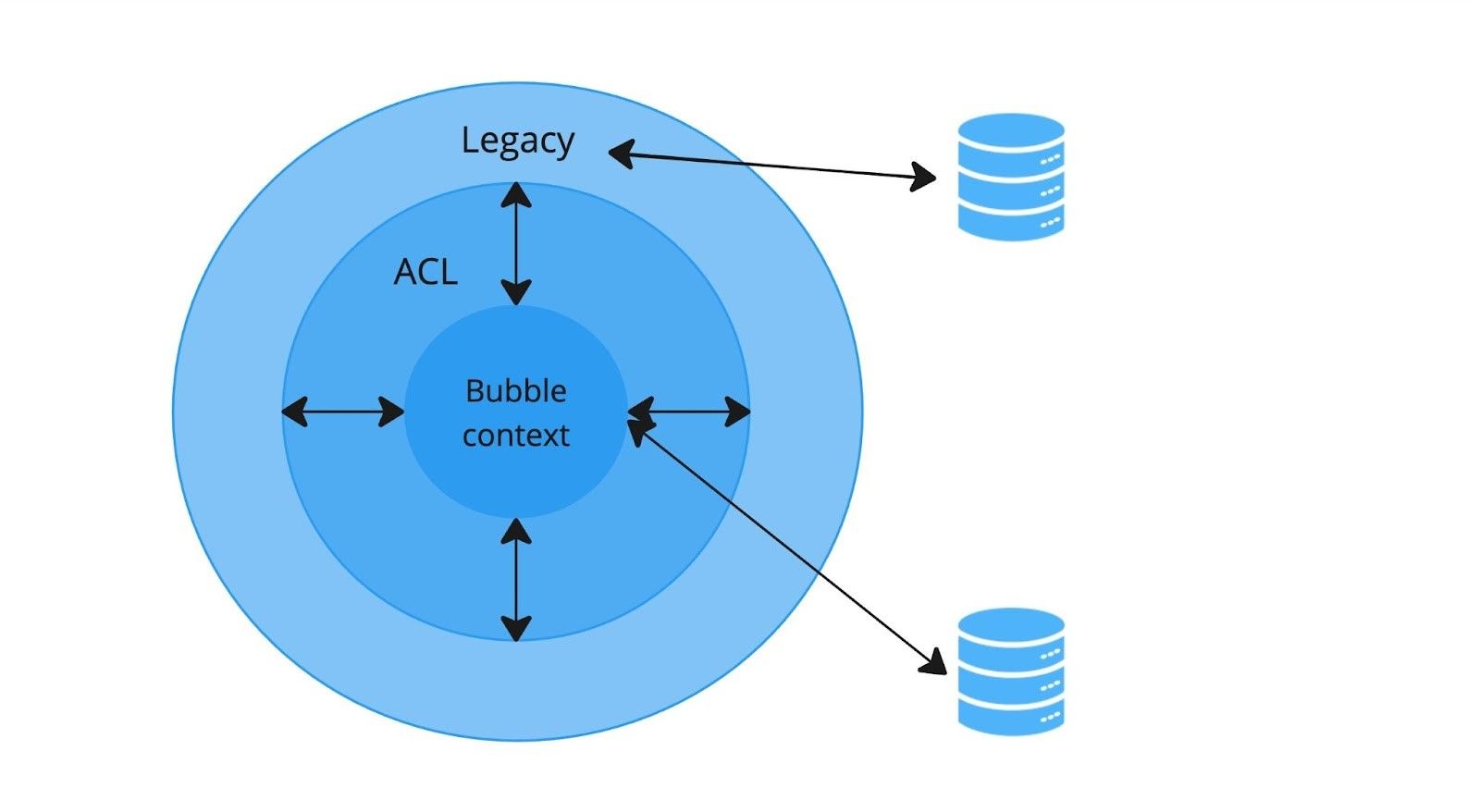
Общая схема взаимодействия: bubble context, ACL и базы данных
Перед командой встал выбор: либо аккуратно модифицировать существующую базу данных, либо создавать новую и организовывать процесс синхронизации. Для принятия решения пришлось глубоко погрузиться в текущую структуру данных.
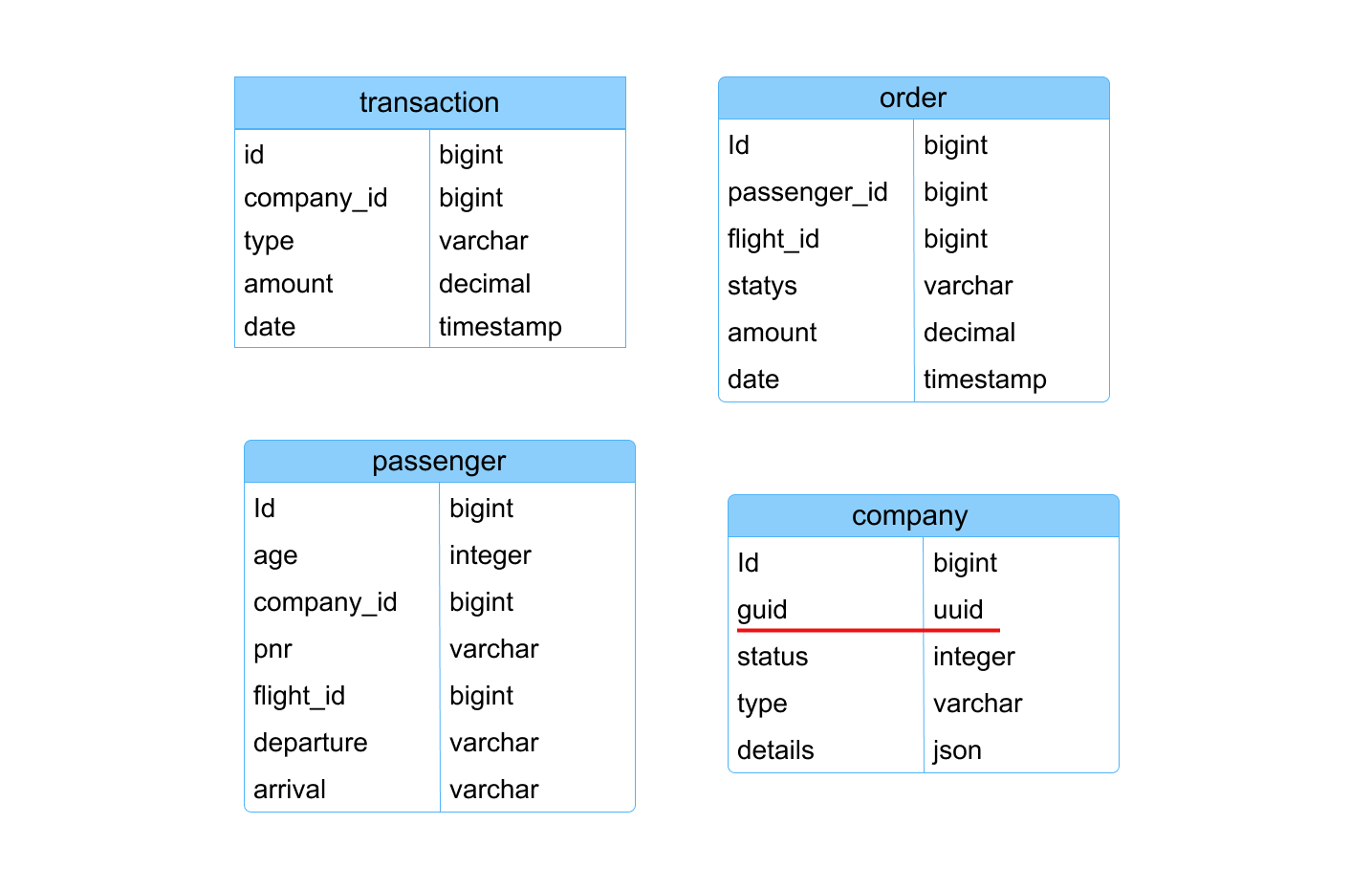
Исходная структура таблиц в legacy-системе
Анализ показал, что данные сильно денормализованы. В таблицах transaction, order, passenger и company информация дублируется, а некоторые поля используются не по назначению. Особенно это заметно в таблице company, где статус клиента хранится в виде простого целочисленного поля.

Новая структура таблицы fees
В новой архитектуре все данные о сборах собраны в одной таблице. Структура стала не только чище, но и гибче — например, поле loyaltyPolicies теперь хранит полноценный список политик лояльности в формате JSON, что упрощает будущие модификации.
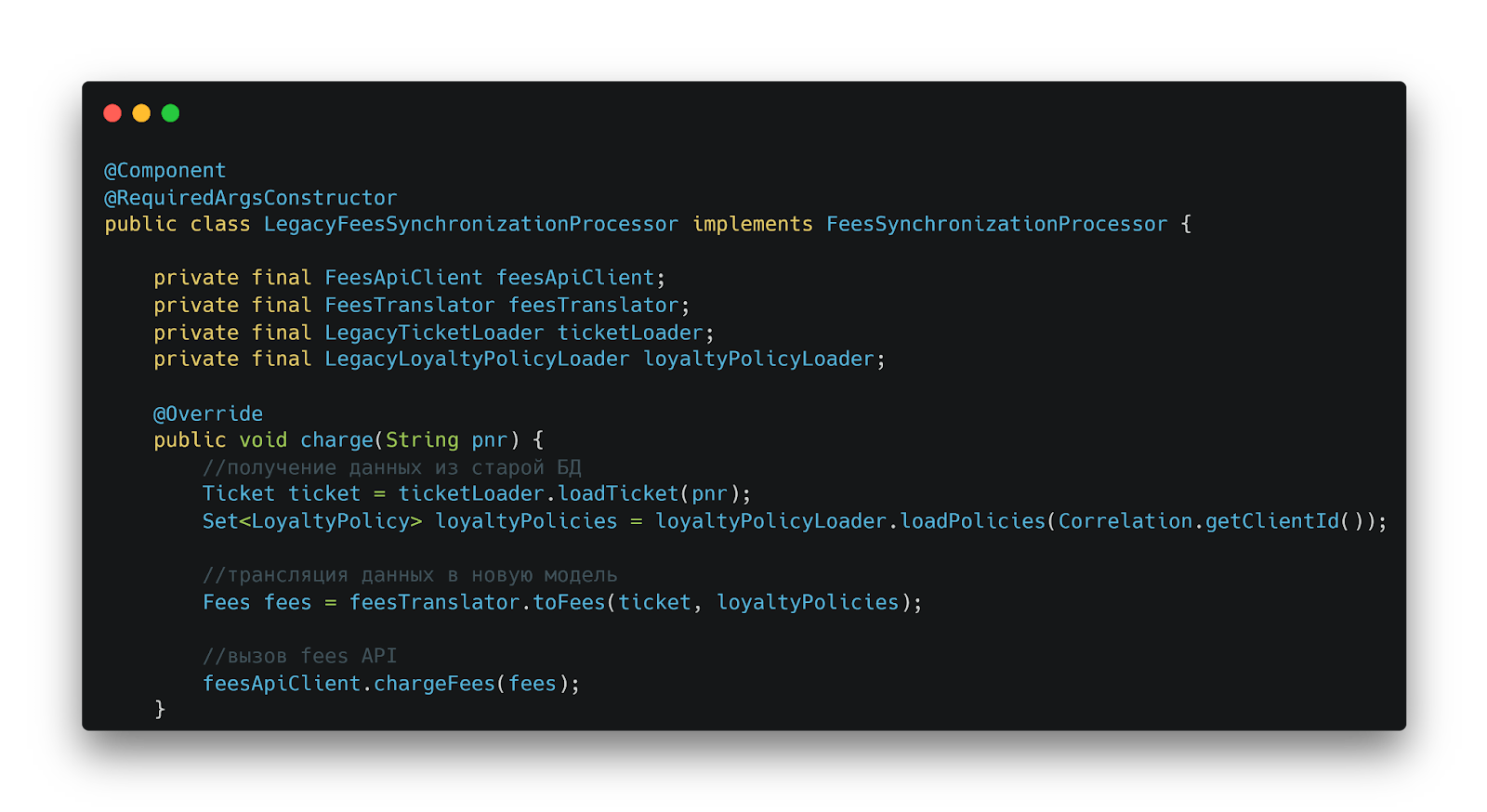
Реализация LegacyFeesSynchronizationProcessor
Для обеспечения плавного перехода разработан процессор синхронизации. Он отвечает за загрузку данных из старой БД, их трансформацию и передачу в новую систему. Каждый этап процесса четко определен: загрузка билета, получение политик лояльности, преобразование данных.
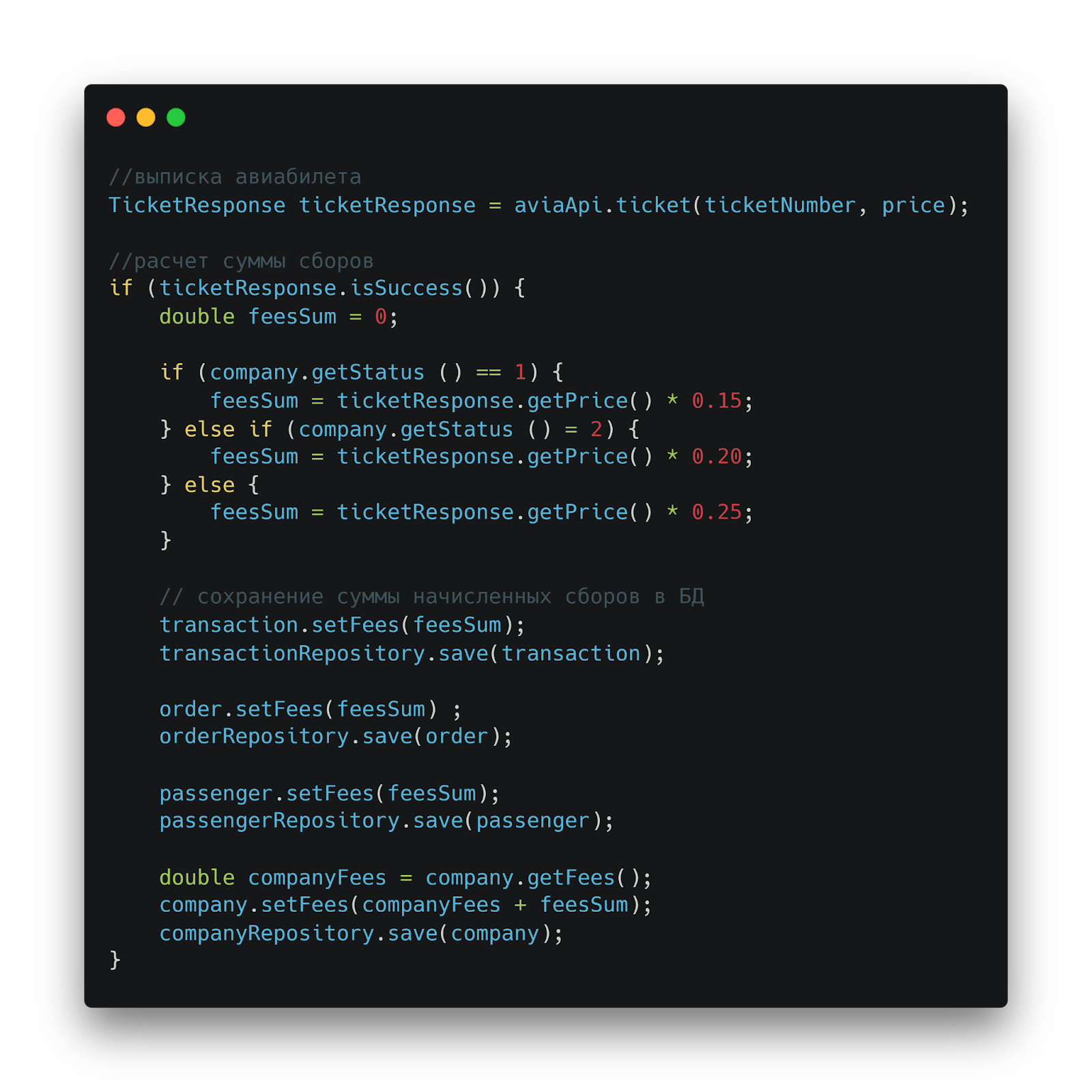
Оригинальный код расчета сборов
А вот как выглядел расчет сборов в старой системе. Магические числа для коэффициентов, множественные условные конструкции, прямые обращения к различным таблицам — классический пример кода, который срочно нуждается в рефакторинге.
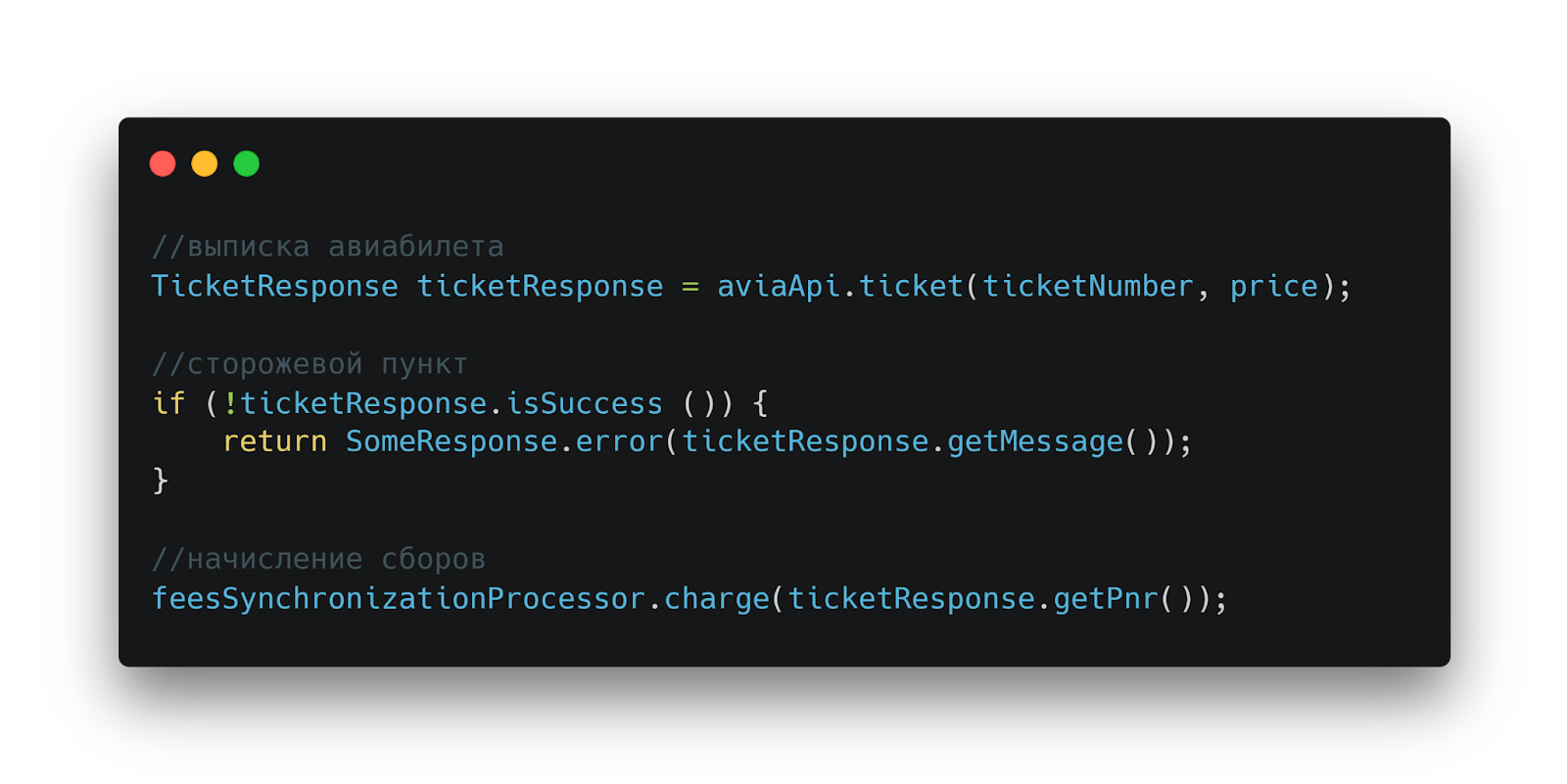
Упрощенный код выписки билета
После рефакторинга процесс выписки билета стал гораздо прозрачнее. Избавились от излишней вложенности кода за счет инверсии условий проверки — теперь при невалидных данных сразу возвращается ошибка.
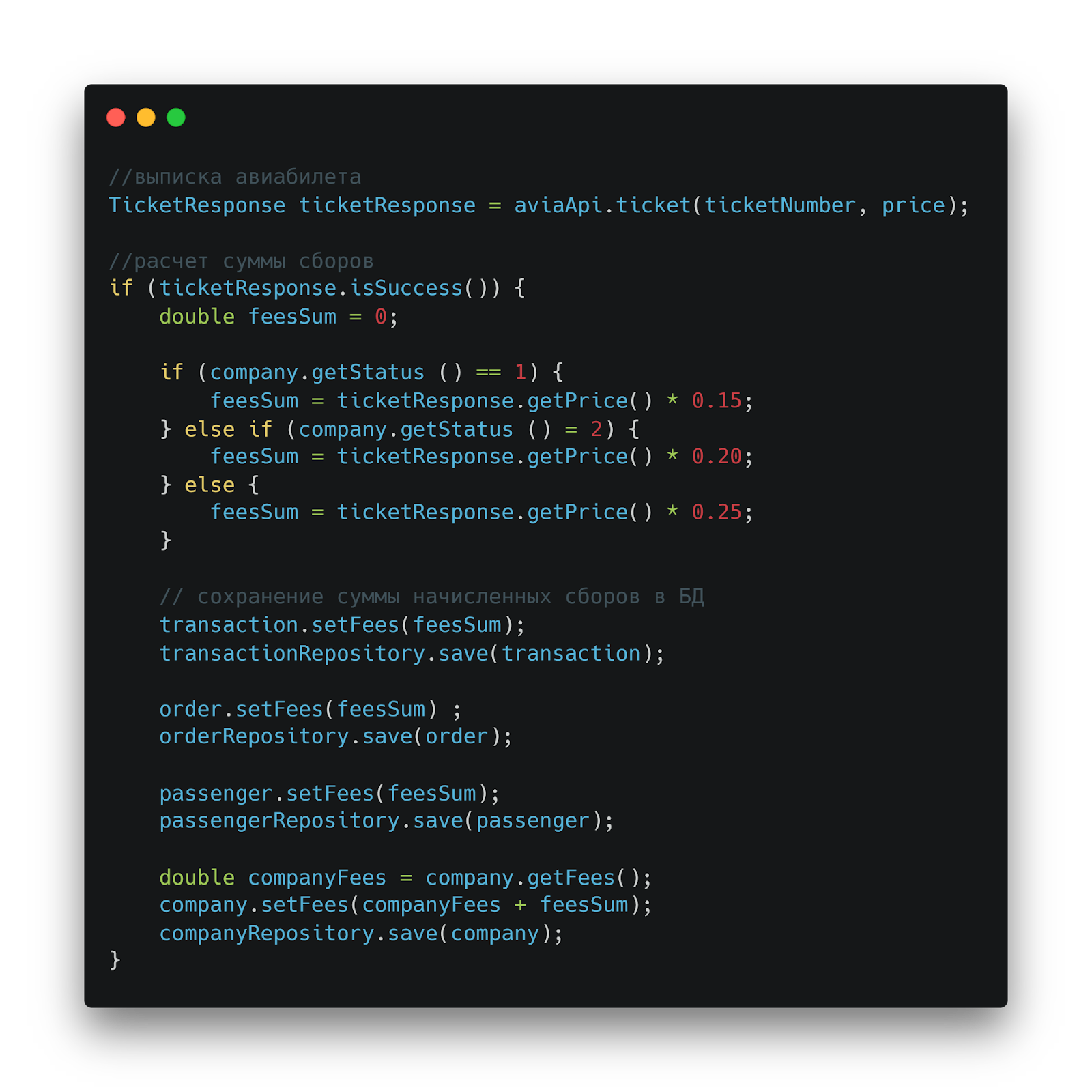
Старая реализация в авиасервисе
Для сравнения, вот как раньше выглядела логика в авиасервисе. Расчет сборов, сохранение в различные таблицы, обновление статусов — все в одном месте, без четкого разделения ответственности.
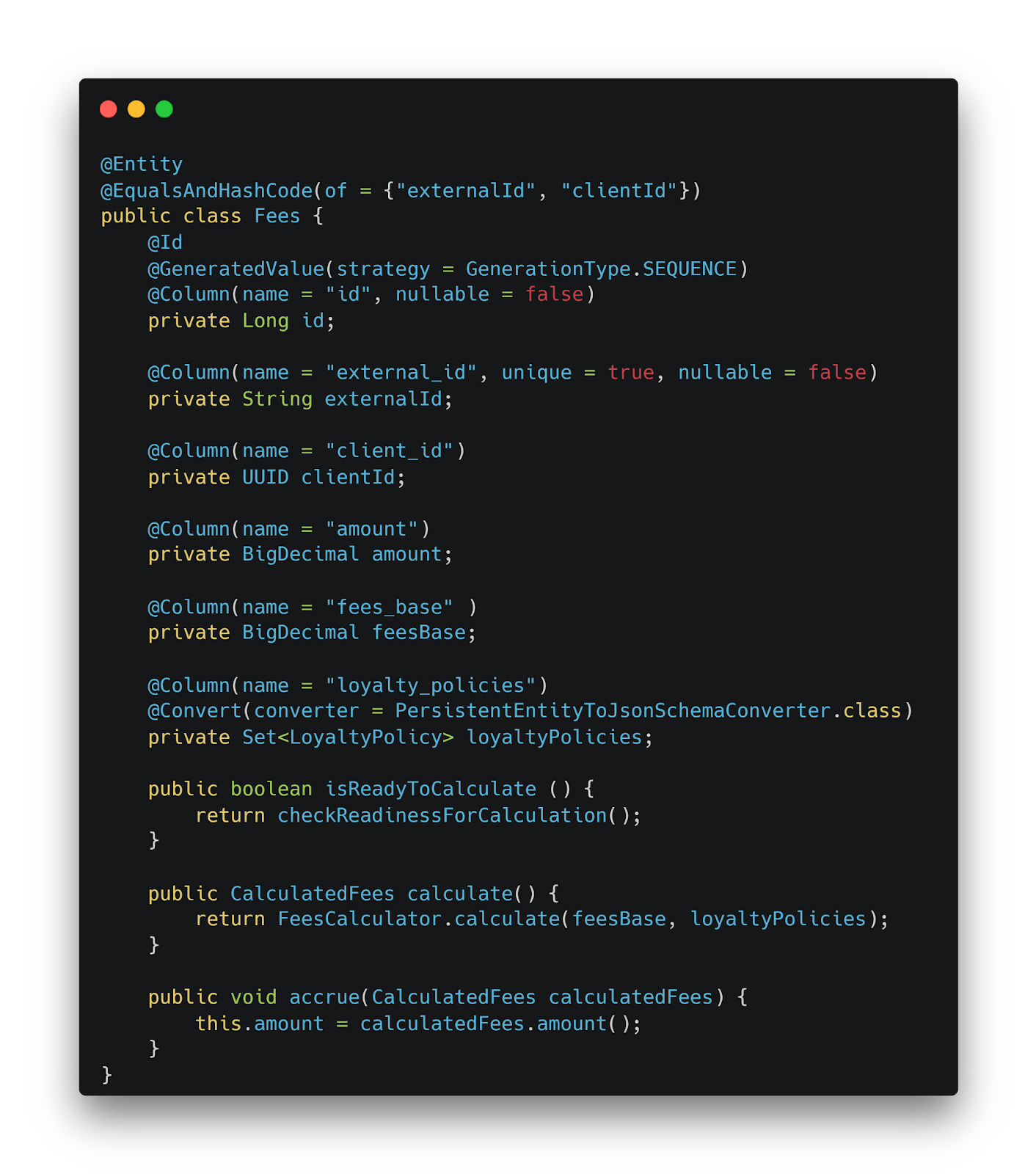
Новая модель Fees с инкапсулированной бизнес-логикой
В новой реализации вся бизнес-логика инкапсулирована в модели Fees. Методы isReadyToCalculate, calculate и accrue четко отражают бизнес-процессы. Модель самодостаточна и готова к дальнейшему развитию.
Особенно стоит отметить порядок проведения изменений: сначала мы переработали систему сервисных сборов, и только потом планируем приступать к обновлению программы лояльности. Этот подход позволил подготовить инфраструктуру для будущих изменений, не усложняя миграцию.
В результате мы не просто улучшили код — мы создали надежную основу для дальнейшего развития системы. История этого рефакторинга показывает: даже в сложных enterprise-системах возможно постепенное улучшение архитектуры без остановки развития функционала.
Куда двигаться дальше: эволюция защитного слоя
В процессе переработки системы Anti-Corruption Layer будет проходить через несколько стадий развития.
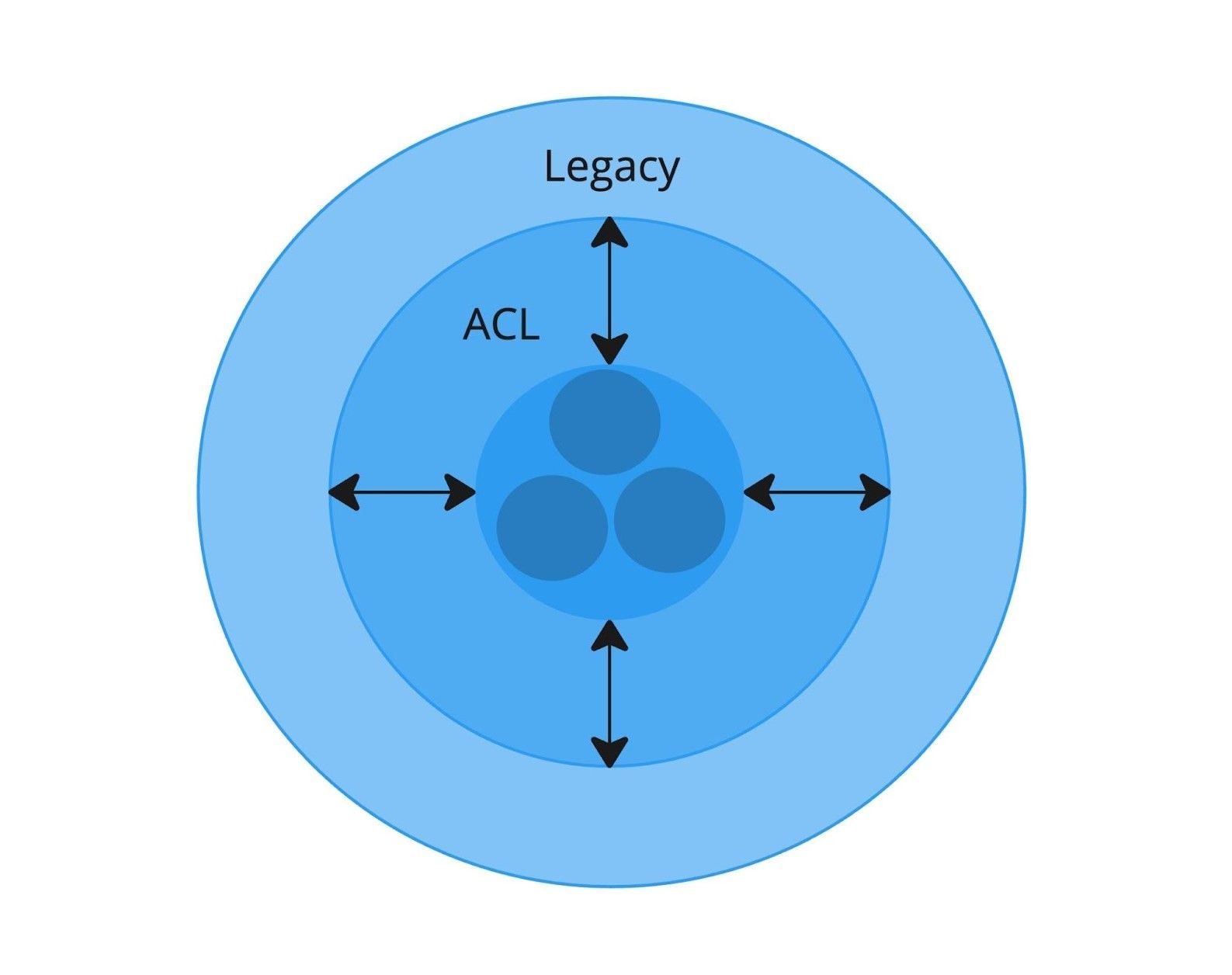
Начальный этап: небольшой ACL защищает первые выделенные компоненты
На первом этапе ACL появляется как тонкая прослойка между legacy-системой и первыми изолированными компонентами. Защитный слой пока небольшой, так как охватывает только базовый функционал, который начали переносить в новую архитектуру.
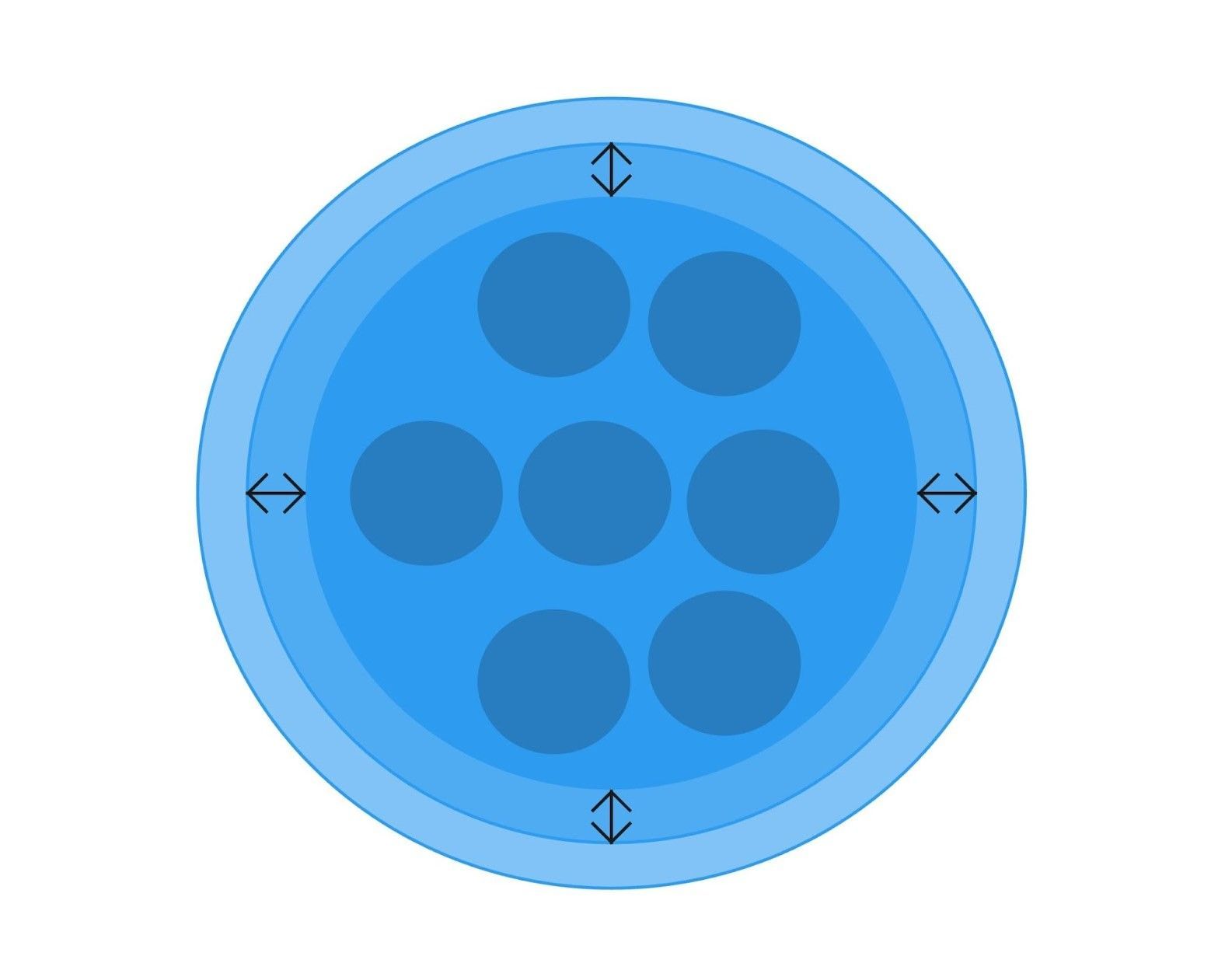
Этап роста: расширение ACL по мере выделения новых поддоменов
По мере того как выделяются новые поддомены и увеличивается площадь соприкосновения старой и новой частей системы, Anti-Corruption Layer естественным образом разрастается. На этом этапе он берет на себя больше ответственности по трансляции данных и синхронизации взаимодействий между компонентами.
Однако это временное разрастание. После прохождения определенной точки роста защитный слой начнет уменьшаться. Это произойдет потому, что новые компоненты системы научатся безопасно взаимодействовать друг с другом напрямую, без необходимости постоянной трансляции и проверки данных.
В финальной стадии возможны два сценария:
- ACL может полностью исчезнуть, если вся система будет переведена на новую архитектуру;
- Останется в виде тонкой прослойки для взаимодействия с внешними платформами (например, для интеграции с 1С или системами отчетности).
Такая эволюция защитного слоя — естественный процесс при грамотном рефакторинге. ACL выполняет роль строительных лесов: сначала помогает возвести новую архитектуру, а затем постепенно убирается там, где стал не нужен.
Монолит vs Микросервисы: с чего начать рефакторинг
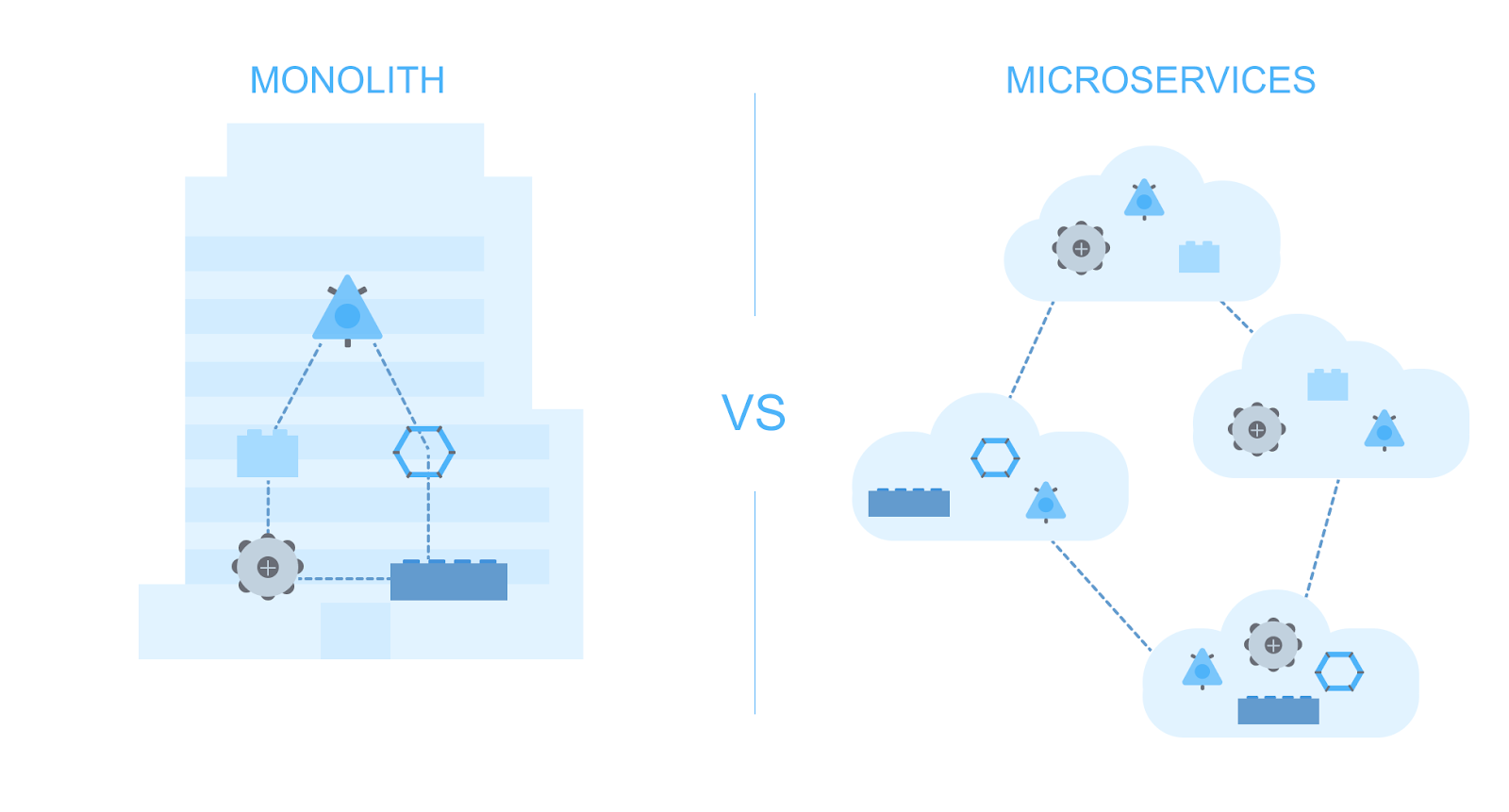
Монолитная vs микросервисная архитектура: разные подходы к организации системы

Разработка часто сталкивается с выбором между монолитной и микросервисной архитектурой. Особенно остро встает этот вопрос при рефакторинге legacy-систем. Казалось бы, микросервисы — это современно, гибко, масштабируемо. Почему бы сразу не пойти этим путем? Но опыт разработки показывает, что для новой системы или полного рефакторинга старой лучше начинать с монолита.
То же самое справедливо и для архитектуры приложения. Если есть проблемы в проектировании монолита, переход на микросервисы их не решит, а только усугубит. Неправильное распределение бизнес-процессов между сервисами может привести к катастрофическим последствиям. А ведь помимо этого существуют еще специфические проблемы микросервисной архитектуры: распределенные транзакции, сложности с согласованностью данных, проблемы сетевого взаимодействия.
С другой стороны, опыт грамотного проектирования монолитных систем дает глубокое понимание бизнес-процессов и их взаимосвязей. Со временем становится очевидно, какие части системы действительно просятся в отдельные сервисы, а какие лучше оставить в монолите. Такой естественный путь эволюции архитектуры гораздо надежнее, чем попытка сразу спроектировать идеальную микросервисную систему.
Заключение: от legacy к современной архитектуре
Работа с legacy-кодом часто воспринимается как неизбежное зло в enterprise-разработке. Но на самом деле это не только вызов, но и возможность качественно улучшить архитектуру системы. Применение принципов DDD при рефакторинге позволяет постепенно трансформировать запутанный legacy-код в чистую, поддерживаемую структуру.
Основные выводы из нашего опыта:
- Любую legacy-систему можно улучшить без полного переписывания. Подход с углубляющим рефакторингом позволяет постепенно выделять и очищать смысловое ядро, сохраняя при этом работоспособность системы;
- Anti-Corruption Layer выступает эффективным инструментом защиты нового кода. Этот паттерн не только изолирует новую логику от legacy-системы, но и обеспечивает плавный переход к современной архитектуре;
- Начинать рефакторинг лучше с монолита. Даже если конечной целью является микросервисная архитектура, понимание системы как единого целого поможет правильно определить границы будущих сервисов;
- Рефакторинг — это процесс постоянного обучения. Погружение в предметную область и регулярная коммуникация с бизнесом позволяют создавать архитектуру, которая действительно отражает бизнес-процессы.
В результате применения этих принципов мы не только улучшили качество кода, но и создали надежную основу для дальнейшего развития системы. История этого рефакторинга показывает: даже в сложных enterprise-системах возможно постепенное улучшение архитектуры без остановки развития функционала.
Этот опыт особенно ценен тем, что демонстрирует практическое применение DDD в реальном проекте. Мы увидели, как теоретические концепции воплощаются в конкретные технические решения, и как эти решения помогают справляться с реальными проблемами legacy-систем.
Главный урок, который можно извлечь из этого опыта — legacy-код это не приговор, а возможность для развития. При правильном подходе даже самая запутанная система может быть постепенно приведена к чистой и поддерживаемой архитектуре. И что особенно важно — это можно сделать без остановки развития бизнес-функционала.