
Создание SEO-краулера для отслеживания изменений на миллионах страниц — задача, где любая ошибка в архитектуре может привести к коллапсу системы. В этом кейсе мы расскажем, как команда столкнулась с проблемами масштабирования при обработке 20 миллионов записей в сутки и как решение на базе PostgreSQL стало ключом к стабильной работе и мгновенным отчетам.
Контекст задачи
К нам обратился Роман Ковалев, владелец SEO-агентства, автор популярного блога о поисковой оптимизации. Для своих клиентов он разрабатывал систему мониторинга сайтов.
Основная идея: существующие сервисы вроде Яндекс.Вебмастера замечают изменения на страницах только через четыре-пять дней. За это время конкуренты успевают занять освободившиеся позиции в выдаче, а технические проблемы превращаются в потерю трафика.
Нужен был инструмент, который сканирует сайты каждый день, собирает детальную статистику и моментально уведомляет об изменениях. Система должна обрабатывать миллион страниц в сутки, извлекая из каждой семнадцать различных метрик: все уровни заголовков, метаинформацию, данные о сертификатах, редиректах, кодах ответов.
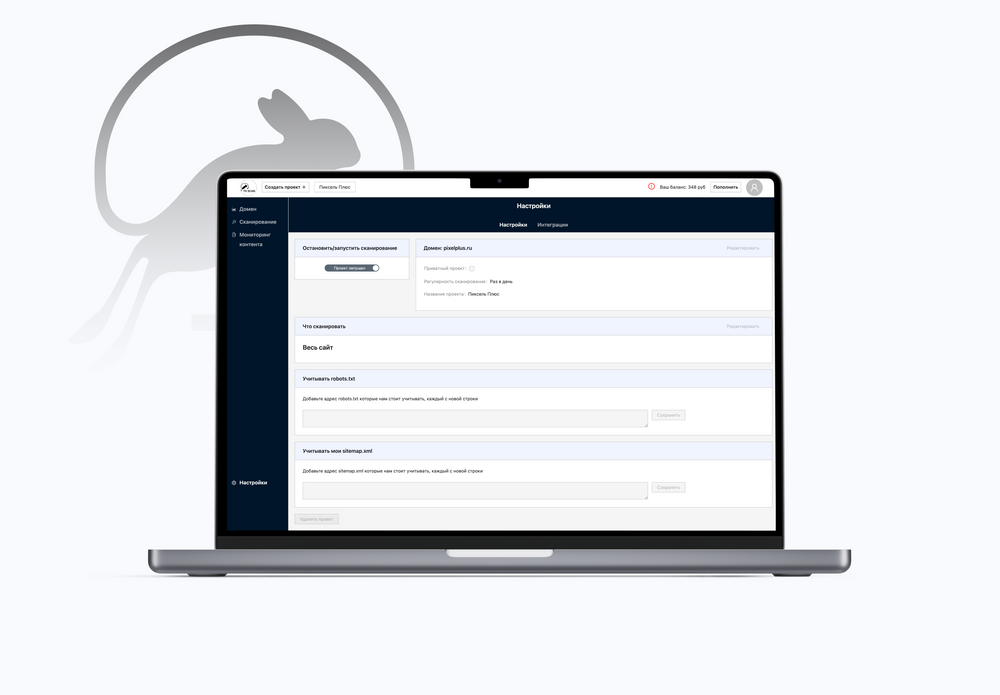
Дашборд домена: сводные метрики индексации и состояния сайта

Технологический фундамент выглядел так: Python с Django для основной логики, PostgreSQL для хранения, Redis с Celery для фоновых задач, React с TypeScript на фронтенде. Команда применяла современные подходы вроде Feature Sliced Design.
Запуск MVP и путь к промышленной версии
Работа началась осенью с проектирования архитектуры. Заказчик пришел не просто с идеей, а с готовыми интерактивными прототипами интерфейса. Это существенно упростило старт: за месяц фронтендер создал полноценный интерфейс с использованием UI-библиотеки AntDesign, который можно было показывать и обсуждать.
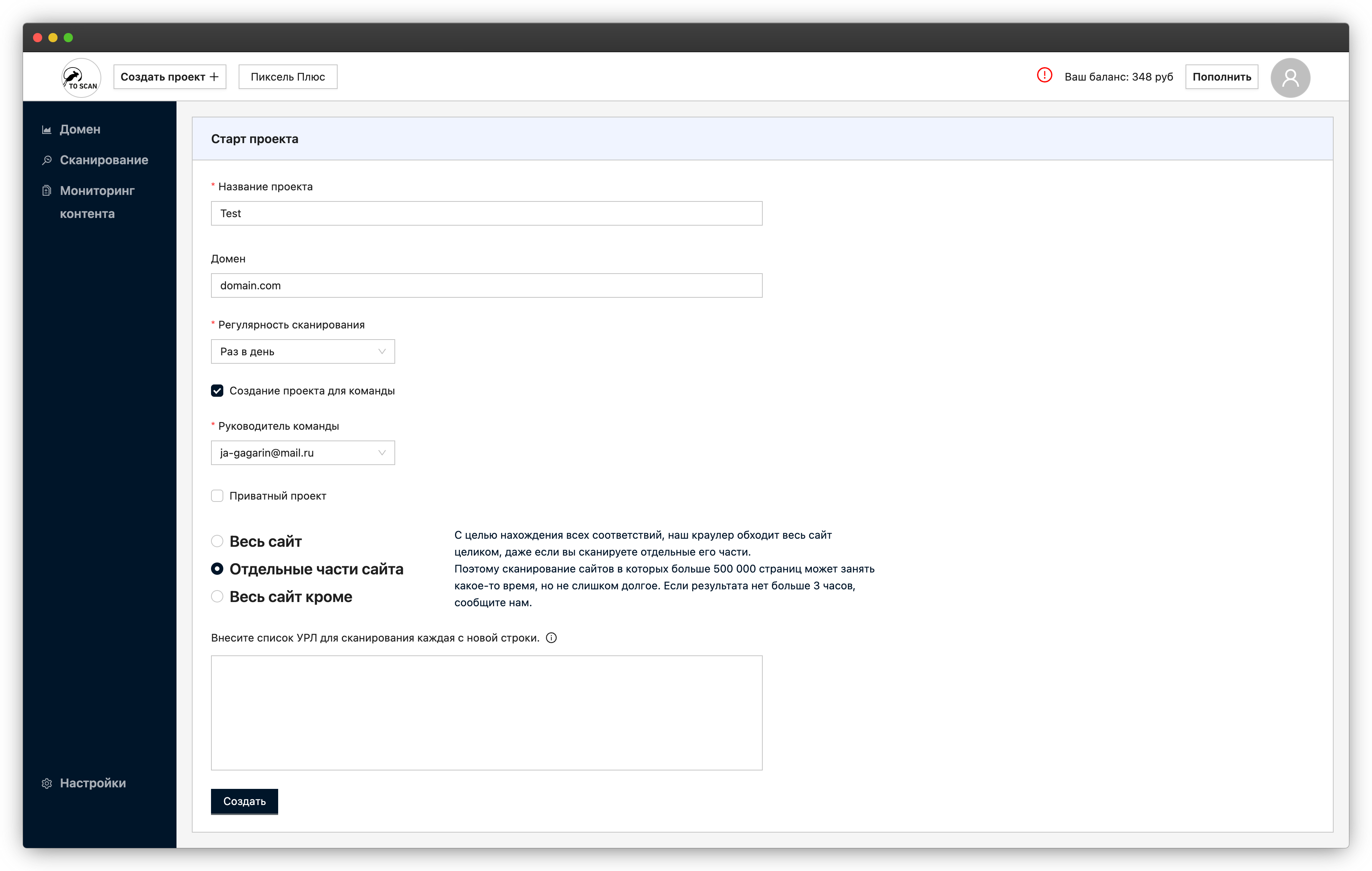
Форма настройки проекта и регулярности сканирования сайта
К зиме небольшая команда из двух разработчиков выпустила первую рабочую версию, которую начали тестировать на реальном пользователе — одном из крупнейших банков страны. Система сканировала сайты, сохраняла результаты, отправляла уведомления. Заказчик был доволен, но уже весной с подключением новых пользователей начались проблемы.
Технические вызовы и их решение

База данных PostgreSQL росла неконтролируемо. Каждое сканирование крупного портала добавляло десятки миллионов записей. Главная таблица превратилась в монстра с миллиардом строк. Простые запросы выполнялись минутами. Система начала деградировать на глазах.
Сайт банка определял робота и блокировал его после нескольких запросов. Пришлось срочно внедрять ротацию прокси-серверов. Но это породило новую проблему: ограниченный пул адресов нужно было использовать эффективно, не превышая лимиты.
Обнаружился парадокс с маленькими сайтами других пользователей. Краулер, настроенный на обработку гигантских порталов, фактически устраивал DDoS-атаку небольшим ресурсам. Владельцы жаловались, что их сайты падают во время сканирования.
Сервер начал испытывать проблемы с памятью. Процессы зависали посреди работы, данные терялись. Диск объемом 200 гигабайт забился под завязку, пришлось экстренно расширять до 400. Но главная боль касалась отчетов.
Система должна была после каждого сканирования сравнивать новые результаты с предыдущими, находить изменения, формировать детальный отчет. Этот процесс, который по задумке должен был занимать секунды, растягивался на восемь минут. PostgreSQL безуспешно пыталась найти совпадения среди шестидесяти миллионов записей за один проход.
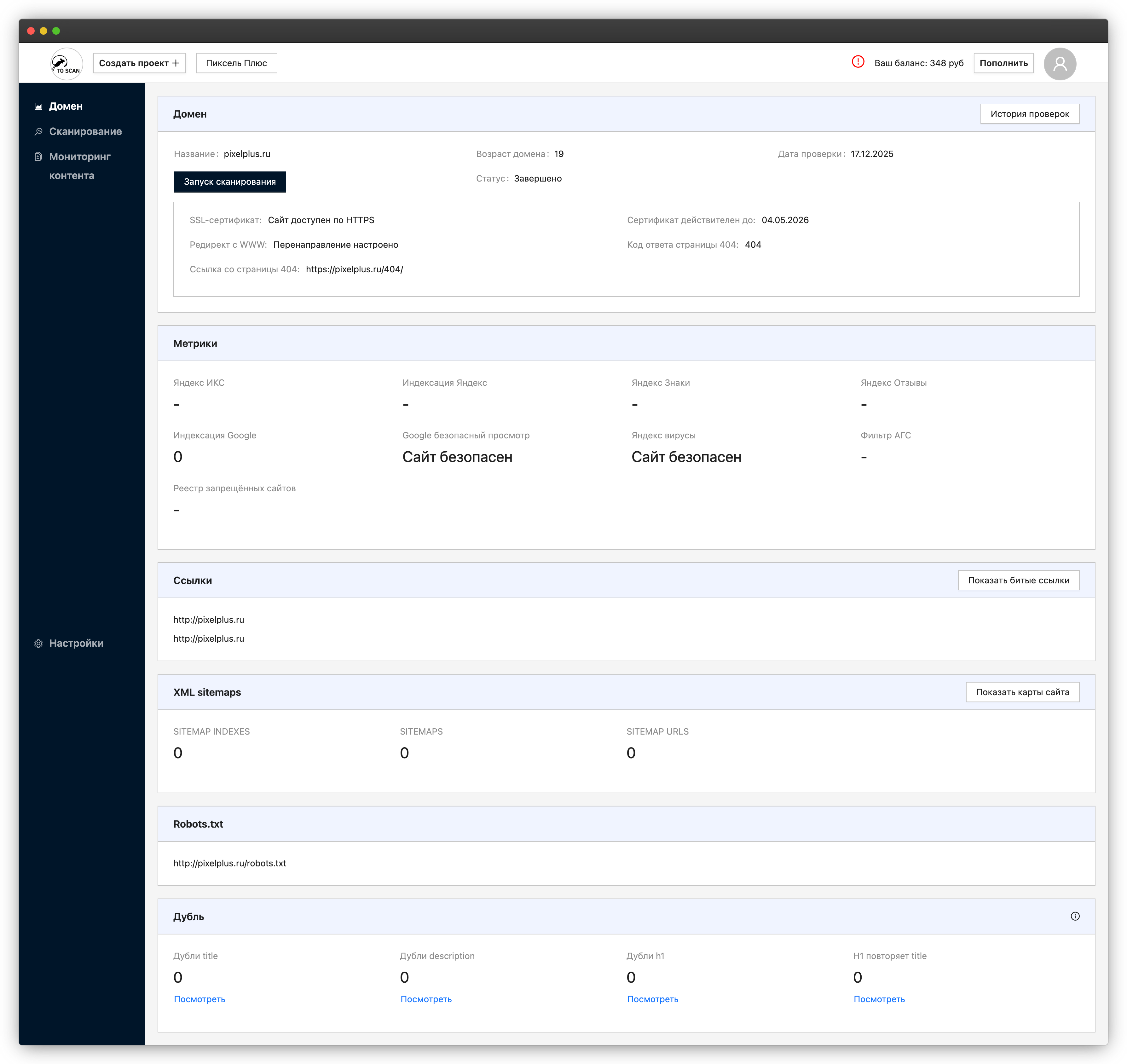
Раздел сканирования: список URL и параметры проверки страниц
Партиционирование таблиц в PostgreSQL: как это спасло проект
Проведя анализ всех проблем, решили что нужно перераспределить приоритеты и выделить ресурсы на оптимизацию баз данных PostgreSQL.

При первоначальном проектировании мы не могли предвидеть такой объем данных. Не было этапа системного анализа, фиксации нефункциональных требований к системе. В итоге PostgreSQL пытался просканировать миллиард записей при каждом запросе. Даже с правильными индексами это слишком медленно. Нужно было адаптировать архитектуру под реальные объемы.
Решение оказалось элегантным. Гигантскую таблицу разделили на ежедневные партиции. Теперь каждый день автоматически создавалась новая секция для данных. PostgreSQL стал умнее: получая запрос с датой, база сама определяла нужную партицию и работала только с ней. Вместо миллиарда записей сканировалось 20-60 миллионов.
За счет грамотного партиционирования и использования ключа партиции, PostgreSQL выполняет partition pruning. В результате чего запросы сканируют только нужные партиции, а не всю таблицу, что кратно ускоряет выборку на больших объемах данных.
Благодаря партиционированию и оптимизации PostgreSQL, время формирования отчёта сократилось с 8 минут до 15 секунд — в 32 раза быстрее. Параллельно была оптимизирована логика выявления изменений на страницах. Вместо сравнения полных текстов при каждом обходе система перешла к сравнению их хешей. Короткие хеш-суммы сравнивались молниеносно. Комбинация этих решений дала впечатляющий результат. Формирование отчета ускорилось с восьми минут до пятнадцати секунд.
Инженерные находки
Проект потребовал нескольких нестандартных технических решений. Для управления частотой запросов в PostgreSQL реализовали алгоритм Token Bucket. Многие считают, что алгоритмы в веб-разработке не нужны, но здесь без них было не обойтись. Система умно распределяла запросы между прокси-серверами, гарантируя, что с одного IP на один домен не уйдет больше разрешенного количества обращений в минуту.
Для ускорения работы с очередями задач написали хранимые процедуры на Lua, которые выполнялись прямо в памяти Redis. Это сократило количество обращений по сети и существенно ускорило обработку.
Разработали механизм динамической балансировки. Система анализировала размер сканируемого ресурса, а также автоматически подстраивала интенсивность обработки. Маленькие сайты обрабатывались деликатно, большие порталы на максимальной скорости.
Настройки проекта: выбор области сканирования, учёт robots.txt и sitemap.xml
Интеграции и монетизация сервиса
Проект требовал глубокой кастомизации стандартных компонентов. Вместо классической авторизации через email реализовали вход по номеру телефона с SMS-подтверждением через API одного из операторов связи.
Для монетизации сервиса подключили платежную систему. Реализовали полный цикл: генерацию ссылок для оплаты, обработку уведомлений о платежах, управление подписками. Отдельный блок настроек отвечает за интеграцию с Яндексом и Google для быстрой переиндексации измененных страниц.
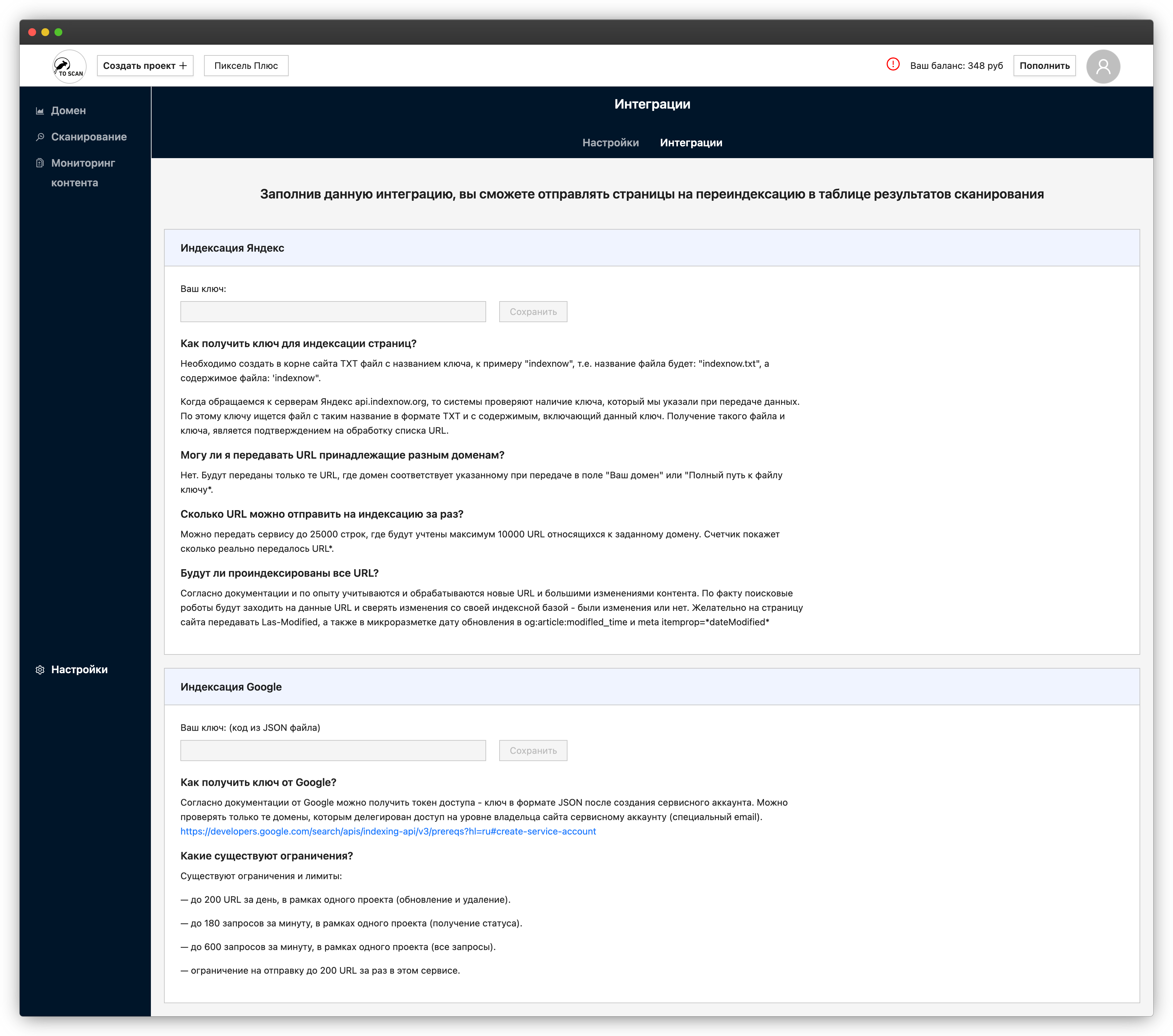
Экран интеграций: настройки отправки URL на переиндексацию в Яндекс и Google
Создали административную панель для управления проектами. Пользователи могли добавлять сайты для мониторинга, настраивать периодичность сканирования, выбирать отслеживаемые метрики, управлять каналами уведомлений.
Текущее положение
Заказчик открыл доступ внешним клиентам после стабилизации системы. Система работает в промышленном режиме. Ежедневно сканирует десятки проектов, обрабатывает миллионы страниц, отправляет сотни уведомлений. Критические проблемы производительности решены, хотя остаются точки для улучшения. Проект готов к дальнейшему развитию.
Уроки проекта: баланс между проектированием и запуском
Главный урок этого проекта касается баланса между детальным проектированием и быстрым запуском. На старте у нас было очень примерно составленные нефункциональные требования: миллион страниц в день, ежедневное сканирование, уведомления в реальном времени. Но не было детальной спецификации, описывающего все сценарии использования.
Мы столкнулись с противоречивыми задачами. Система должна была одновременно обрабатывать миллион страниц одного крупного банка и бережно сканировать множество небольших сайтов. Эти сценарии требуют разных подходов. Когда проектировали архитектуру, мы не знали всех особенностей будущего использования.
Здесь важно отметить профессионализм заказчика. При возникновении проблем, на эмоциях часто хочется критиковать исполнителей, что они что-то не учли. Но в реальности, при разработке индивидуальных систем важен быстрый запуск, а также обратная связь от реальных пользователей. Вместе с заказчиком мы анализировали причины и искали решения. Заказчик видел промежуточные результаты, понимал сложность задач и давал время на их решение.
Как можно было минимизировать проблемы?

Можно потратить месяцы на аналитику, проектирование и сделать отказоустойчивую масштабируемую систему «на вырост», которая окажется не востребована рынком.
Мы выбрали другой путь. Мы изначально понимали, что момент «разделения» большого объема данных рано или поздно наступит, если система будет решать свою задачу и ей будут активно пользоваться. Поэтому сосредоточились на быстром запуске MVP, который бы сканировал только сайты банка. Получили реальные данные о поведении системы, столкнулись с проблемами и решили их, чтобы можно было запускать новых пользователей. Сложность никуда не делась, просто переместилась с этапа проектирования на этап оптимизации.
Итог
В разработке сложных систем всегда есть выбор: потратить много времени на анализ в начале или быстро запустить и дорабатывать по ходу. Оба подхода имеют право на жизнь. Важно найти правильный баланс для конкретного проекта.
История этого проекта показывает: успех зависит не только от технических решений, но и от взаимопонимания между заказчиком и исполнителем. Когда обе стороны готовы к диалогу и совместному поиску решений, даже самые сложные технические вызовы становятся преодолимыми.
Хотите внедрить кастомный SEO-краулер или оптимизировать существующую систему для больших объёмов данных? Оставьте заявку или напишите нам — поможем решить любые задачи масштабирования и автоматизации SEO.


