

Strapi предоставляет гибкий функционал фильтрации из коробки, но настройка полноценного поиска по данным — нетривиальная задача и таит в себе множество подводных камней. Рассмотрим три способа реализации поиска на примере корпоративного блога. После прочтения статьи сможете определить, какой инструмент подойдет вам для поставленной задачи.
Далее все примеры будут представлены для strapi v3, но вся информация также актуальна и для v4, отличие только в деталях реализации.
Встроенные возможности поиска в strapi

Сначала разберем встроенные возможности поиска. Для этих целей Strapi предоставляет метод query, который позволяет формировать в том числе запросы со сложными условиями фильтрации. Интерфейс запроса выглядит так:

Здесь param — это название свойства, а filter — одно из ключевых значений для сравнения. Все доступные фильтры есть в документации.
Метод query также поддерживает AND и OR операторы. Операция AND поддерживается неявно, для этого достаточно передать массив с необходимыми условиями:

Для поддержки операции OR предусмотрено ключевое слово _or:

Пример реализации
Напоминаем, что задача — добавить функционал поиска статей в корпоративный блог. Строим условия поиска на полях: автор, заголовок, текст анонса.

Кроме поиска на странице также присутствует фильтрация по категориям. Это не вызовет никаких сложностей. Разработчики Strapi продумали подобные сценарии использования.
Опустим добавление поисковой строки на страницу и приступим сразу к описанию параметров запроса. Как отмечалось ранее, параметры фильтрации поддерживают операторы OR в виде _or - свойства. Оператор AND поддерживается скрыто в виде обычного массива. Согласно поставленной задаче, возможно выделить три условия поиска:
- в заголовке находится поисковая подстрока AND, категория статьи пересекается с выбранным фильтром;
- в тексте анонса располагается поисковая подстрока AND, категория статьи пересекается с выбранным фильтром;
- в имени или фамилии автора есть поисковая подстрока AND, категория статьи пересекается с выбранным фильтром.
Опишем параметры запроса, которые удовлетворяют нашим условиям:
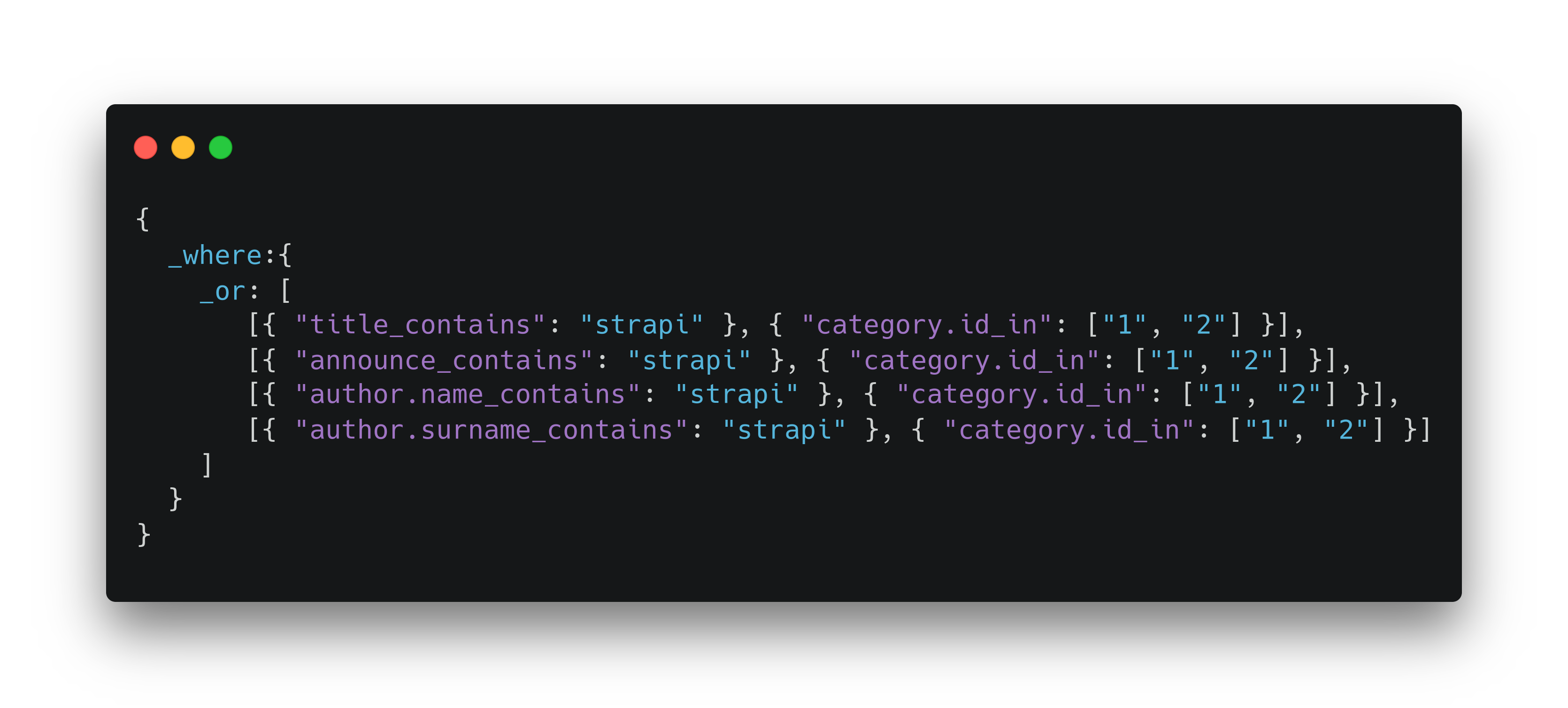
Обратите внимание на то, что интерфейс запроса позволяет получать в том числе вложенные свойства, например, name и surname у объекта author.
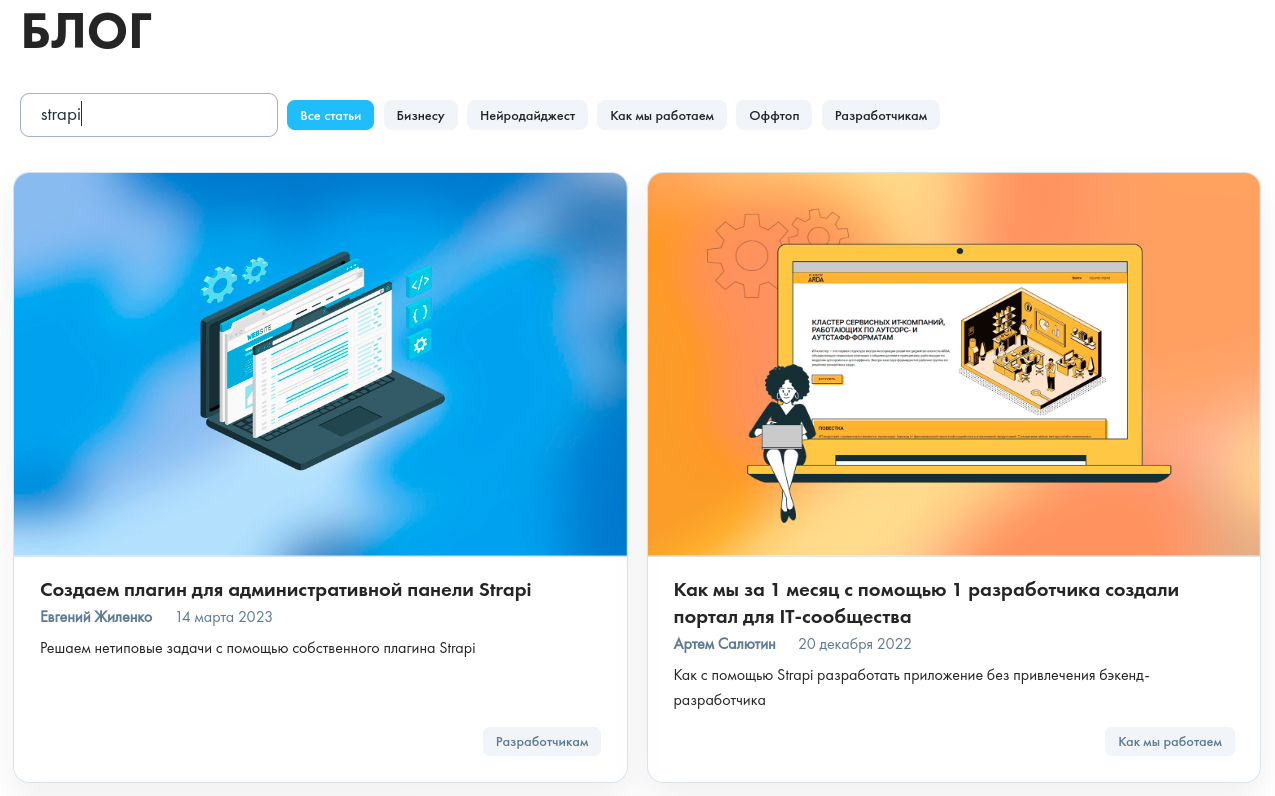
Ниже представлен результат выполнения поиска по значению “strapi”.
Достоинства и недостатки
Плюсы:
- не нужно подключать сторонние решения;
- простой и задокументированный интерфейс, поддержка базовых операций;
- возможность комбинировать условия;
- не требует доработок на беке.
Минусы:
- нет встроенных возможностей постобработки найденных значений(например, выделения совпадений);
- нет обработки ошибок при вводе поискового значения;
- строгое сравнение поискового значения;
- нужно описывать каждый запрос, который умеет работать с поиском;
- нет возможности поиска одновременно по нескольким контент-типам (разве что добавлять собственный эндпоинт на беке);
- значение для поиска должно присутствовать в таком же виде, как и в свойстве для поиска. Не получится указать «vue react» и получить все статьи с Vue и React в одном из искомых свойств.

Альтернативы. Meilisearch
Meilisearch — это open-source поисковой сервис. Быстрый, кроссплатформенный, написан на Rust. Имеет официальный плагин для интеграции со Strapi. Совместим как со Strapi v3, так и со Strapi v4. Ключевая особенность — высокая степень настройки из коробки, что обеспечивает низкий порог входа.
Подробнее про установку и настройку сервиса читайте в официальной документации тут для v3, а тут для v4. Описывать указанные процессы в статье не будем, рассмотрим только настройки поискового движка.
Возможности
- Поиск по коллекции;
- Поиск по нескольким коллекциям вместе;
- Кастомизация критериев релевантности сущностей запросу;
- Предобработка сущностей перед индексацией;
- Постобработка сущностей перед выдачей результатов;
- Автоматическая реиндексация при модификации коллекций;
- Возможность точечной фильтрации поисковых результатов на стороне клиента;

- Интеграция с UI-библиотекой InstantSearch под Vanilla JS, React, Vue и Angular;
- Использование синонимов при поиске;
- Исправление ошибок в поисковом значении;
- Фасетный поиск;
- Географический поиск.
Ограничения
- При поиске учитываются только первые 10 слов-токенов поискового запроса: этим ограничением достигается высокая скорость поиска;
- Одновременно обрабатывает не больше 1024 запросов;
- Отсутствует возможность использования в виде распределенной системы;
- Не подойдет для работы с BigData;
- Отсутствуют инструменты комплексного анализа данных.
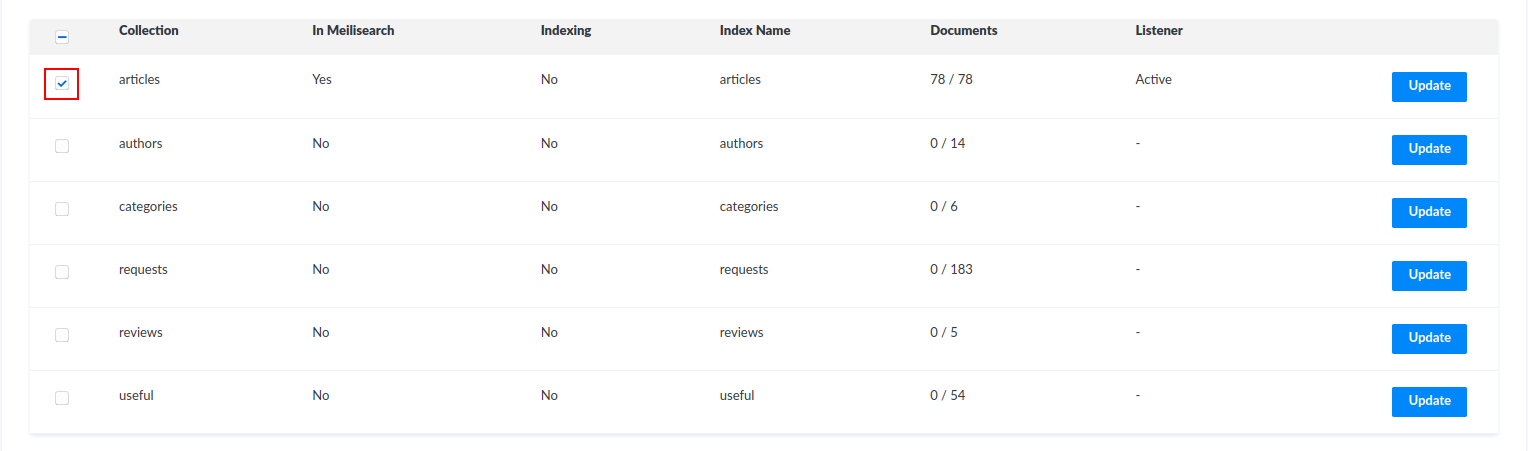
Индексация коллекции
Чтобы сервис meilisearch смог осуществлять поиск по коллекциям strapi, их необходимо проиндексировать, для этого достаточно в админ панели strapi выбрать необходимую коллекцию из таблицы на странице плагина meilisearch.
По умолчанию, название проиндексированной коллекции совпадает с изначальным названием, но его можно изменить. Например, коллекция статей блогов называется “articles”, но если хотим переименовать проиндексированную коллекцию в “blog”, то в /api/articles/models/articles.js в экспортируемый объект прописываем:
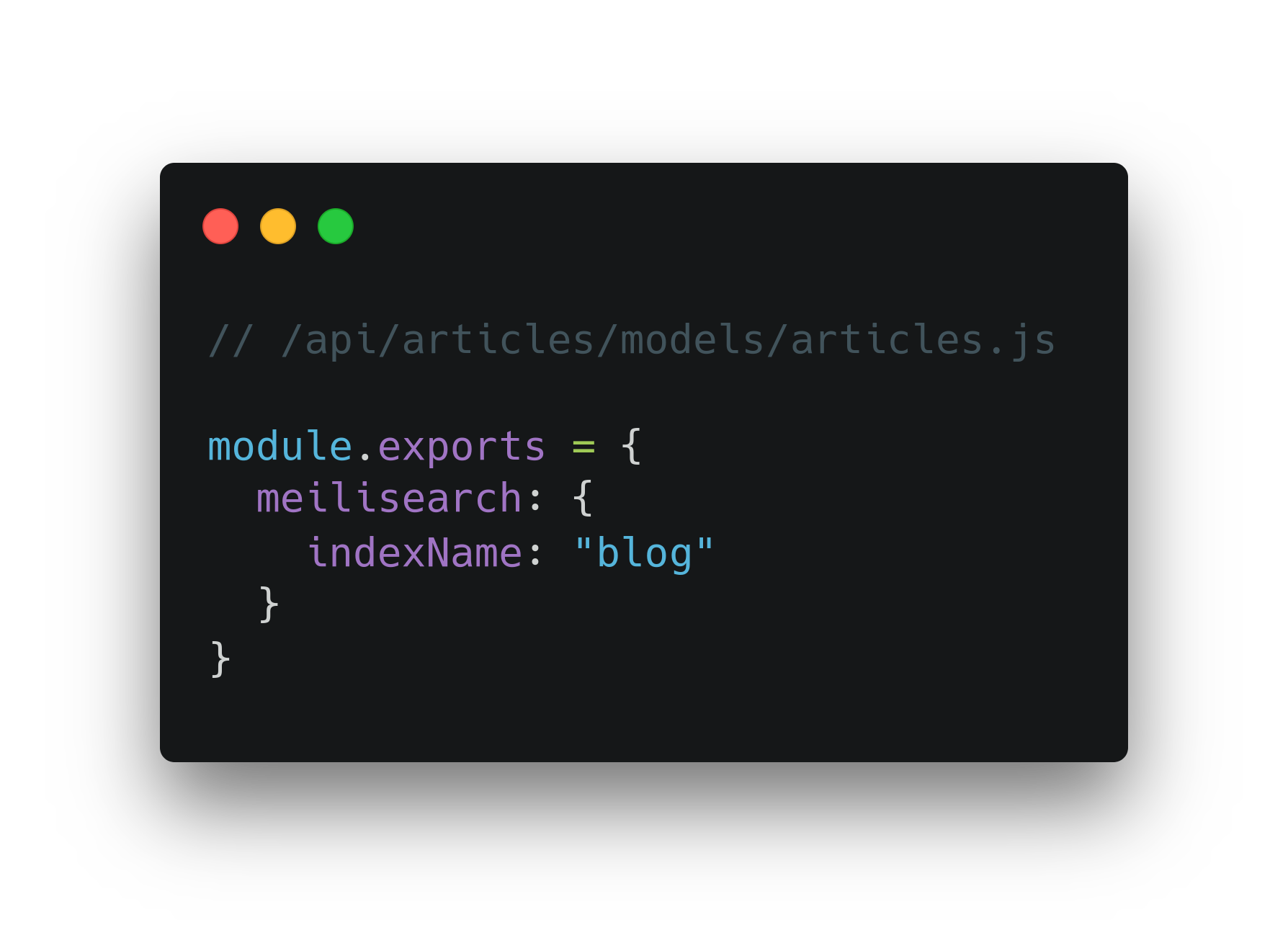
Переименование индекса может быть полезно, если собираемся объединить несколько коллекций в одну поисковую группу.
Предобработка сущностей
По умолчанию Meilisearch ищет совпадения слов по всем полям: публичным и приватным. Кастомизировать объект сущности для индексации можно в /api/COLLECTION/models/COLLECTION.js. Логика кастомизации описывается в методе transformEntry. Например, чтобы удалить из объектов все приватные поля, можно использовать встроенную функцию strapi – sanitizeEntity.
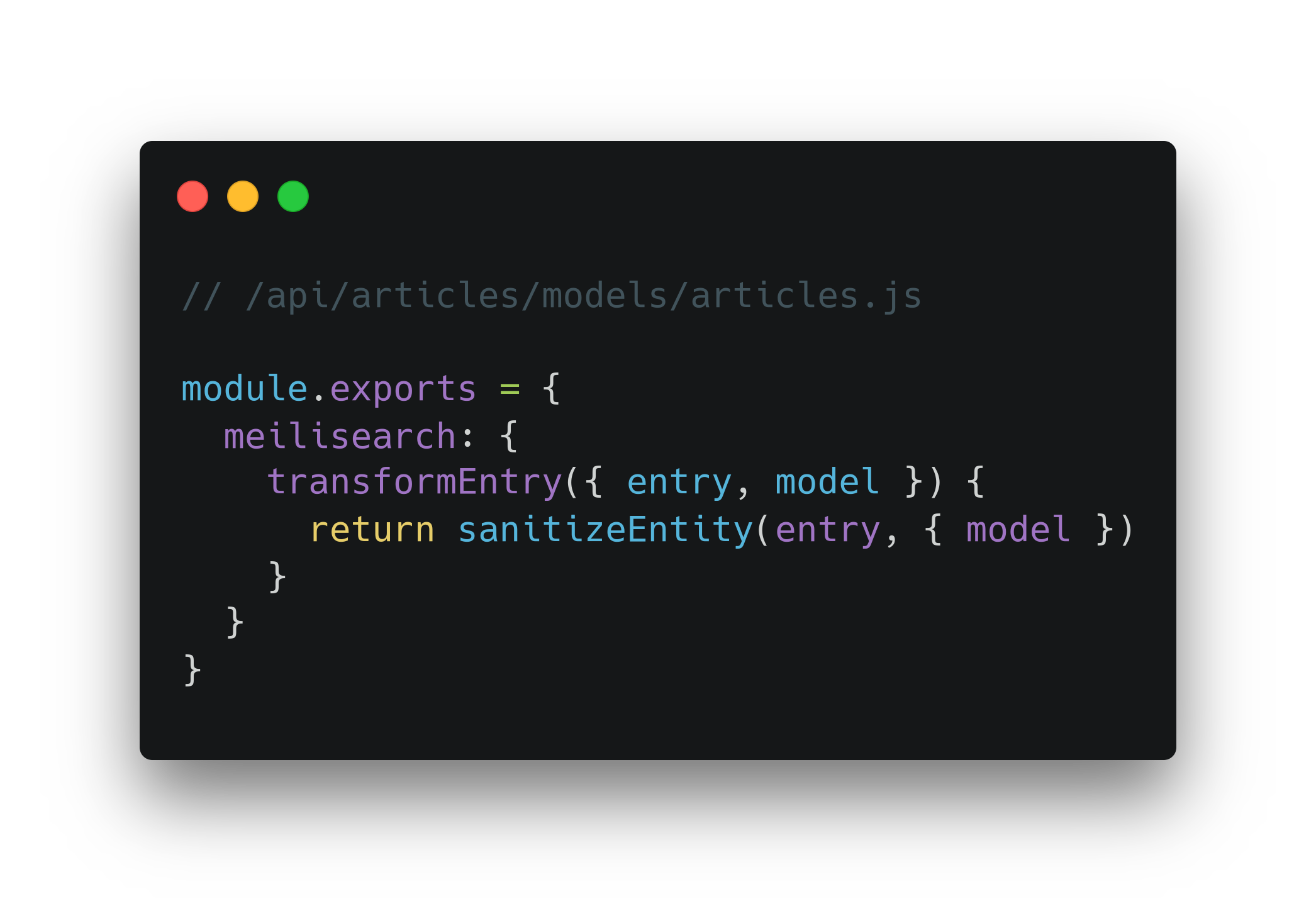
Кастомизация поиска
После того как проиндексировали необходимую коллекцию, а также скрыли внутренние свойства сущностей от поисковой машины, настраиваем сам процесс поиска. Можно осуществлять данные процессы в том же файле /api/COLLECTION/models/COLLECTION.js.
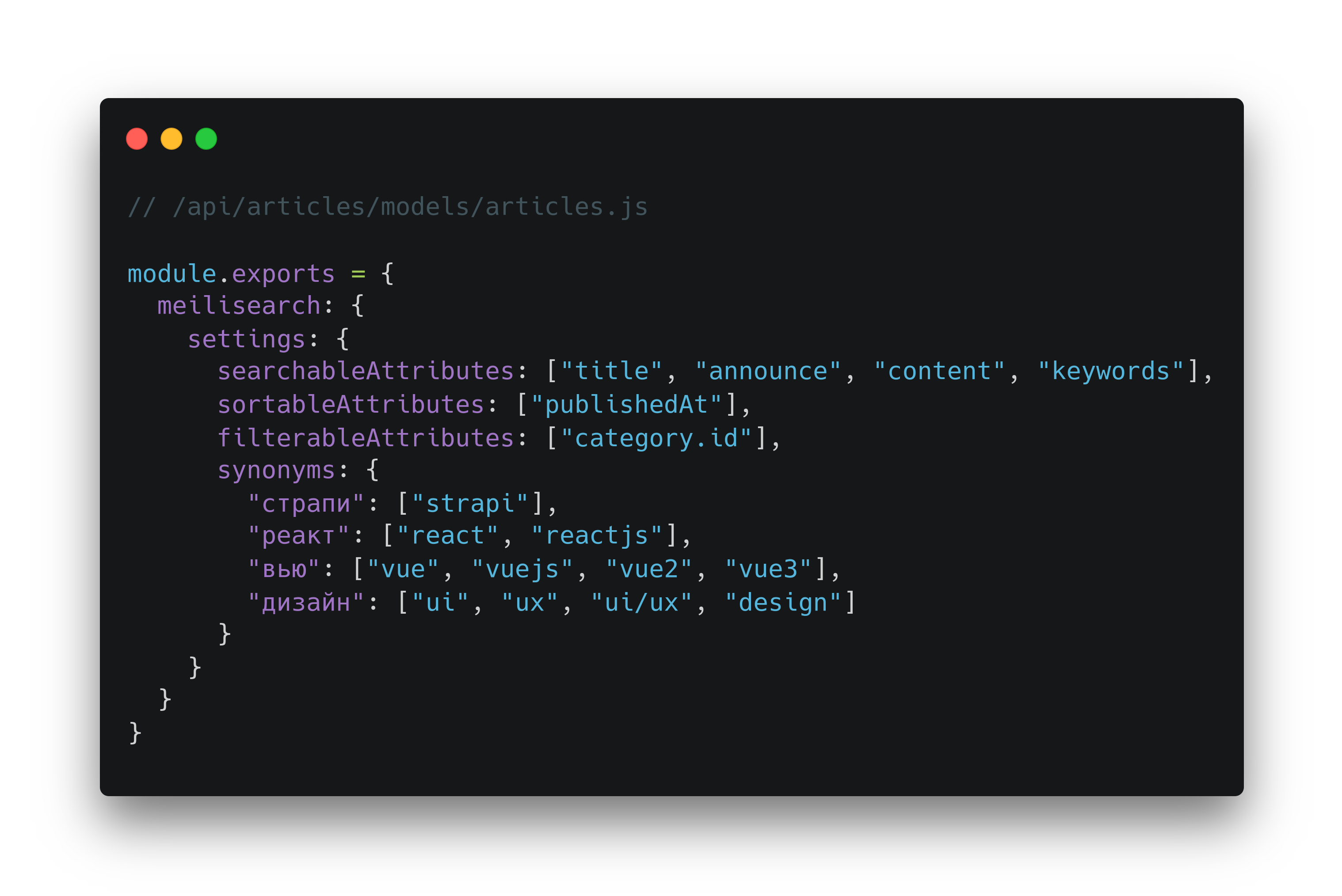
Перед тем как приступить к настройке поиска, ознакомимся с ключевыми свойствами:
- searchableAttributes — массив полей сущности, по которым будет осуществляться поиск в порядке уменьшения значимости. По умолчанию, порядок соответствует порядку полей в сущности;
- synonyms — объект, где ключ — слово из поискового запроса, а значение — массив синонимов для этого ключа;
- stopWords — массив значений, который не будет читаться из поискового запроса (по умолчанию — пустой);
- typoTolerance — объект правил обработки опечаток. В нем задаются поля:
- enabled — по умолчанию опечатки распознаются;
- minWordSizeForTypos.oneTypo— по умолчанию исправление одной опечатки происходит в словах с минимум 5-ю буквами;
- minWordSizeForTypos.twoTypos — по умолчанию исправление двух опечаток происходит в словах с минимум 9-ю буквами;
- disableOnWords — массив, нечувствительный к регистру, в котором опечатки распознаваться не должны;
- disableOnAttributes — массив полей, в словах которых опечатки распознаваться не должны.
- rankingRules — массив критериев релевантности сущностей к запросу в порядке уменьшения значимости. По умолчанию следующие правила-строки в таком порядке:
- words — количество встречающихся слов из запроса (чем больше, тем релевантнее);
- typo— количество опечаток (чем меньше, тем релевантнее);
- proximity — расстояние между совпадающими условиями запроса (например, если запрос “react vue”, то документ с подстрокой “react vue” выдастся раньше, чем со строкой “react и vue”);
- attribute — учитывать приоритеты атрибутов, заданных в поле searchableAttributes;
- sort — учитывать правила сортировки, определяемые при запросе на стороне клиента;
- exactness — если пользователь ввел «совет», то документ со словом «совет» выдастся раньше, чем документ с «советы».
- displayedAttributes — поля, которые останутся в ответе на запрос (по умолчанию все).
Выше указаны основные свойства настройки. Полный список с примерами и подробным описанием можно посмотреть в документации.
Важные моменты:
- релевантные сущности сортируются методом блочной сортировки;
- количество опечаток равно расстоянию Левенштейна.
Настройка конфигурации может выглядеть так:
Интеграция с клиентом
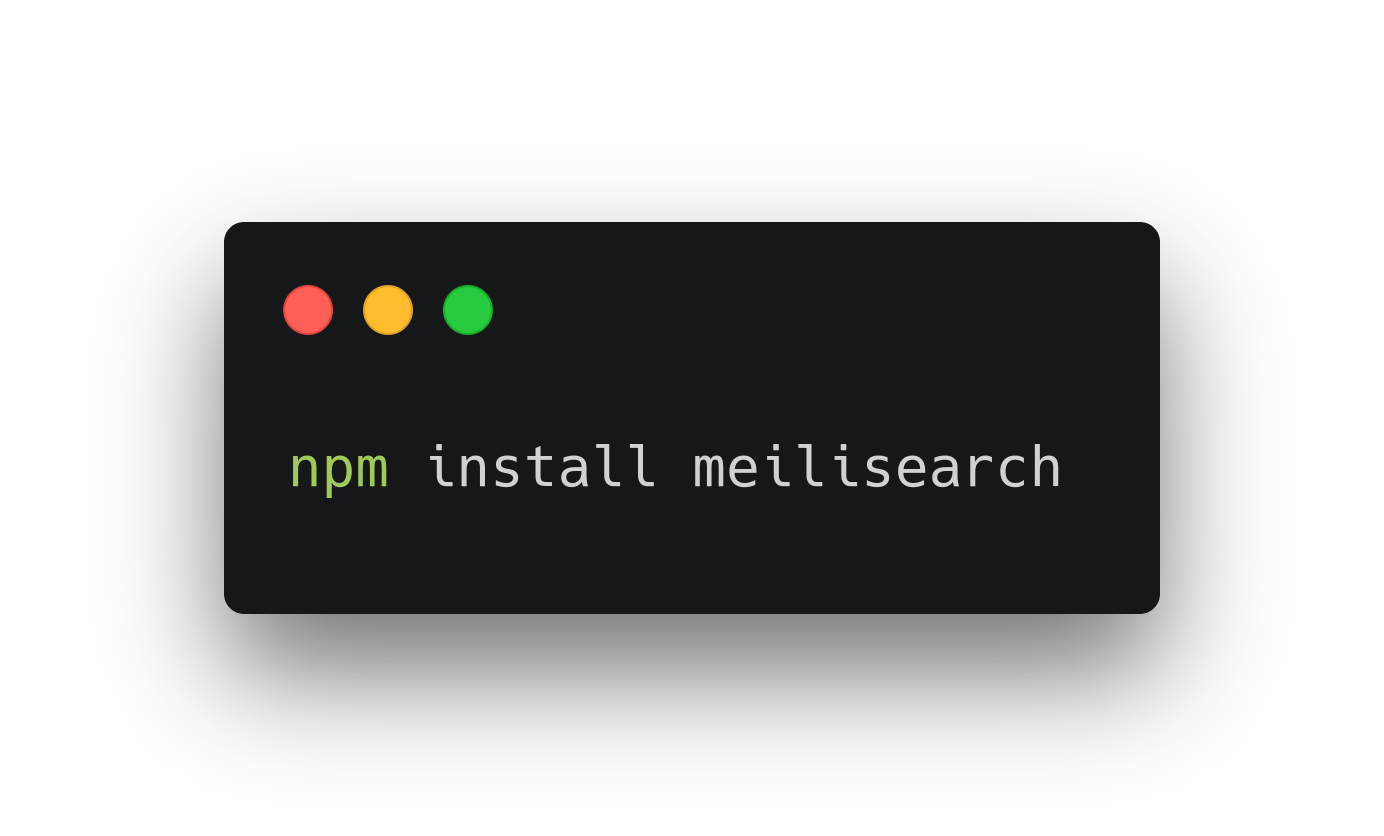
Для интеграции с клиентским приложением meilisearch предоставляет одноименный npm-пакет, который можно установить командой:
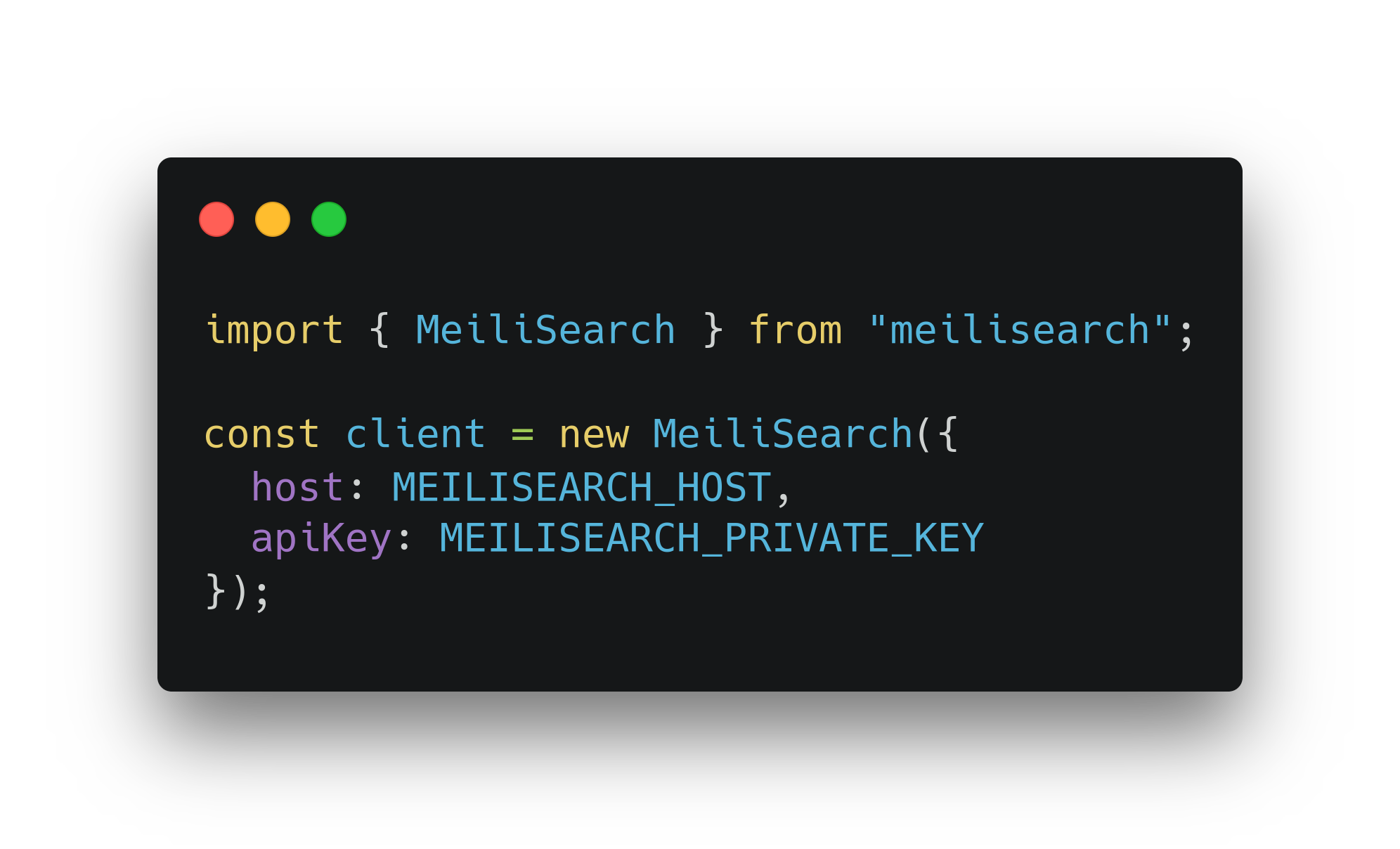
Перед тем как отправлять запросы к поисковому сервису, необходимо инициализировать клиента. Для удобства значения host и apiKey выносим в переменные окружения:
После того как клиент проинициализирован, у нас появляется возможность взаимодействовать с поисковым сервисом. Следующим шагом является выбор коллекции для дальнейшей работы, в нашем случае это “articles”.

После выбора коллекции становятся доступны методы для взаимодействия с ней. Воспользуемся методом search, чтобы построить поисковой запрос. Первым аргументом метод принимает значение для поиска, а вторым необязательный объект с параметрами. Подробнее про параметры можно прочитать в документации.
Запрос на поиск статей по значению “strapi” с выделением совпадений и сортировкой по дате публикации может выглядеть так:
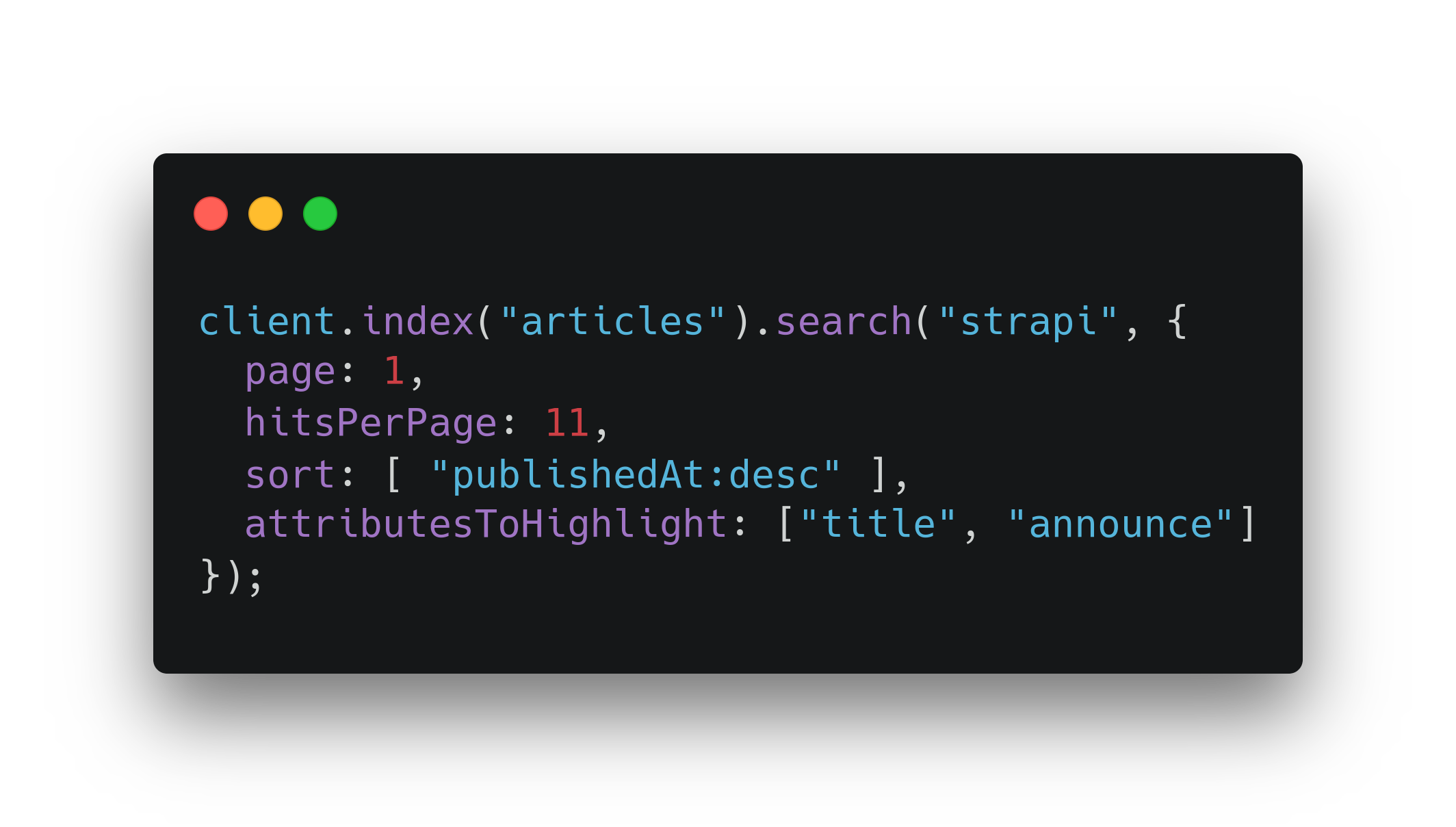
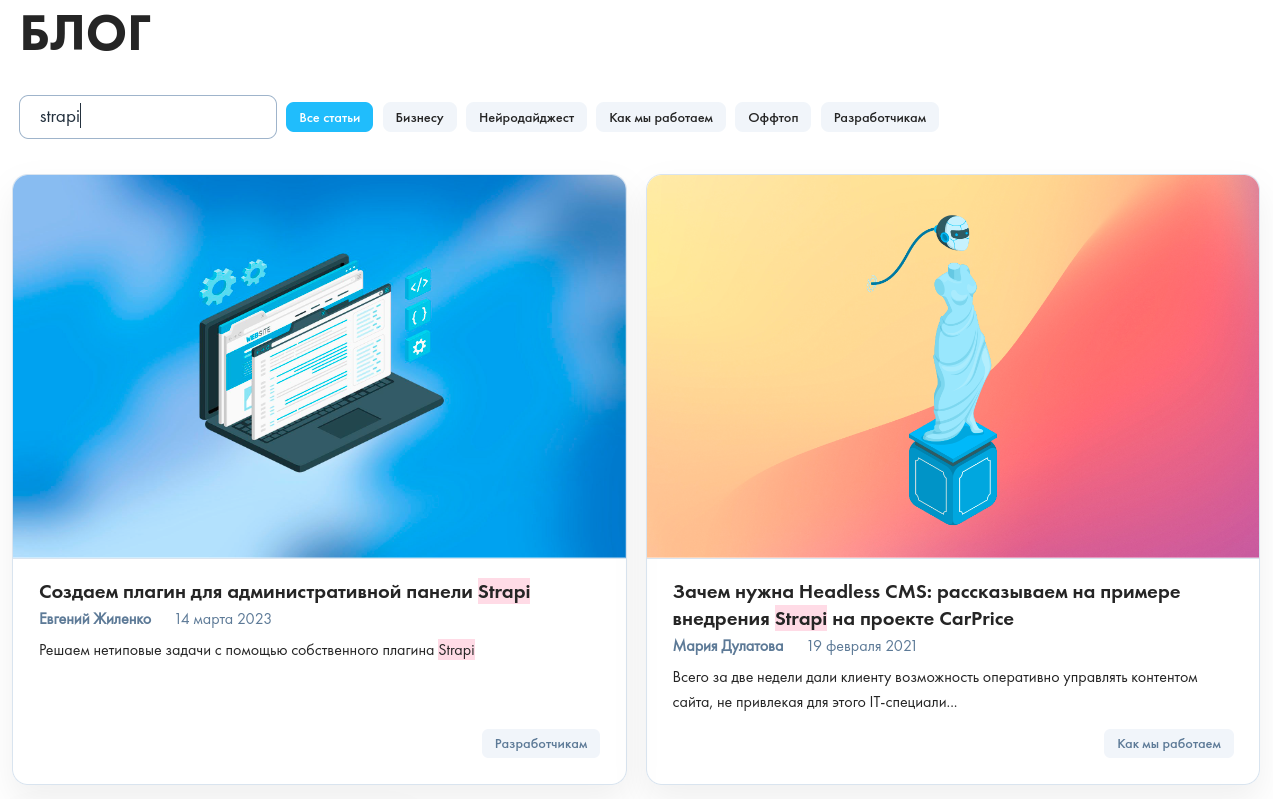
В итоге получаем функционал поиска с автоматическим выделением совпадений в каждой карточке статьи:
Альтернативы. Elasticsearch
Под Elasticsearch подразумеваем ELK стек — Elasticsearch + Logstash + Kibana. Все инструменты из этого стека имеют открытый исходный код.

Elasticsearch — движок для поиска и анализа данных, написанный на Java. Он обладает высокой скоростью работы даже с большими объемами данных.
Logstash — сервис, который принимает и обрабатывает данные, после чего отправляет их в базу ES. Данный сервис имеет множество плагинов из коробки, а также поддерживает кастомные.
Kibana — веб-интерфейс для визуализации и анализа данных. Среди встроенных возможностей выделим: функции агрегирования, фильтрации, интерактивные диаграммы.
ELK стек — это гибкий и функциональный инструмент. Позволяет решать практически любые поисковые и аналитические задачи над данными. Но обратной его стороной является сложность в настройке и разработке, что в свою очередь повышает порог входа.
Возможности
- Простое горизонтальное масштабирование путем добавления новых серверов. При этом Elasticsearch предоставляет автоматическое распределение нагрузки между узлами;
- Высокая надежность — при сбоях в кластерных узлах, данные будут перераспределены, что позволит их не потерять. Каждое изменение данных в хранилище логируется сразу на нескольких узлах кластера;
- Гибкие поисковые фильтры. Возможность работы с синонимами, восточными языками, нечетким поиском и т.д.;
- Веб-интерфейс для взаимодействия с сервисом;
- Инструменты анализа и визуализации данных;
- Универсальность — нет жесткого ограничения в источнике данных, с которыми работает сервис. Logstash умеет работать с разными источниками данных: СУБД, файлы, системные логи и др.
Ограничения
- Не поддерживает клиентов из России;
- Требовательность к ресурсам процессора и оперативной памяти из-за использования JVM;
- Сложный внутренний язык запросов;
- Отсутствие встроенной системы авторизации и ограничения прав доступа;
Интеграция сервиса в Strapi
В этой статье не будем описывать настройку и разворот сервиса elasticsearch, подробнее про разворот можно прочитать в документации. Дальнейшие действия подразумевают наличие доступа к развернутому сервису.
Есть несколько способов для интеграции сервиса elasticsearch и последующей индексации данных . В данной статье разберем наиболее простой из них. Пример более продвинутой реализации можно посмотреть здесь.
Перед тем как проиндексировать коллекцию, необходимо подготовить вспомогательные скрипты.
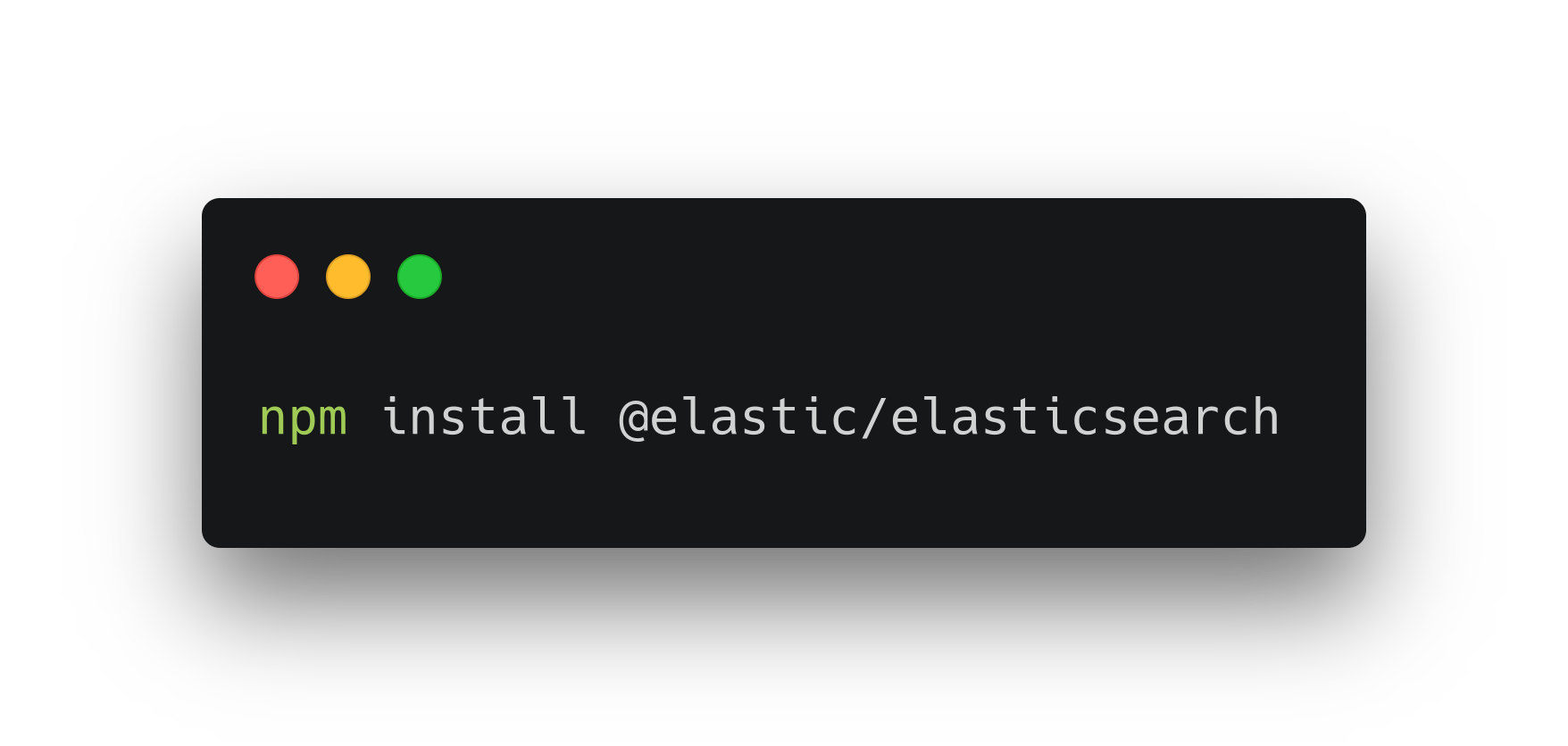
Для начала установим зависимости:
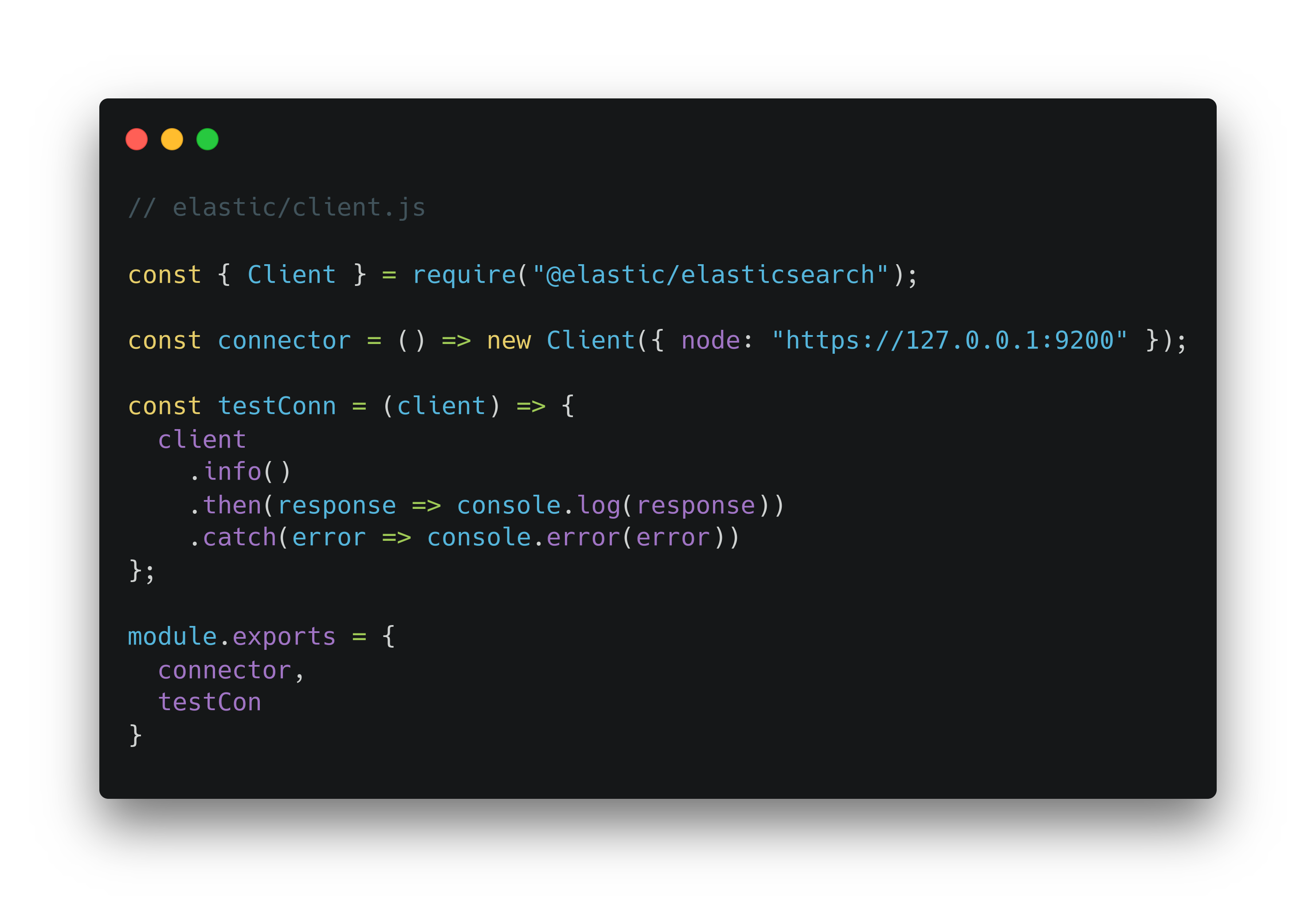
Далее нужно написать функции для подключения к сервису и проверки состояния соединения. Для этого создадим файл client.js в директории elastic и поместим внутрь содержимое:
Индексация
Необходимые вспомогательные утилиты готовы. Теперь можно написать скрипт, который проиндексирует коллекцию статей. Создадим файл index.js в директории elastic и вставим в него код:
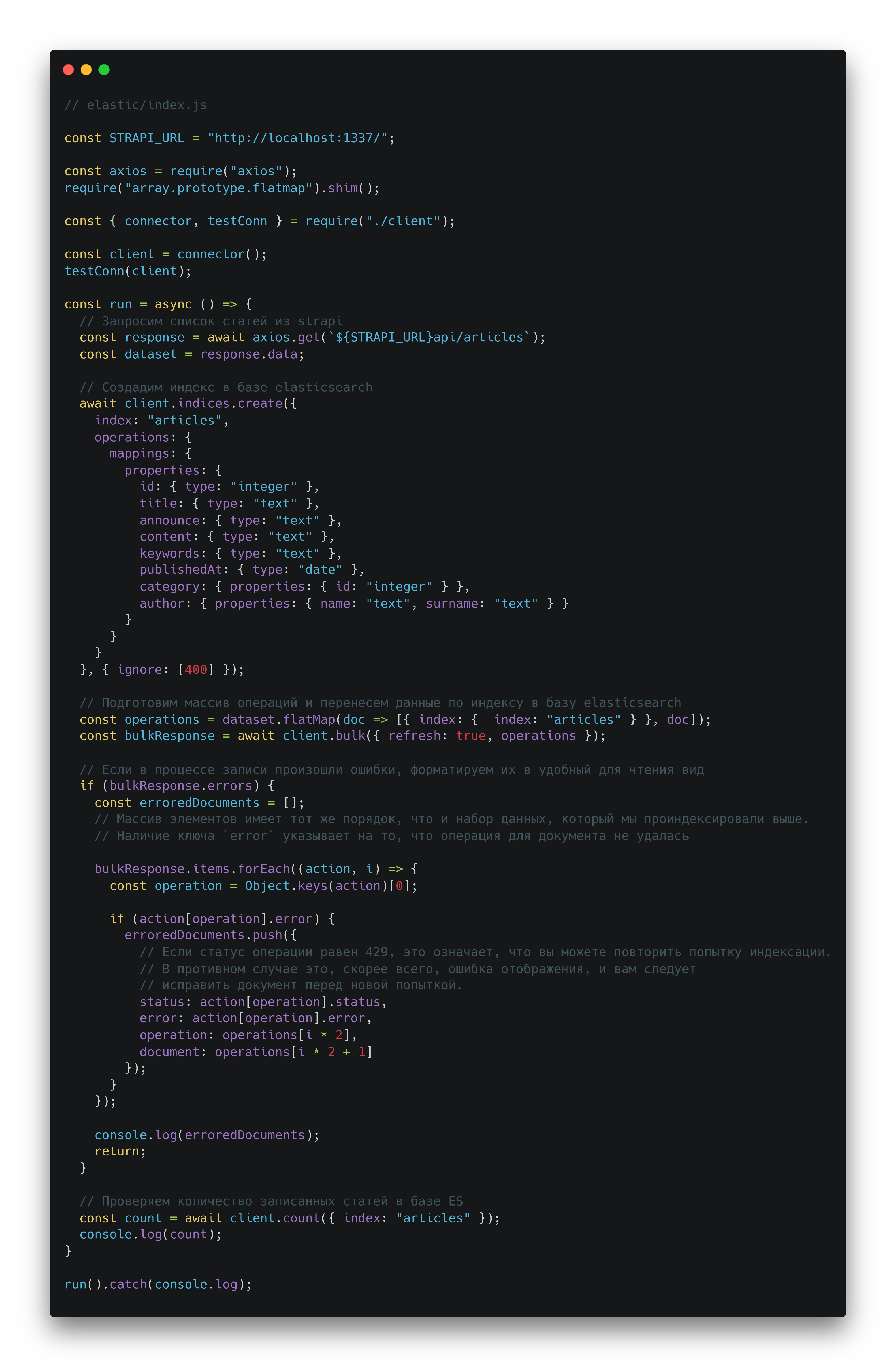
В коде, описанном выше, запрашиваем список статей из базы strapi, после чего создаем индекс и вставляем данные по этому индексу. Если возникнут ошибки в этом процессе, форматируем и выводим их в консоль.
Для работы скрипта необходимо установить пакет array.prototype.flatmap, для этого выполним команду:
После того как скрипт для индексации данных готов, зависимости установлены, необходимо запустить сервер Strapi. В процессе индексации скрипт будет запрашивать список статей из нашего сервера.
Теперь можно запустить скрипт из файла elastic/index.js. Для этого выполним команду:

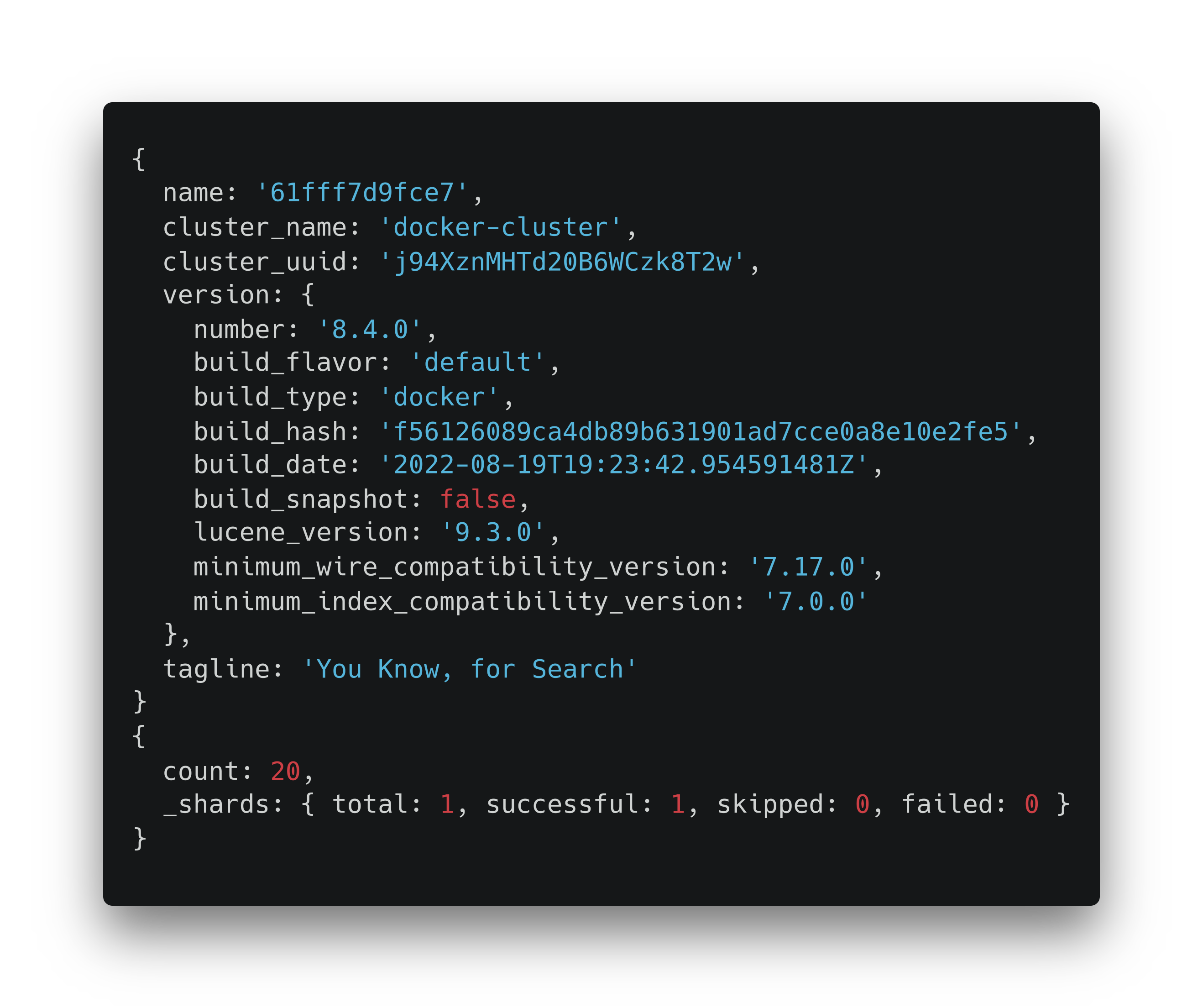
Если индексация пройдет успешно, увидим сообщение:
Создание API
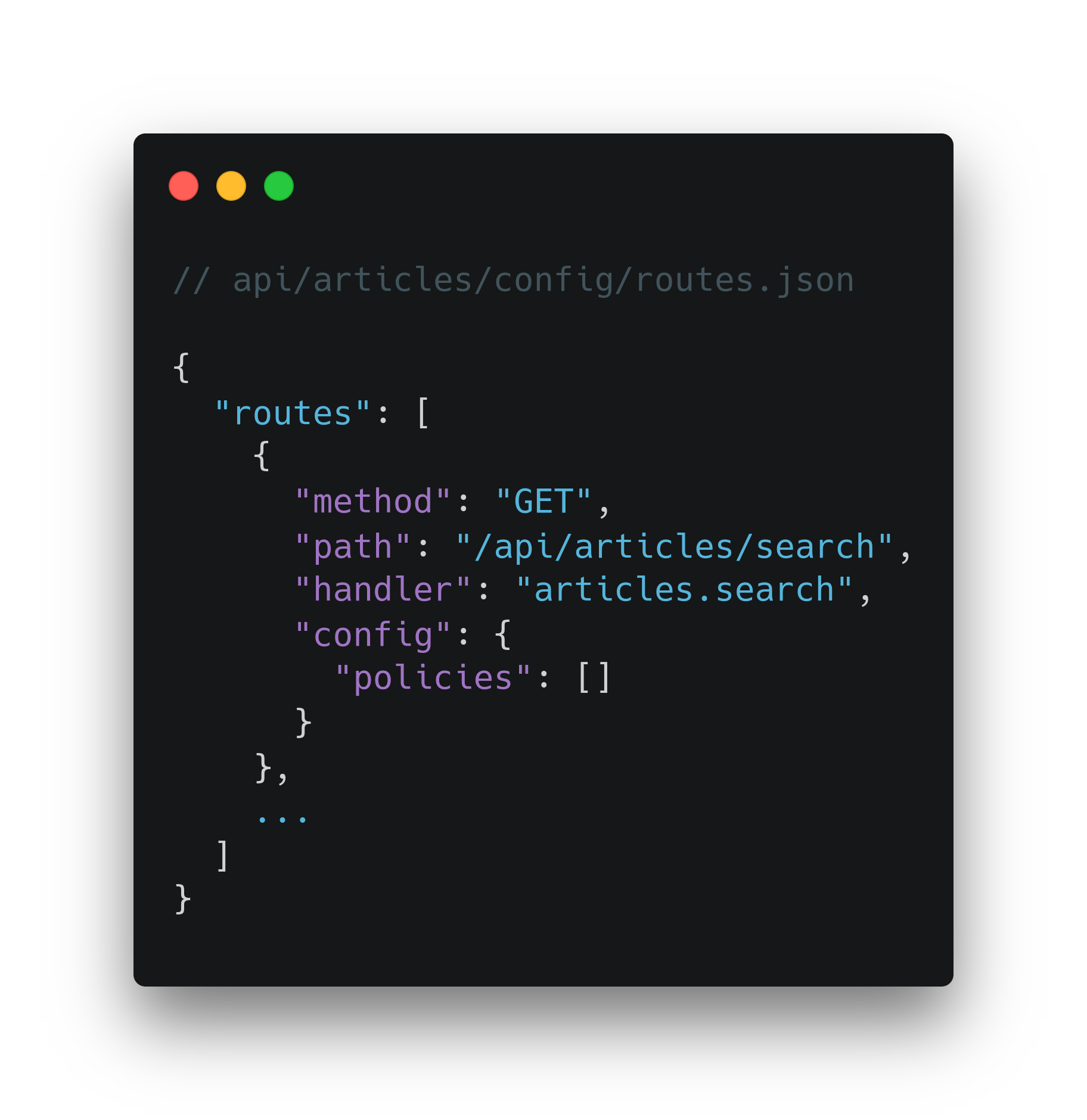
Планируем скрыть обращение к elasticsearch за контрольной точкой strapi-сервера. Для этого необходимо добавить роут в конфигурацию.
Расширим файл config/routes.json кодом:
Далее необходимо добавить контроллер для обработки запроса. Для этого расширим содержимое файла controllers/articles.js:
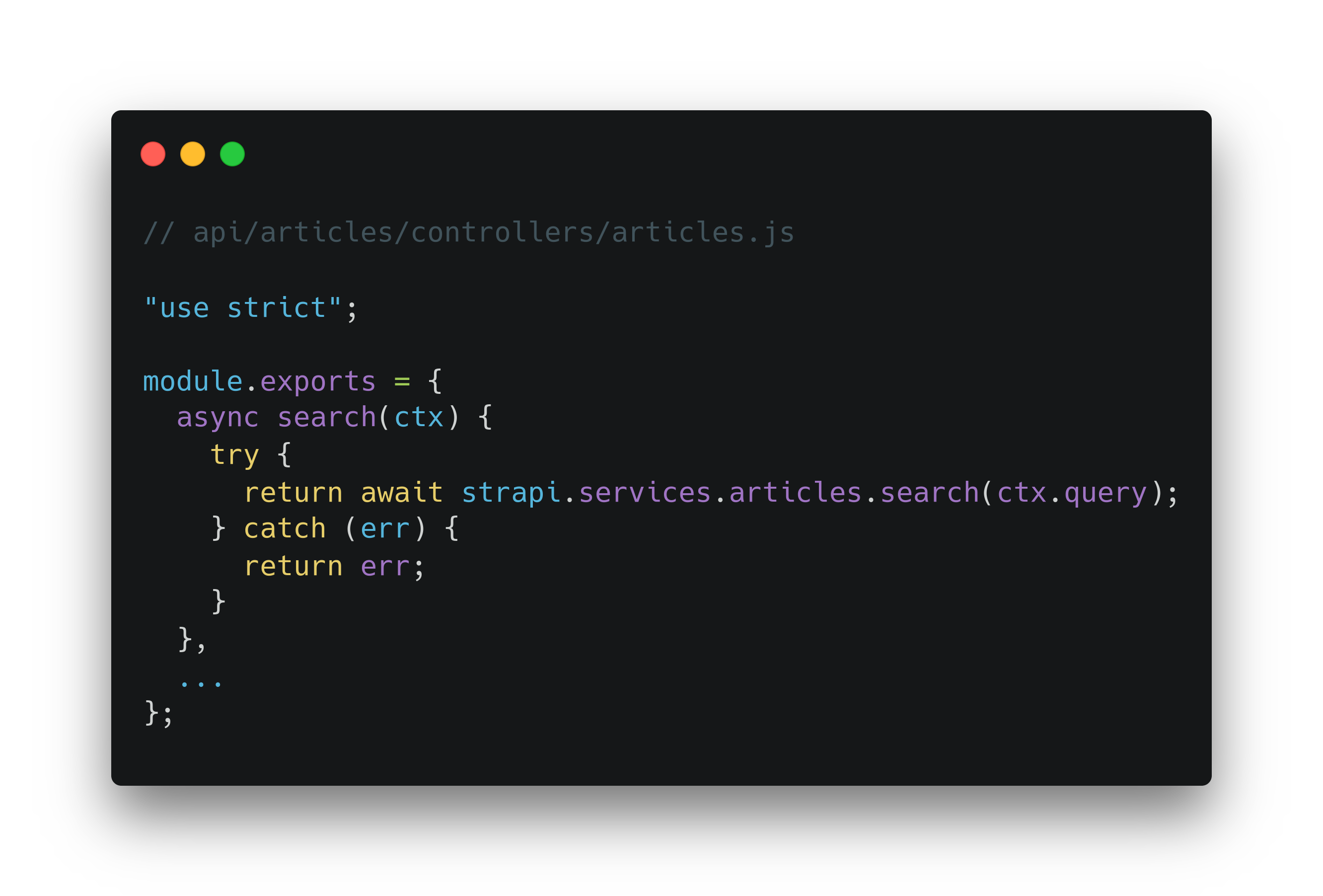
Конфигурация роутинга и контроллера готова. Осталось реализовать логику поиска в сервис elasticsearch. Для этого добавим метод search в файл services/articles.js:
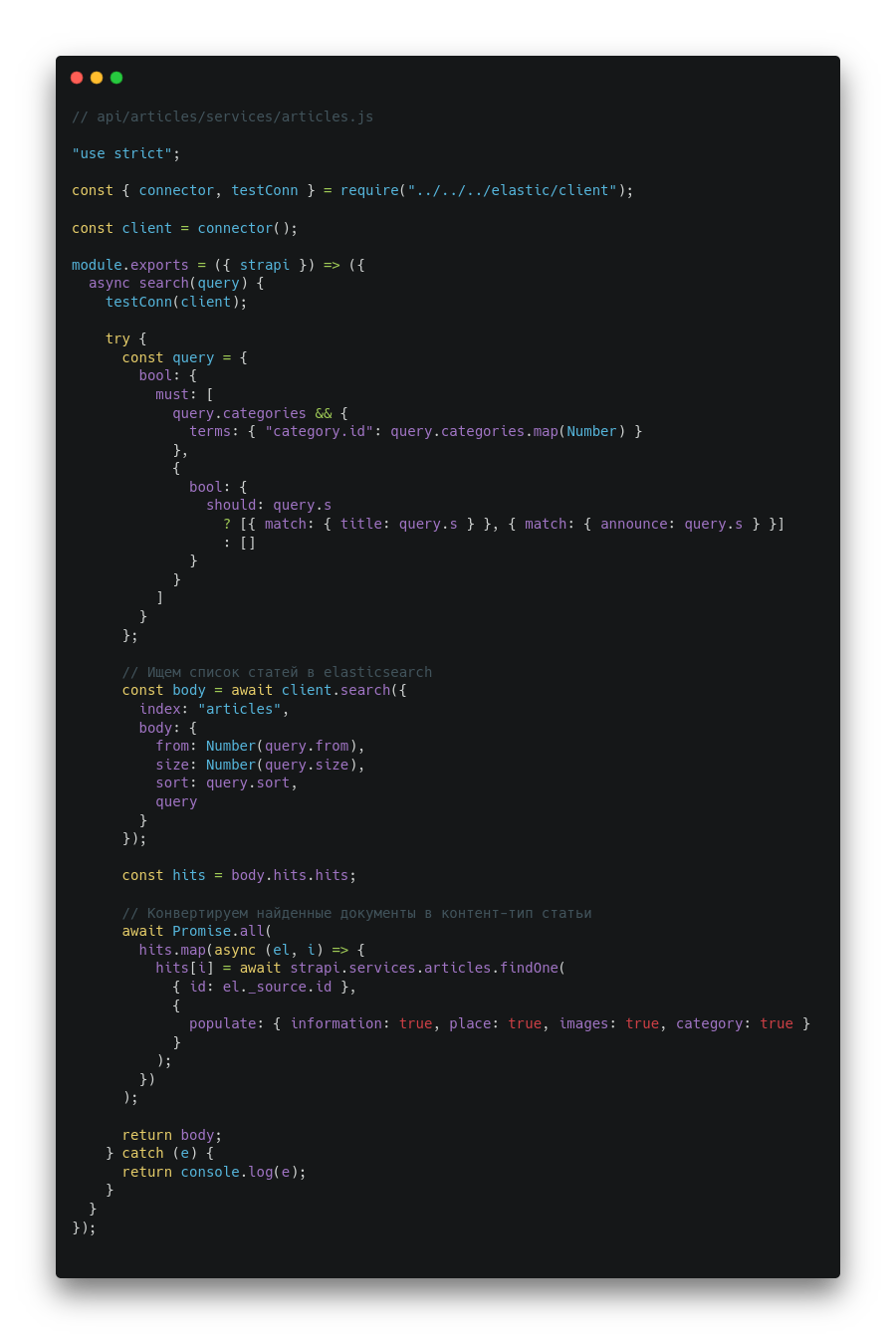
Все готово. Теперь для поиска статей можно обратиться к нашей контрольной точке /api/articles/search.
Интеграция с клиентом
Проиндексировали статьи для поиска через elasticsearch и добавили эндпоинт для поиска. Теперь можем приступать к интеграции контрольной точки в клиентском коде.
Интеграция заключается в вызове соответствующего эндпоинта с необходимым набором параметров. Вся логика поиска имплементирована на стороне сервера. Для клиентов же доступен прозрачный интерфейс запроса.
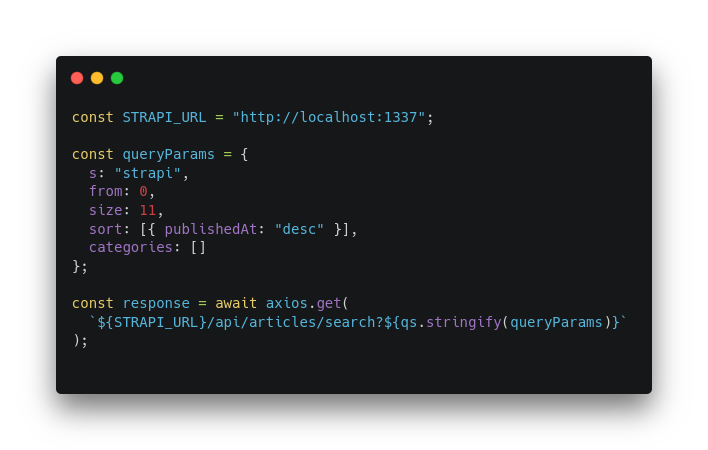
В примере выше реализовали базовый функционал поиска. Выделять совпадения и добавлять синонимы в этом примере не будем. Стоит понимать, что elasticsearch справляется и с этими функциями.
Сравнительная таблица решений
Возможности | Strapi | Meilisearch | Elasticsearch |
|---|---|---|---|
Распределенная работа | Нет | Нет | Да |
Простота интеграции со strapi | - | Да | Нет |
Простота синтаксиса запросов | Да | Да | Нет |
Ограничения в поисковых запросах | Написание сложных поисковых запросов будет затруднительно | Не более 10 слов в поисковом запросе | Нет |
Добавление синонимов | Нет | Да | Да |
Выделение совпадений | Нет | Да | Да |
Поиск неточных соответствий | Нет | Да | Да |
Ограничения индексации | - | Максимум 200 индексов. Не более 100 слов в одном поле | Нет |
Выбор оптимального решения
Рассмотрим, какой из трех способов реализации поиска подойдет под конкретные задачи:
1. Встроенный поиск. У strapi нет встроенных возможностей для реализации поиска. Strapi предоставляет гибкую систему фильтрации коллекций, но все привычные для пользователя функции: исправление опечатков, синонимы, выделение совпадений и т.п. не доступны. Их придется реализовывать самостоятельно. Поэтому встроенные возможности подойдут для реализации фильтрации данных даже со сложными и многоуровневыми условиями. Для функционала поиска необходимо привлекать сторонний сервис.
2. Meilisearch. Отлично подойдет для быстрого поиска по небольшому объему данных. Если же данные исчисляется в миллионах записей, или требуется распределенная поисковая система и сложные запросы, то meilisearch не подойдет. Также сервис не предоставит инструменты для статического анализа и визуализации данных.
Стоит отметить, что вышесказанное актуально для open-source версии сервиса, и не все ограничения справедливы для cloud - версии (с подпиской).
Также meilisearch прост в освоении. У него есть готовые плагины для интеграции со strapi v3 и v4. Реализация всех фичей из коробки доступна без дополнительной настройки. Все это в совокупности позволяет освоить этот инструмент быстро и, в связке со strapi, закрывать разработку проекта исключительно frontend-специалистами.
3. Elasticsearch. Если необходимо работать с Big Data, иметь возможность горизонтальной масштабируемости, сбора и визуализации данных или анализа сложных запросов — следует выбрать elasticsearch.
Однако стоит также понимать, что за все эти возможности придется дорого заплатить.
Первая проблема с которой придется столкнуться — это поиск специалиста. В случае связки strapi + elastic не получится обойтись только frontend-разработчиком.
Кроме проблем в разработке, также придется решать проблему разворота, настройки и безопасности. Elastic не предоставляет это из «коробки».
Elastic-стек — это очень гибкий, но в то же время сложный инструмент. Он подойдет для работы с большими данными. Также подойдет крупным компаниям, которые готовы платить за разработку и дальнейшую поддержку.
Заключение
В этой статье изучили базовые возможности strapi для организации поиска по данным. Также рассмотрели примеры интеграции со Strapi двух поисковых сервисов — Elasticsearch и Mailisearch, сравнили их между собой и определили, для каких целей следует использовать тот или иной инструмент. После прочтения статьи появляется базовое понимание того, как устроен поиск в strapi. Теперь, после полученных знаний, можно подобрать подходящий инструмент для решения поставленной задачи.


